Human Genetics, David Geffen School of Medicine, University of California, Los Angeles, California, USA.
BMC Bioinformatics. 2013 Jan 16;14:5. doi: 10.1186/1471-2105-14-5.
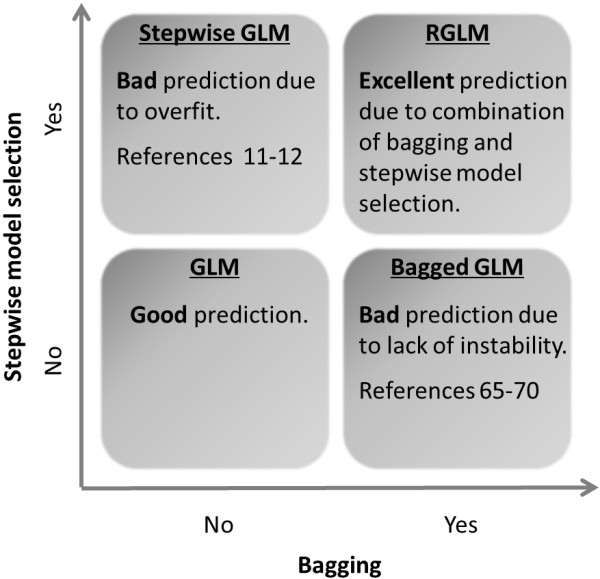
Ensemble predictors such as the random forest are known to have superior accuracy but their black-box predictions are difficult to interpret. In contrast, a generalized linear model (GLM) is very interpretable especially when forward feature selection is used to construct the model. However, forward feature selection tends to overfit the data and leads to low predictive accuracy. Therefore, it remains an important research goal to combine the advantages of ensemble predictors (high accuracy) with the advantages of forward regression modeling (interpretability). To address this goal several articles have explored GLM based ensemble predictors. Since limited evaluations suggested that these ensemble predictors were less accurate than alternative predictors, they have found little attention in the literature.
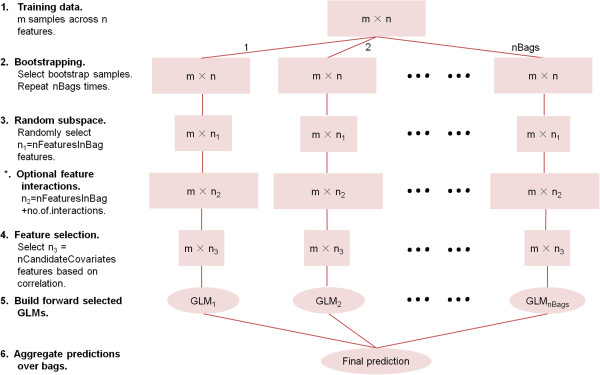
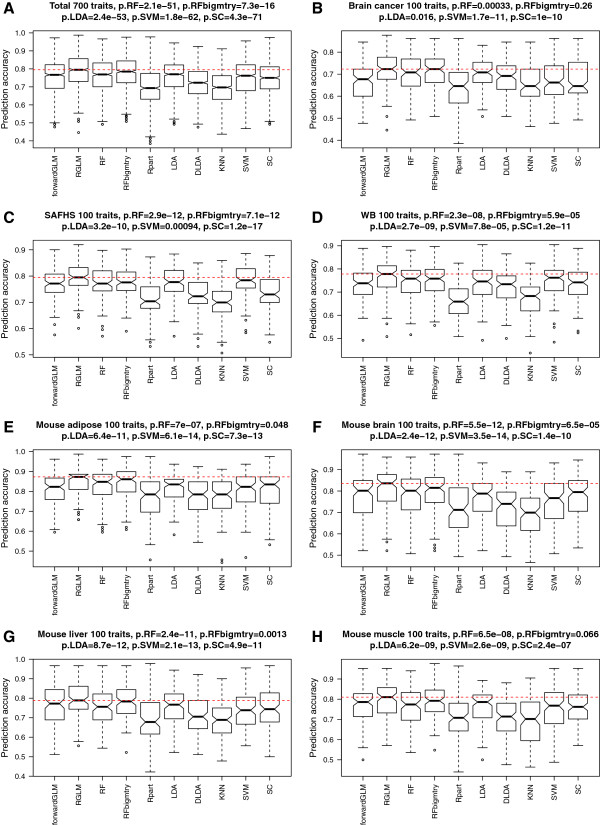
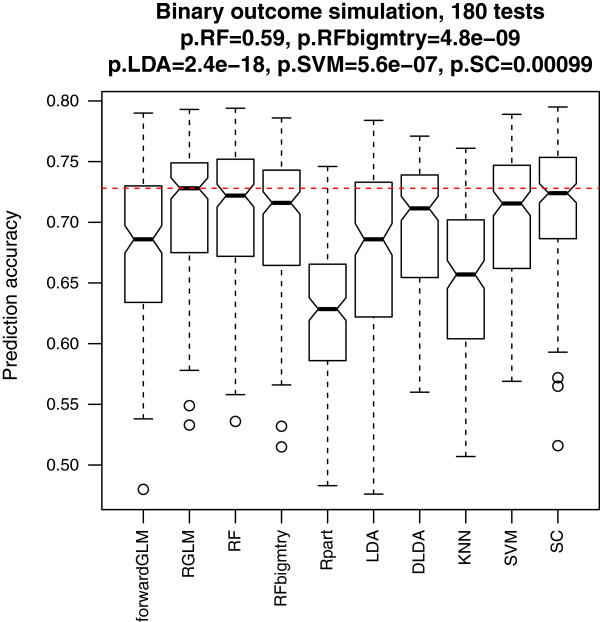
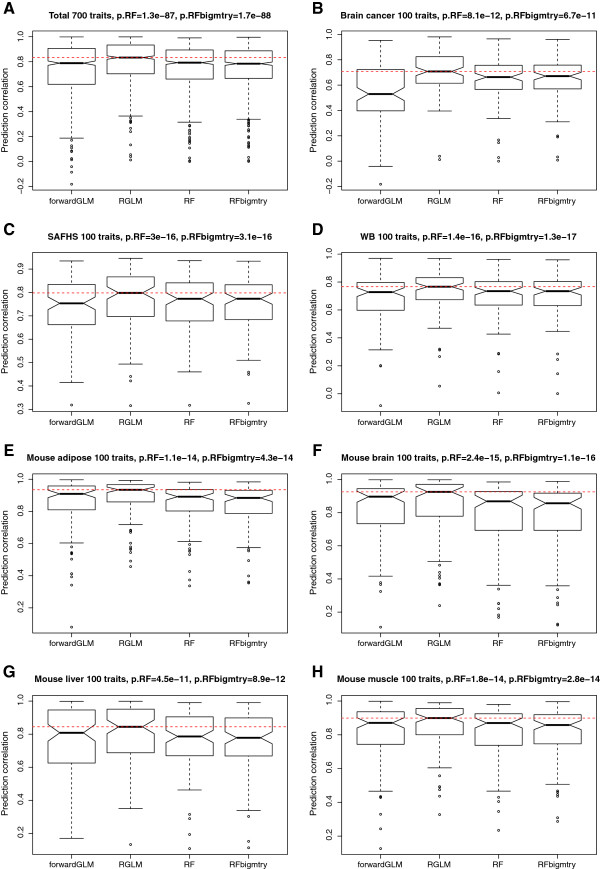
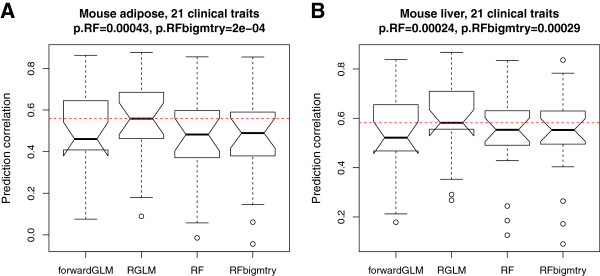
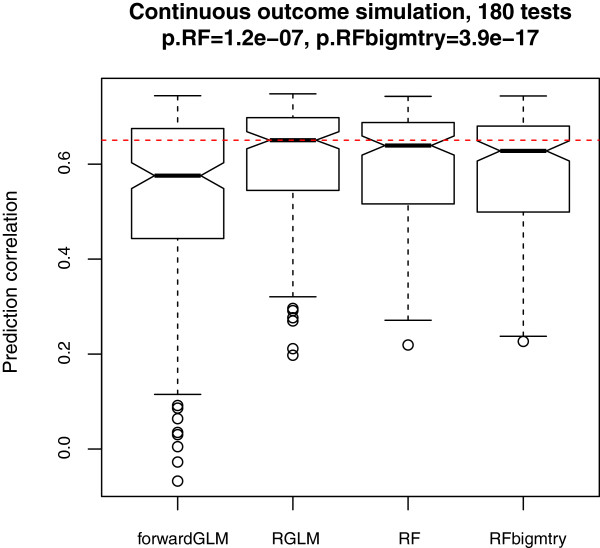
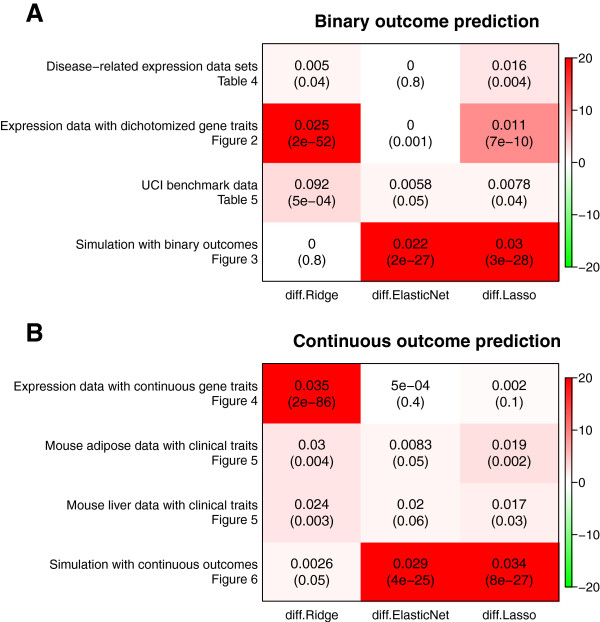
Comprehensive evaluations involving hundreds of genomic data sets, the UCI machine learning benchmark data, and simulations are used to give GLM based ensemble predictors a new and careful look. A novel bootstrap aggregated (bagged) GLM predictor that incorporates several elements of randomness and instability (random subspace method, optional interaction terms, forward variable selection) often outperforms a host of alternative prediction methods including random forests and penalized regression models (ridge regression, elastic net, lasso). This random generalized linear model (RGLM) predictor provides variable importance measures that can be used to define a "thinned" ensemble predictor (involving few features) that retains excellent predictive accuracy.
RGLM is a state of the art predictor that shares the advantages of a random forest (excellent predictive accuracy, feature importance measures, out-of-bag estimates of accuracy) with those of a forward selected generalized linear model (interpretability). These methods are implemented in the freely available R software package randomGLM.
集成预测器(如随机森林)以其准确性高而著称,但它们的黑盒预测结果难以解释。相比之下,广义线性模型(GLM)非常具有解释性,尤其是在使用前向特征选择构建模型时。然而,前向特征选择往往会过度拟合数据,导致预测精度较低。因此,如何结合集成预测器(高准确性)和前向回归建模(可解释性)的优势仍然是一个重要的研究目标。为了实现这一目标,已经有一些文章探索了基于 GLM 的集成预测器。由于有限的评估表明这些集成预测器的准确性不如其他预测器,因此它们在文献中并没有受到太多关注。
通过综合评估涉及数百个基因组数据集、UCI 机器学习基准数据集和模拟数据的方法,重新审视了基于 GLM 的集成预测器。一种新的基于 bootstrap 集成(bagging)的 GLM 预测器,该预测器结合了一些随机性和不稳定性的元素(随机子空间方法、可选交互项、前向变量选择),通常优于许多替代预测方法,包括随机森林和惩罚回归模型(岭回归、弹性网络、lasso)。这种随机广义线性模型(RGLM)预测器提供了可用于定义“稀疏”集成预测器(涉及少数特征)的变量重要性度量,该预测器保留了出色的预测准确性。
RGLM 是一种先进的预测器,它结合了随机森林(出色的预测准确性、特征重要性度量、袋外估计的准确性)的优势,以及前向选择的广义线性模型(可解释性)的优势。这些方法在免费提供的 R 软件包 randomGLM 中实现。