Wu Xi, Li Peng, Wang Nan, Gong Ping, Perkins Edward J, Deng Youping, Zhang Chaoyang
School of Computing, University of Southern Mississippi, Hattiesburg, MS 39406, USA.
BMC Syst Biol. 2011;5 Suppl 3(Suppl 3):S3. doi: 10.1186/1752-0509-5-S3-S3. Epub 2011 Dec 23.
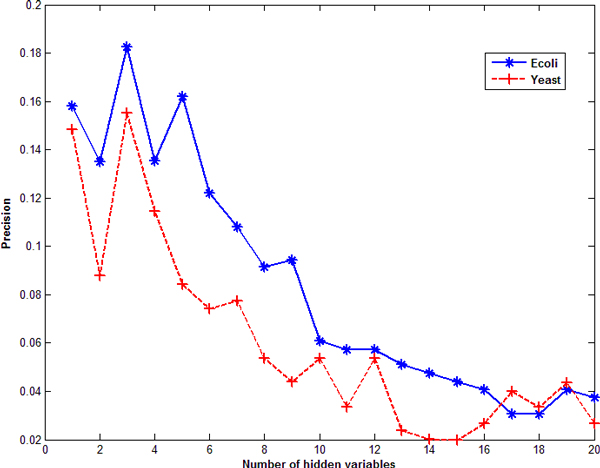
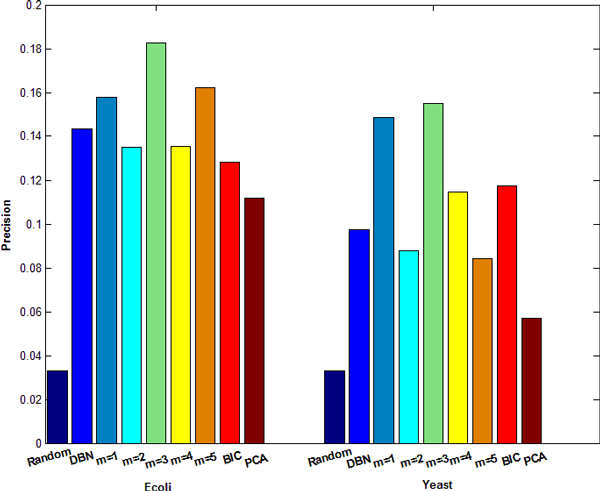
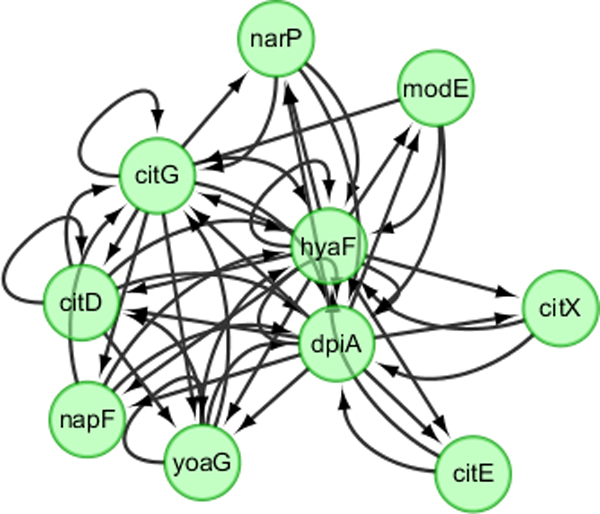
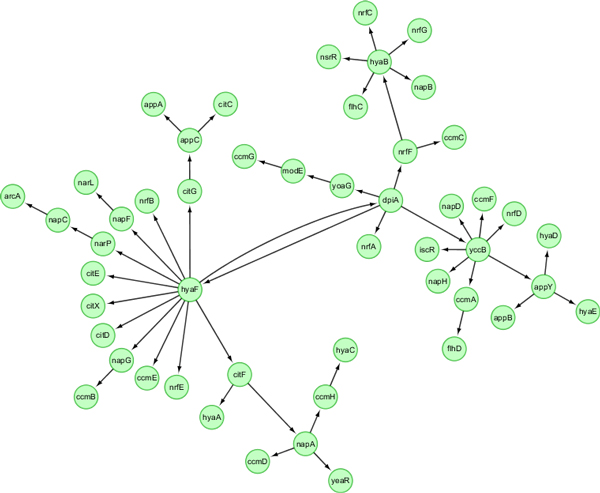
State Space Model (SSM) is a relatively new approach to inferring gene regulatory networks. It requires less computational time than Dynamic Bayesian Networks (DBN). There are two types of variables in the linear SSM, observed variables and hidden variables. SSM uses an iterative method, namely Expectation-Maximization, to infer regulatory relationships from microarray datasets. The hidden variables cannot be directly observed from experiments. How to determine the number of hidden variables has a significant impact on the accuracy of network inference. In this study, we used SSM to infer Gene regulatory networks (GRNs) from synthetic time series datasets, investigated Bayesian Information Criterion (BIC) and Principle Component Analysis (PCA) approaches to determining the number of hidden variables in SSM, and evaluated the performance of SSM in comparison with DBN.
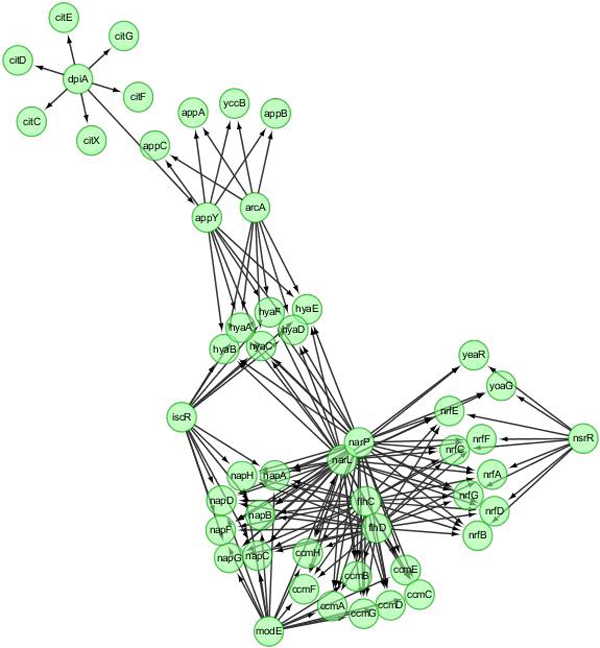
True GRNs and synthetic gene expression datasets were generated using GeneNetWeaver. Both DBN and linear SSM were used to infer GRNs from the synthetic datasets. The inferred networks were compared with the true networks.
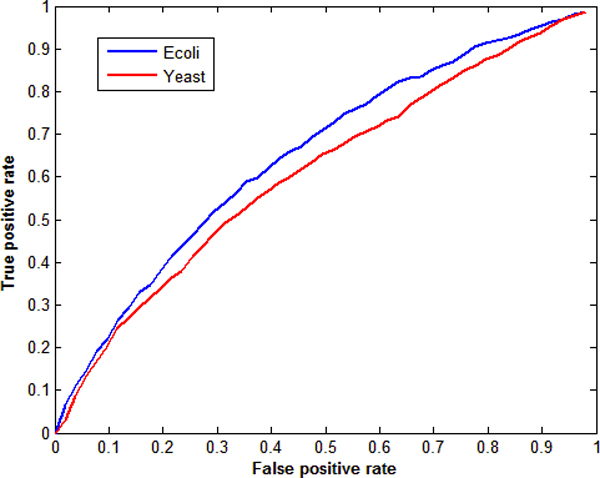
Our results show that inference precision varied with the number of hidden variables. For some regulatory networks, the inference precision of DBN was higher but SSM performed better in other cases. Although the overall performance of the two approaches is compatible, SSM is much faster and capable of inferring much larger networks than DBN.
This study provides useful information in handling the hidden variables and improving the inference precision.
状态空间模型(SSM)是一种推断基因调控网络的相对较新的方法。它比动态贝叶斯网络(DBN)所需的计算时间更少。线性SSM中有两种类型的变量,即观测变量和隐藏变量。SSM使用一种迭代方法,即期望最大化,从微阵列数据集中推断调控关系。隐藏变量无法从实验中直接观测到。如何确定隐藏变量的数量对网络推断的准确性有重大影响。在本研究中,我们使用SSM从合成时间序列数据集中推断基因调控网络(GRN),研究了贝叶斯信息准则(BIC)和主成分分析(PCA)方法来确定SSM中隐藏变量的数量,并与DBN比较评估了SSM的性能。
使用GeneNetWeaver生成真实的GRN和合成基因表达数据集。DBN和线性SSM都用于从合成数据集中推断GRN。将推断出的网络与真实网络进行比较。
我们的结果表明,推断精度随隐藏变量的数量而变化。对于一些调控网络,DBN的推断精度较高,但在其他情况下SSM表现更好。虽然这两种方法的总体性能相当,但SSM比DBN快得多,并且能够推断出大得多的网络。
本研究为处理隐藏变量和提高推断精度提供了有用信息。