Division of Biomedical Informatics, Cincinnati Children's Hospital Medical Center, Cincinnati, OH 45229-3039, USA.
J Am Med Inform Assoc. 2013 Jan 1;20(1):84-94. doi: 10.1136/amiajnl-2012-001012. Epub 2012 Aug 2.
(1) To evaluate a state-of-the-art natural language processing (NLP)-based approach to automatically de-identify a large set of diverse clinical notes. (2) To measure the impact of de-identification on the performance of information extraction algorithms on the de-identified documents.
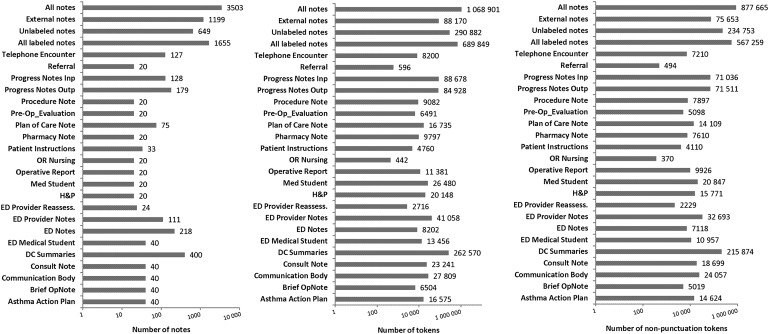
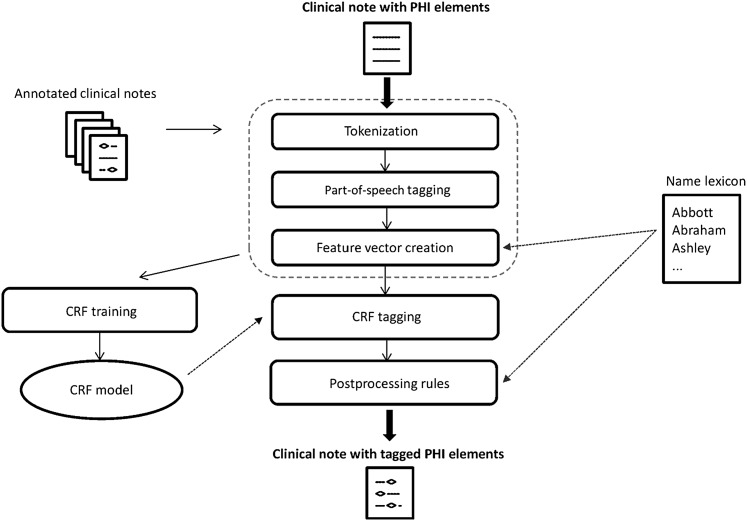
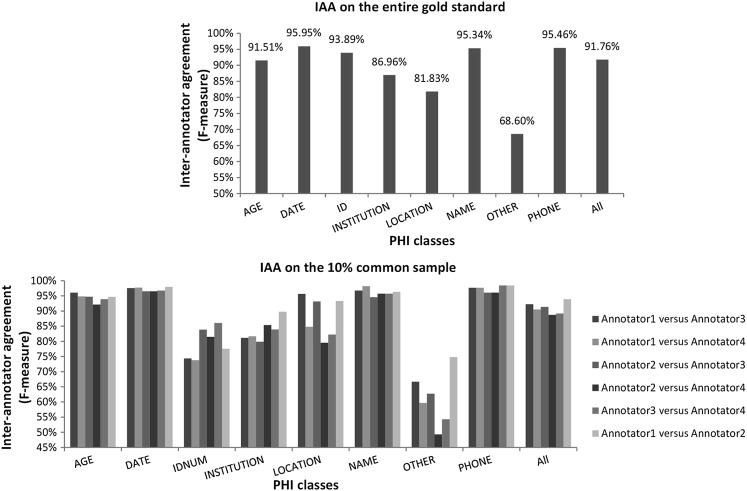
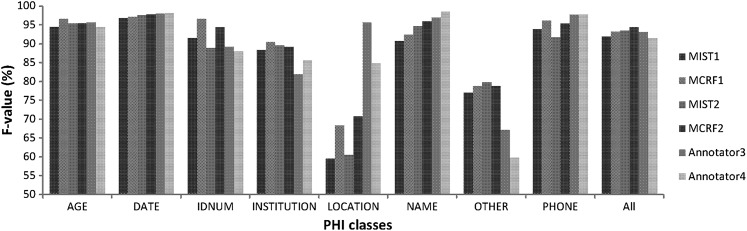
A cross-sectional study that included 3503 stratified, randomly selected clinical notes (over 22 note types) from five million documents produced at one of the largest US pediatric hospitals. Sensitivity, precision, F value of two automated de-identification systems for removing all 18 HIPAA-defined protected health information elements were computed. Performance was assessed against a manually generated 'gold standard'. Statistical significance was tested. The automated de-identification performance was also compared with that of two humans on a 10% subsample of the gold standard. The effect of de-identification on the performance of subsequent medication extraction was measured.
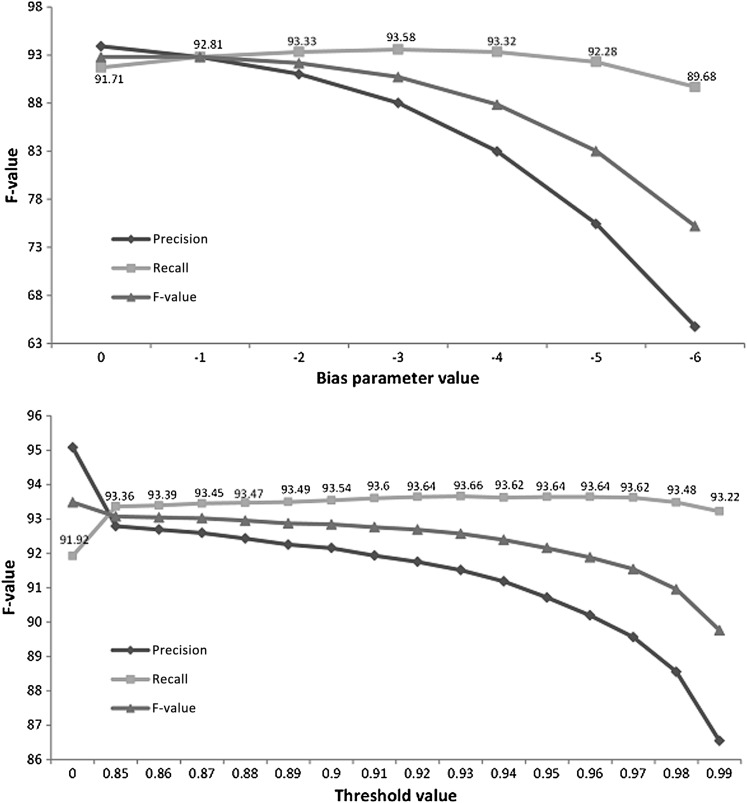
The gold standard included 30 815 protected health information elements and more than one million tokens. The most accurate NLP method had 91.92% sensitivity (R) and 95.08% precision (P) overall. The performance of the system was indistinguishable from that of human annotators (annotators' performance was 92.15%(R)/93.95%(P) and 94.55%(R)/88.45%(P) overall while the best system obtained 92.91%(R)/95.73%(P) on same text). The impact of automated de-identification was minimal on the utility of the narrative notes for subsequent information extraction as measured by the sensitivity and precision of medication name extraction.
NLP-based de-identification shows excellent performance that rivals the performance of human annotators. Furthermore, unlike manual de-identification, the automated approach scales up to millions of documents quickly and inexpensively.
(1)评估一种最先进的自然语言处理(NLP)方法,以自动识别大量多样化的临床记录。(2)衡量去识别对信息提取算法在去识别文档上的性能的影响。
这是一项横断面研究,纳入了来自美国最大的儿科医院之一的五百万份文件中随机选择的 3503 份分层临床记录(超过 22 种记录类型)。计算了两种自动去识别系统去除所有 18 个 HIPAA 定义的受保护健康信息元素的所有敏感性、精度和 F 值。使用手动生成的“黄金标准”进行评估。测试了统计学意义。还将自动化去识别性能与黄金标准的 10%子样本上的两名人类进行了比较。测量了去识别对随后药物提取性能的影响。
黄金标准包括 30815 个受保护健康信息元素和超过一百万个标记。最准确的 NLP 方法的整体敏感性(R)为 91.92%,精度(P)为 95.08%。系统的性能与人工注释器的性能无法区分(注释器的性能总体上为 92.15%(R)/93.95%(P)和 94.55%(R)/88.45%(P),而最佳系统在相同文本上获得 92.91%(R)/95.73%(P))。自动去识别对叙事记录后续信息提取的实用性的影响很小,这可以通过药物名称提取的敏感性和精度来衡量。
基于 NLP 的去识别表现出卓越的性能,可与人工注释器的性能相媲美。此外,与手动去识别不同,自动化方法可以快速、经济地扩展到数百万份文件。