IRRI-CIMMYT Crop Research Informatics Laboratory (CRIL), Centro Internacional de Mejoramiento de Máiz y Trigo (CIMMYT), Apdo. Postal 6-641, 06600 Mexico, D.F. , Mexico.
AoB Plants. 2010;2010:plq008. doi: 10.1093/aobpla/plq008. Epub 2010 May 27.
Agricultural crop databases maintained in gene banks of the Consultative Group on International Agricultural Research (CGIAR) are valuable sources of information for breeders. These databases provide comparative phenotypic and genotypic information that can help elucidate functional aspects of plant and agricultural biology. To facilitate data sharing within and between these databases and the retrieval of information, the crop ontology (CO) database was designed to provide controlled vocabulary sets for several economically important plant species.
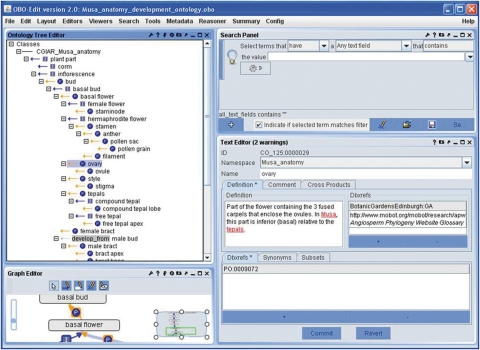
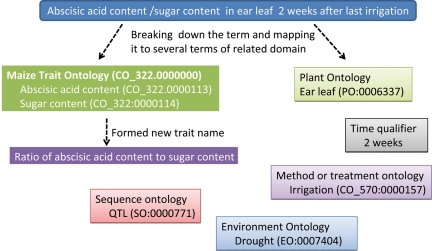
Existing public ontologies and equivalent catalogues of concepts covering the range of crop science information and descriptors for crops and crop-related traits were collected from breeders, physiologists, agronomists, and researchers in the CGIAR consortium. For each crop, relationships between terms were identified and crop-specific trait ontologies were constructed following the Open Biomedical Ontologies (OBO) format standard using the OBO-Edit tool. All terms within an ontology were assigned a globally unique CO term identifier.
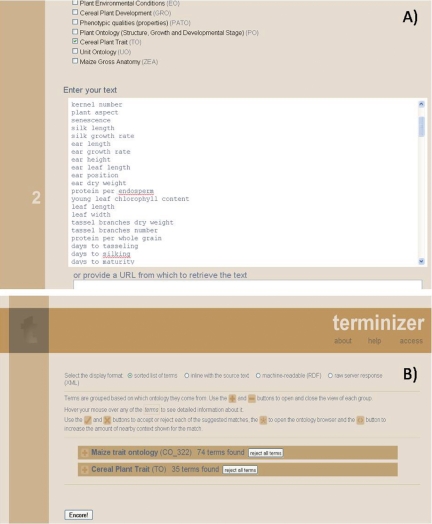
The CO currently comprises crop-specific traits for chickpea (Cicer arietinum), maize (Zea mays), potato (Solanum tuberosum), rice (Oryza sativa), sorghum (Sorghum spp.) and wheat (Triticum spp.). Several plant-structure and anatomy-related terms for banana (Musa spp.), wheat and maize are also included. In addition, multi-crop passport terms are included as controlled vocabularies for sharing information on germplasm. Two web-based online resources were built to make these COs available to the scientific community: the 'CO Lookup Service' for browsing the CO; and the 'Crops Terminizer', an ontology text mark-up tool.
The controlled vocabularies of the CO are being used to curate several CGIAR centres' agronomic databases. The use of ontology terms to describe agronomic phenotypes and the accurate mapping of these descriptions into databases will be important steps in comparative phenotypic and genotypic studies across species and gene-discovery experiments.
国际农业研究磋商组织(CGIAR)基因库中维护的农业作物数据库是育种者的宝贵信息来源。这些数据库提供了比较表型和基因型信息,可以帮助阐明植物和农业生物学的功能方面。为了促进这些数据库内部和之间的数据共享以及信息检索,设计了作物本体(CO)数据库,为几种经济上重要的植物物种提供了受控词汇集。
从育种者、生理学家、农学家和 CGIAR 联盟的研究人员那里收集了现有的公共本体和涵盖作物科学信息范围以及作物和与作物相关的性状描述符的等效目录概念。对于每种作物,确定了术语之间的关系,并按照开放生物医学本体(OBO)格式标准使用 OBO-Edit 工具构建了特定于作物的性状本体。本体中的所有术语都被分配了一个全局唯一的 CO 术语标识符。
目前 CO 包括鹰嘴豆(Cicer arietinum)、玉米(Zea mays)、马铃薯(Solanum tuberosum)、水稻(Oryza sativa)、高粱(Sorghum spp.)和小麦(Triticum spp.)的特定于作物的性状。香蕉(Musa spp.)、小麦和玉米的几个与植物结构和解剖相关的术语也包括在内。此外,还包括多作物护照术语作为种质信息共享的受控词汇。建立了两个基于网络的在线资源,以便向科学界提供这些 CO:用于浏览 CO 的“CO 查找服务”;以及本体文本标记工具“Crops Terminizer”。
CO 的受控词汇正在被用于整理几个 CGIAR 中心的农艺学数据库。使用本体术语来描述农艺学表型,以及将这些描述准确映射到数据库中,将是在物种间和基因发现实验中进行比较表型和基因型研究的重要步骤。