Department of Psychiatry and Psychotherapy, RWTH Aachen University, Aachen, Germany.
PLoS One. 2012;7(7):e41531. doi: 10.1371/journal.pone.0041531. Epub 2012 Jul 23.
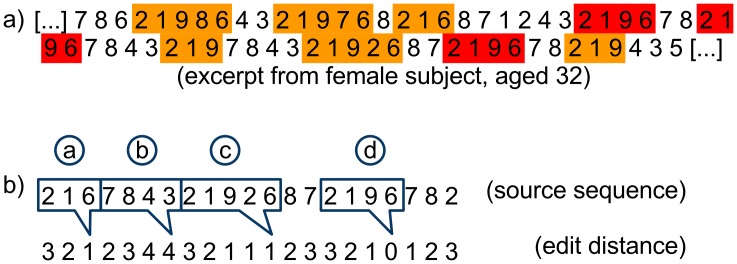
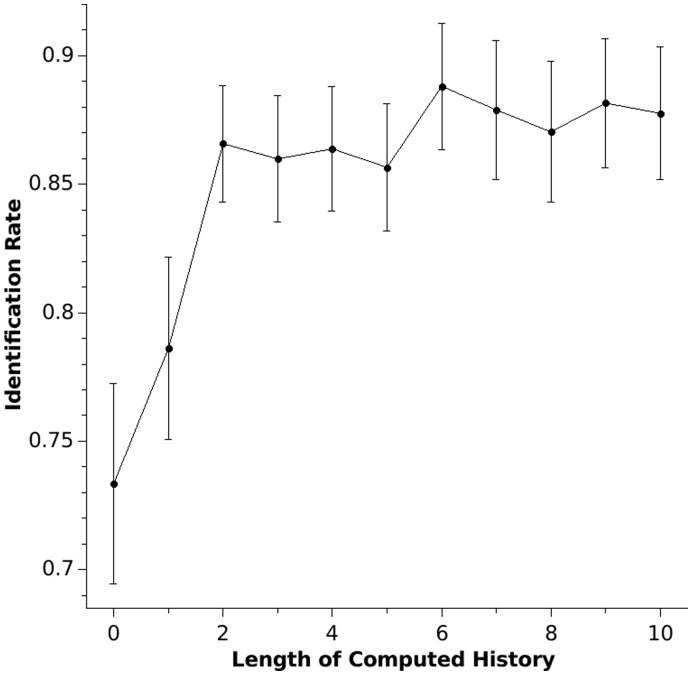
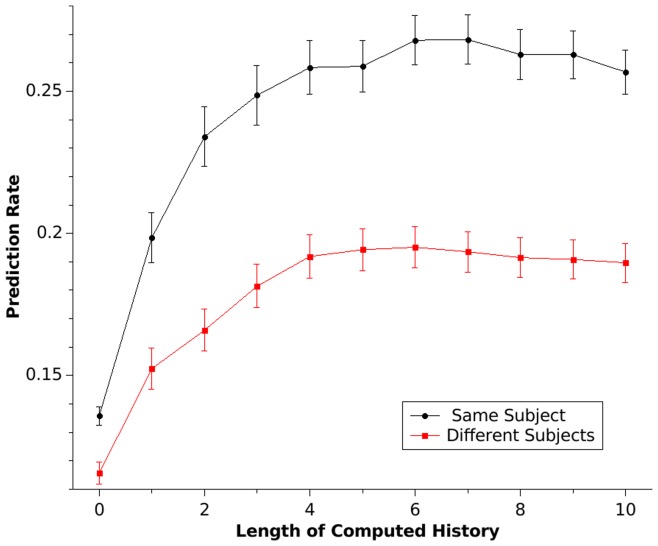
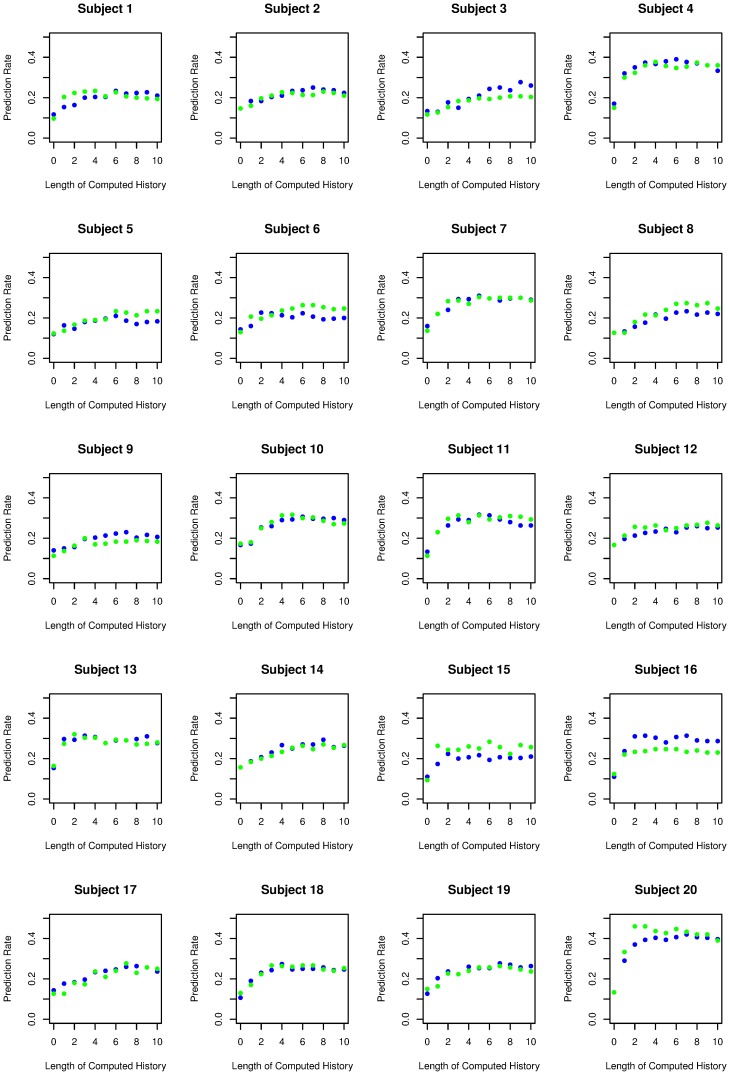
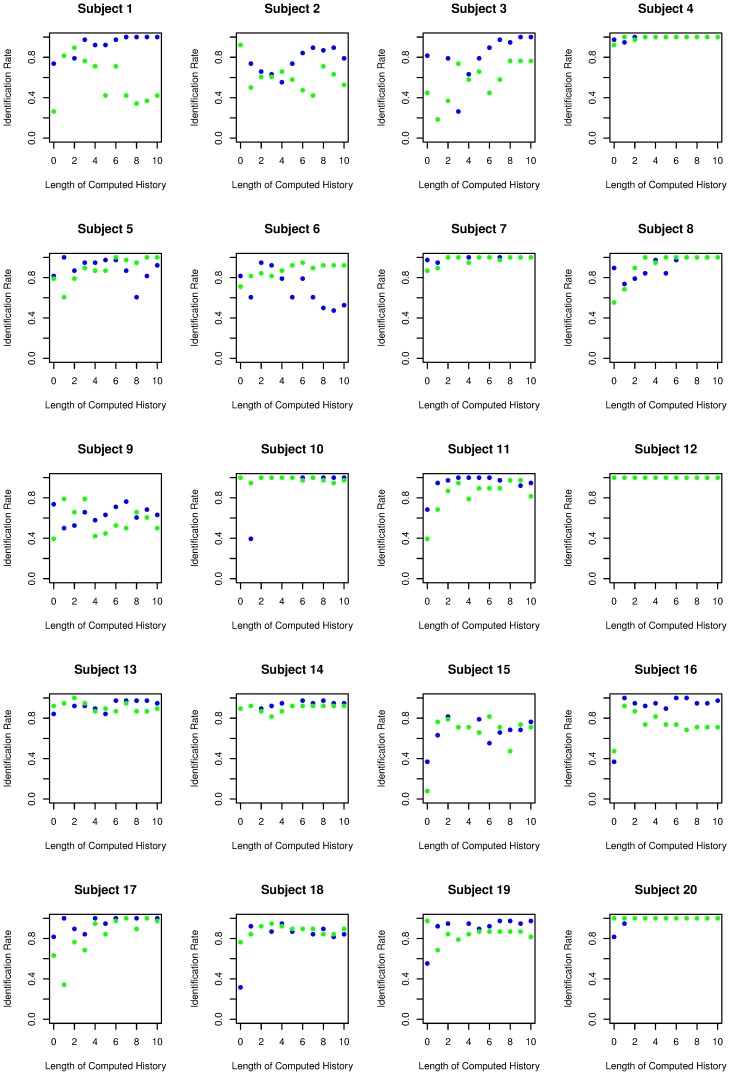
In a random number generation task, participants are asked to generate a random sequence of numbers, most typically the digits 1 to 9. Such number sequences are not mathematically random, and both extent and type of bias allow one to characterize the brain's "internal random number generator". We assume that certain patterns and their variations will frequently occur in humanly generated random number sequences. Thus, we introduce a pattern-based analysis of random number sequences. Twenty healthy subjects randomly generated two sequences of 300 numbers each. Sequences were analysed to identify the patterns of numbers predominantly used by the subjects and to calculate the frequency of a specific pattern and its variations within the number sequence. This pattern analysis is based on the Damerau-Levenshtein distance, which counts the number of edit operations that are needed to convert one string into another. We built a model that predicts not only the next item in a humanly generated random number sequence based on the item's immediate history, but also the deployment of patterns in another sequence generated by the same subject. When a history of seven items was computed, the mean correct prediction rate rose up to 27% (with an individual maximum of 46%, chance performance of 11%). Furthermore, we assumed that when predicting one subject's sequence, predictions based on statistical information from the same subject should yield a higher success rate than predictions based on statistical information from a different subject. When provided with two sequences from the same subject and one from a different subject, an algorithm identifies the foreign sequence in up to 88% of the cases. In conclusion, the pattern-based analysis using the Levenshtein-Damarau distance is both able to predict humanly generated random number sequences and to identify person-specific information within a humanly generated random number sequence.
在随机数生成任务中,要求参与者生成一个随机数字序列,最常见的是数字 1 到 9。这样的数字序列不是数学上的随机数,其扩展和类型的偏差可以用来描述大脑的“内部随机数生成器”。我们假设在人类生成的随机数序列中会频繁出现某些模式及其变体。因此,我们引入了一种基于模式的随机数序列分析方法。二十名健康受试者随机生成了两个各包含 300 个数字的序列。对序列进行分析,以确定受试者主要使用的数字模式,并计算特定模式及其变体在数字序列中的频率。这种模式分析基于 Damerau-Levenshtein 距离,它计算将一个字符串转换为另一个字符串所需的编辑操作数。我们构建了一个模型,不仅可以根据数字序列中当前项的历史来预测人类生成的随机数序列中的下一个项,还可以预测同一受试者生成的另一个序列中的模式部署。当计算七个项的历史时,平均正确预测率上升到 27%(个体最高达到 46%,机会预测为 11%)。此外,我们假设在预测一个受试者的序列时,基于同一受试者的统计信息的预测应该比基于不同受试者的统计信息的预测具有更高的成功率。当提供来自同一受试者的两个序列和一个来自不同受试者的序列时,算法可以在高达 88%的情况下识别出外来序列。总之,使用 Levenshtein-Damarau 距离的基于模式的分析不仅能够预测人类生成的随机数序列,还能够识别人类生成的随机数序列中的特定于人的信息。