Division of Biomedical Informatics, University of California at San Diego, La Jolla, California 92093-0728, USA.
J Am Med Inform Assoc. 2012 Jun;19(e1):e137-44. doi: 10.1136/amiajnl-2011-000751. Epub 2012 Apr 4.
Competing tools are available online to assess the risk of developing certain conditions of interest, such as cardiovascular disease. While predictive models have been developed and validated on data from cohort studies, little attention has been paid to ensure the reliability of such predictions for individuals, which is critical for care decisions. The goal was to develop a patient-driven adaptive prediction technique to improve personalized risk estimation for clinical decision support.
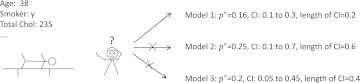
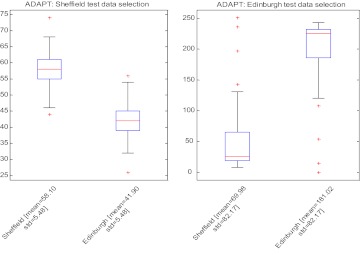
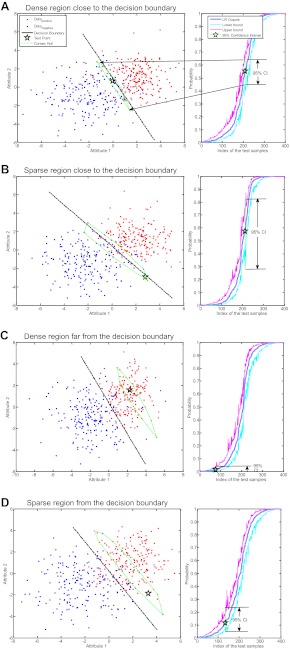
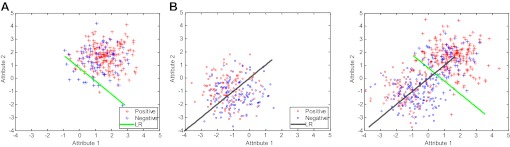
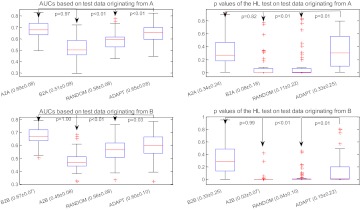
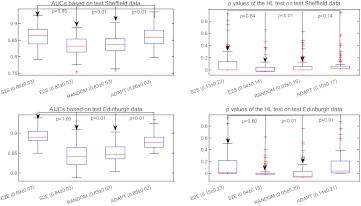
A data-driven approach was proposed that utilizes individualized confidence intervals (CIs) to select the most 'appropriate' model from a pool of candidates to assess the individual patient's clinical condition. The method does not require access to the training dataset. This approach was compared with other strategies: the BEST model (the ideal model, which can only be achieved by access to data or knowledge of which population is most similar to the individual), CROSS model, and RANDOM model selection.
When evaluated on clinical datasets, the approach significantly outperformed the CROSS model selection strategy in terms of discrimination (p<1e-14) and calibration (p<0.006). The method outperformed the RANDOM model selection strategy in terms of discrimination (p<1e-12), but the improvement did not achieve significance for calibration (p=0.1375).
The CI may not always offer enough information to rank the reliability of predictions, and this evaluation was done using aggregation. If a particular individual is very different from those represented in a training set of existing models, the CI may be somewhat misleading.
This approach has the potential to offer more reliable predictions than those offered by other heuristics for disease risk estimation of individual patients.
在线上有许多可用于评估某些感兴趣疾病风险的工具,如心血管疾病。虽然已经针对队列研究的数据开发和验证了预测模型,但很少关注如何确保此类预测对个体的可靠性,这对于决策至关重要。目的是开发一种患者驱动的自适应预测技术,以改善用于临床决策支持的个性化风险估计。
提出了一种数据驱动的方法,该方法利用个体化置信区间(CI)从候选模型中选择“最合适”的模型来评估个体患者的临床状况。该方法不需要访问训练数据集。该方法与其他策略进行了比较:BEST 模型(理想模型,只有访问数据或了解与个体最相似的人群才能实现)、CROSS 模型和 RANDOM 模型选择。
在临床数据集上进行评估时,该方法在区分度(p<1e-14)和校准(p<0.006)方面显著优于 CROSS 模型选择策略。该方法在区分度方面优于 RANDOM 模型选择策略(p<1e-12),但校准方面的改进没有达到显著水平(p=0.1375)。
CI 可能并不总是提供足够的信息来对预测的可靠性进行排序,并且此评估是使用聚合进行的。如果个体与现有模型的训练集中代表的个体非常不同,则 CI 可能会有些误导。
与其他疾病风险个体估计启发式方法相比,该方法有可能提供更可靠的预测。