Keygene N.V., Wageningen, The Netherlands.
PLoS One. 2012;7(5):e37565. doi: 10.1371/journal.pone.0037565. Epub 2012 May 25.
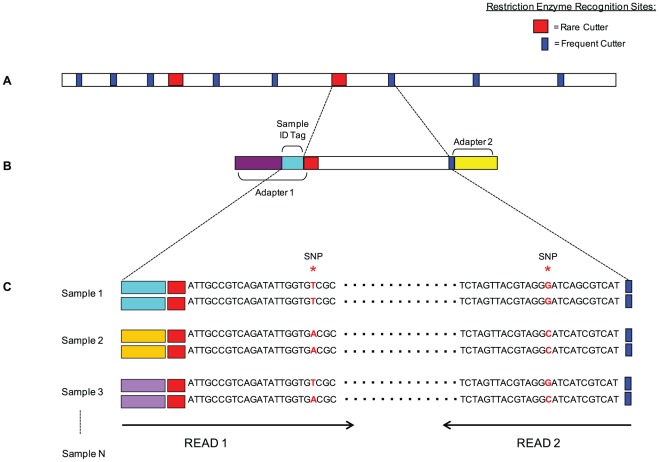
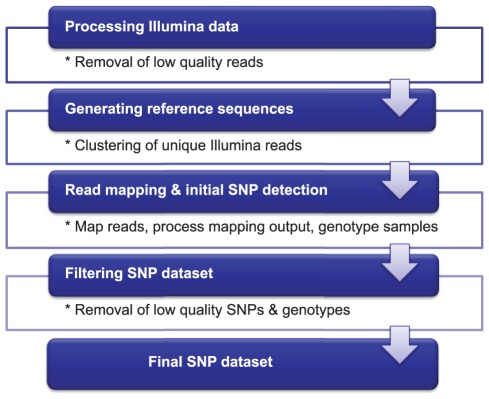
Conventional marker-based genotyping platforms are widely available, but not without their limitations. In this context, we developed Sequence-Based Genotyping (SBG), a technology for simultaneous marker discovery and co-dominant scoring, using next-generation sequencing. SBG offers users several advantages including a generic sample preparation method, a highly robust genome complexity reduction strategy to facilitate de novo marker discovery across entire genomes, and a uniform bioinformatics workflow strategy to achieve genotyping goals tailored to individual species, regardless of the availability of a reference sequence. The most distinguishing features of this technology are the ability to genotype any population structure, regardless whether parental data is included, and the ability to co-dominantly score SNP markers segregating in populations. To demonstrate the capabilities of SBG, we performed marker discovery and genotyping in Arabidopsis thaliana and lettuce, two plant species of diverse genetic complexity and backgrounds. Initially we obtained 1,409 SNPs for arabidopsis, and 5,583 SNPs for lettuce. Further filtering of the SNP dataset produced over 1,000 high quality SNP markers for each species. We obtained a genotyping rate of 201.2 genotypes/SNP and 58.3 genotypes/SNP for arabidopsis (n = 222 samples) and lettuce (n = 87 samples), respectively. Linkage mapping using these SNPs resulted in stable map configurations. We have therefore shown that the SBG approach presented provides users with the utmost flexibility in garnering high quality markers that can be directly used for genotyping and downstream applications. Until advances and costs will allow for routine whole-genome sequencing of populations, we expect that sequence-based genotyping technologies such as SBG will be essential for genotyping of model and non-model genomes alike.
传统的基于标记的基因分型平台已经广泛应用,但也存在一些局限性。在此背景下,我们开发了基于序列的基因分型(SBG)技术,该技术利用下一代测序技术实现了标记的同时发现和共显性评分。SBG 为用户提供了多个优势,包括通用的样品制备方法、高度稳健的基因组复杂度降低策略,以促进整个基因组中从头标记的发现,以及统一的生物信息学工作流程策略,以实现针对特定物种的基因分型目标,而无需参考序列。该技术最显著的特点是能够对任何群体结构进行基因分型,无论是否包含亲本数据,以及能够对群体中分离的 SNP 标记进行共显性评分。为了展示 SBG 的功能,我们在拟南芥和生菜这两种遗传复杂度和背景各异的植物物种中进行了标记发现和基因分型。最初,我们在拟南芥中获得了 1409 个 SNP,在生菜中获得了 5583 个 SNP。对 SNP 数据集进行进一步筛选,为每个物种生成了超过 1000 个高质量 SNP 标记。我们获得了拟南芥(n=222 个样本)和生菜(n=87 个样本)的每个 SNP 201.2 个和 58.3 个基因型的基因分型率。利用这些 SNP 进行连锁图谱构建,得到了稳定的图谱构型。因此,我们表明,所提出的 SBG 方法为用户提供了最大的灵活性,可以获得高质量的标记,这些标记可以直接用于基因分型和下游应用。在进展和成本允许对群体进行常规全基因组测序之前,我们预计,像 SBG 这样的基于序列的基因分型技术将成为对模型和非模型基因组进行基因分型的重要手段。