CAS Key Laboratory of Genome Sciences and Information, Beijing Institute of Genomics, Chinese Academy of Sciences, Beijing 100101, China.
Genomics Proteomics Bioinformatics. 2013 Feb;11(1):41-55. doi: 10.1016/j.gpb.2013.01.001. Epub 2013 Jan 20.
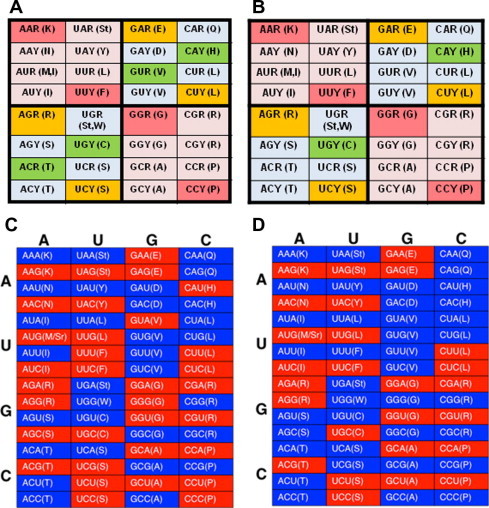
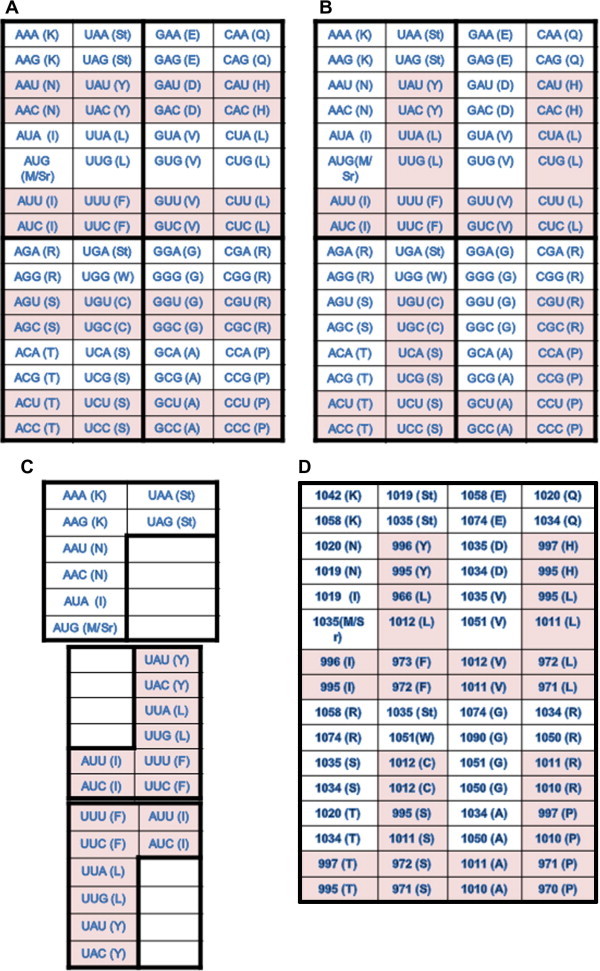
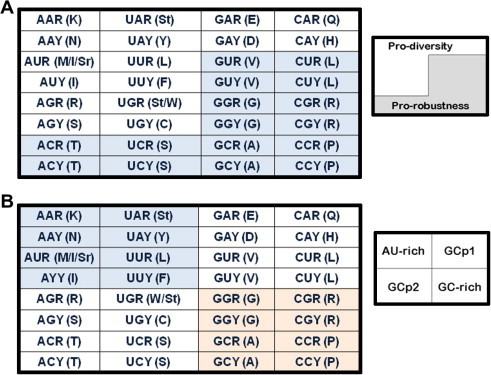
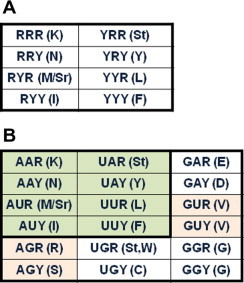
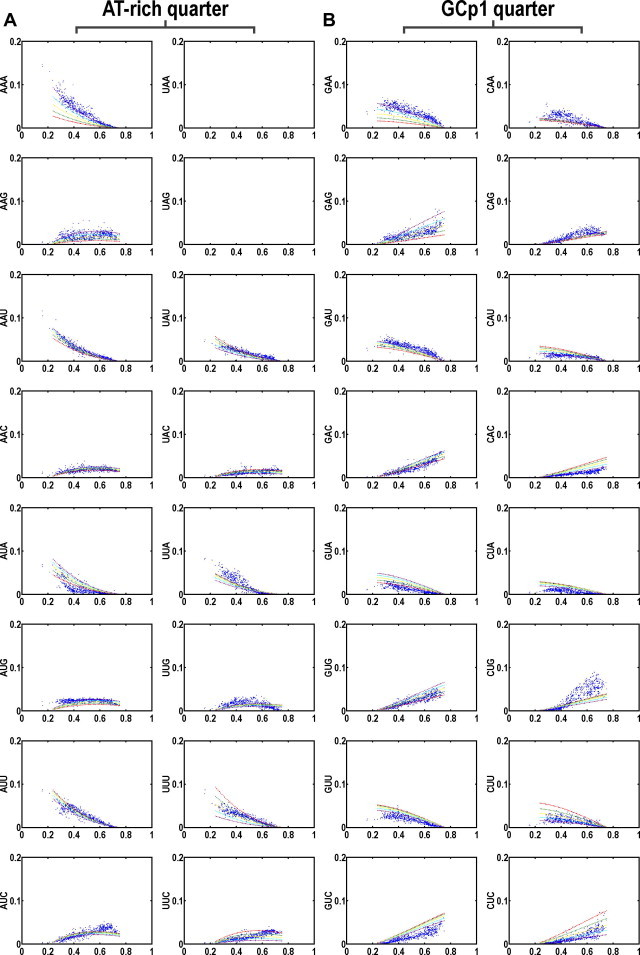
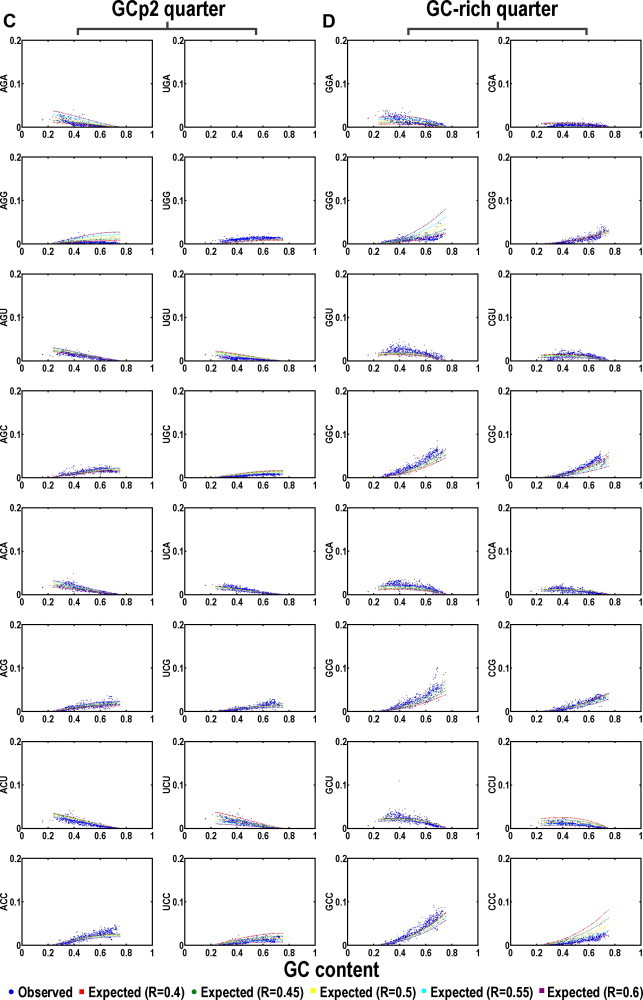
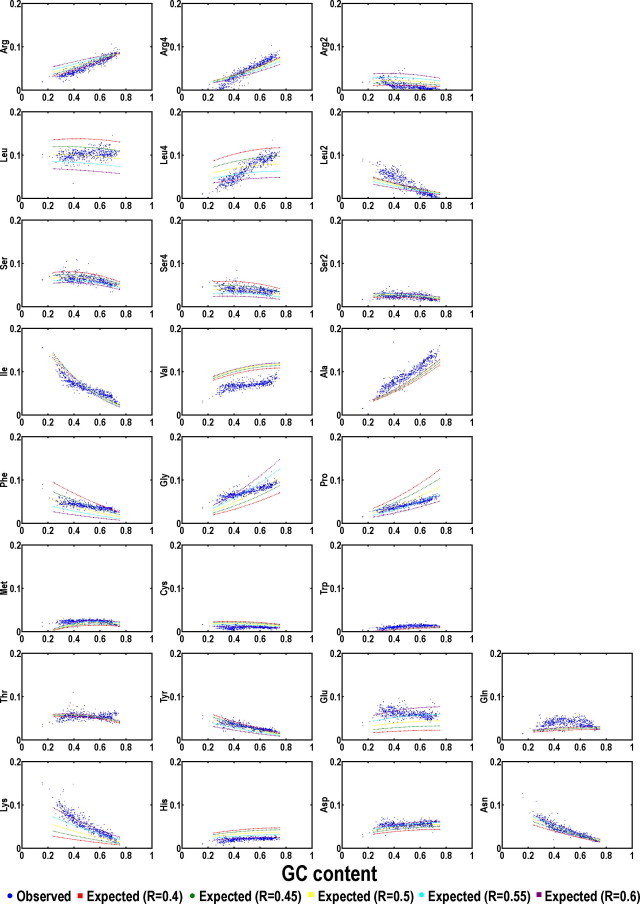
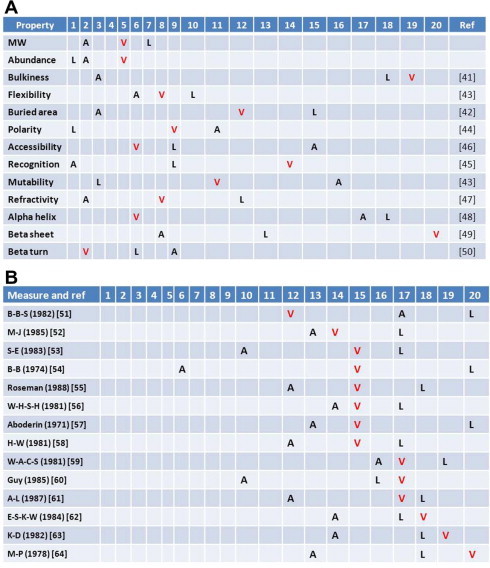
In the RNA world, RNA is assumed to be the dominant macromolecule performing most, if not all, core "house-keeping" functions. The ribo-cell hypothesis suggests that the genetic code and the translation machinery may both be born of the RNA world, and the introduction of DNA to ribo-cells may take over the informational role of RNA gradually, such as a mature set of genetic code and mechanism enabling stable inheritance of sequence and its variation. In this context, we modeled the genetic code in two content variables-GC and purine contents-of protein-coding sequences and measured the purine content sensitivities for each codon when the sensitivity (% usage) is plotted as a function of GC content variation. The analysis leads to a new pattern-the symmetric pattern-where the sensitivity of purine content variation shows diagonally symmetry in the codon table more significantly in the two GC content invariable quarters in addition to the two existing patterns where the table is divided into either four GC content sensitivity quarters or two amino acid diversity halves. The most insensitive codon sets are GUN (valine) and CAN (CAR for asparagine and CAY for aspartic acid) and the most biased amino acid is valine (always over-estimated) followed by alanine (always under-estimated). The unique position of valine and its codons suggests its key roles in the final recruitment of the complete codon set of the canonical table. The distinct choice may only be attributable to sequence signatures or signals of splice sites for spliceosomal introns shared by all extant eukaryotes.
在 RNA 世界中,假设 RNA 是执行大多数(如果不是全部)核心“管家”功能的主要大分子。核细胞假说表明,遗传密码和翻译机制可能都起源于 RNA 世界,而 DNA 向核细胞的引入可能逐渐接管 RNA 的信息作用,例如成熟的遗传密码和机制能够稳定地遗传序列及其变化。在这种情况下,我们在两个内容变量(GC 和嘌呤含量)中对蛋白质编码序列的遗传密码进行建模,并测量每个密码子的嘌呤含量敏感性,当敏感性(%使用频率)作为 GC 含量变化的函数绘制时。分析得出了一种新的模式——对称模式——除了现有的将表分为四个 GC 含量敏感区或两个氨基酸多样性半区的两种模式外,嘌呤含量变化的敏感性在 GC 含量不变的两个四分之一区中以密码子表的对角线对称方式更显著。最不敏感的密码子组是 GUN(缬氨酸)和 CAN(天冬酰胺的 CAR 和天冬氨酸的 CAY),最偏性的氨基酸是缬氨酸(总是高估),其次是丙氨酸(总是低估)。缬氨酸及其密码子的独特位置表明它在最终招募完整的规范表密码子集方面起着关键作用。这种独特的选择可能归因于所有现存真核生物共享的剪接体内含子的剪接位点的序列特征或信号。