Plant Biotechnology, Department of Biology, ETH Zurich, Zurich, Switzerland.
Front Plant Sci. 2012 Jun 11;3:123. doi: 10.3389/fpls.2012.00123. eCollection 2012.
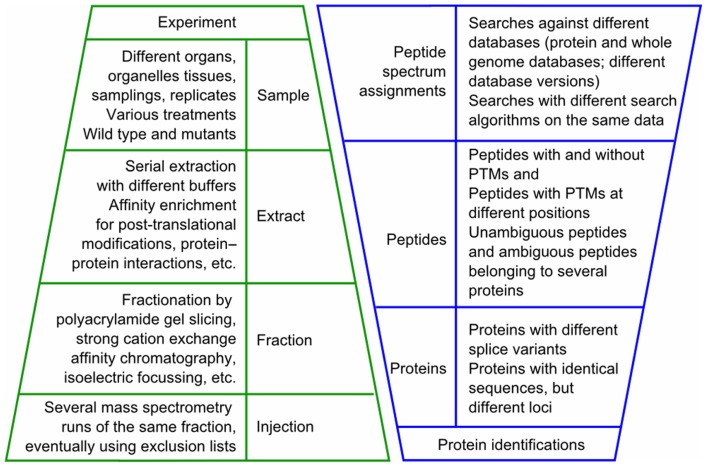
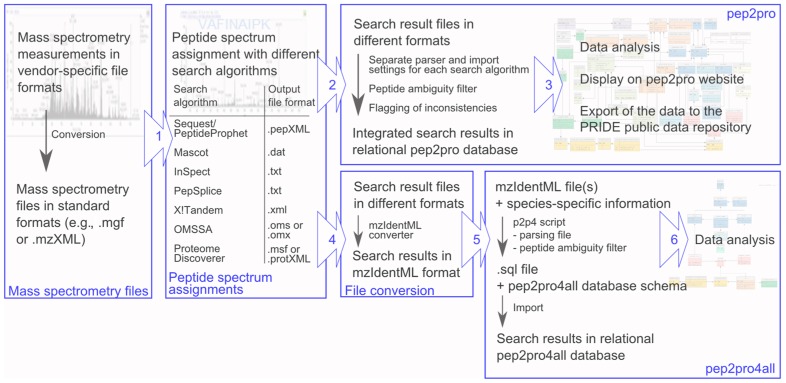
The pep2pro database was built to support effective high-throughput proteome data analysis. Its database schema allows the coherent integration of search results from different database-dependent search algorithms and filtering of the data including control for unambiguous assignment of peptides to proteins. The capacity of the pep2pro database has been exploited in data analysis of various Arabidopsis proteome datasets. The diversity of the datasets and the associated scientific questions required thorough querying of the data. This was supported by the relational format structure of the data that links all information on the sample, spectrum, search database, and algorithm to peptide and protein identifications and their post-translational modifications. After publication of datasets they are made available on the pep2pro website at www.pep2pro.ethz.ch. Further, the pep2pro data analysis pipeline also handles data export do the PRIDE database (http://www.ebi.ac.uk/pride) and data retrieval by the MASCP Gator (http://gator.masc-proteomics.org/). The utility of pep2pro will continue to be used for analysis of additional datasets and as a data warehouse. The capacity of the pep2pro database for proteome data analysis has now also been made publicly available through the release of pep2pro4all, which consists of a database schema and a script that will populate the database with mass spectrometry data provided in mzIdentML format.
pep2pro 数据库的建立是为了支持有效的高通量蛋白质组数据的分析。其数据库模式允许从不同的数据库相关搜索算法的搜索结果进行连贯的整合,并对数据进行过滤,包括控制肽段到蛋白质的明确分配。 pep2pro 数据库的容量已被用于各种拟南芥蛋白质组数据集的数据分析。数据集的多样性和相关的科学问题需要对数据进行彻底的查询。这得到了数据的关系格式结构的支持,该结构将关于样品、谱、搜索数据库和算法的所有信息与肽和蛋白质的鉴定及其翻译后修饰联系起来。数据集发布后,它们将在 pep2pro 网站上提供,网址为:www.pep2pro.ethz.ch。此外,pep2pro 数据分析管道还处理数据导出到 PRIDE 数据库(http://www.ebi.ac.uk/pride)和 MASCP Gator(http://gator.masc-proteomics.org/)的数据检索。pep2pro 将继续用于分析更多的数据集,并作为一个数据仓库。pep2pro 数据库的蛋白质组数据分析能力也通过 pep2pro4all 的发布而公开,该数据库包含一个数据库模式和一个脚本,该脚本将以 mzIdentML 格式提供的质谱数据填充数据库。