National Centre for Biological Sciences, Tata Institute of Fundamental Research, Bangalore, Karnataka, India.
PLoS One. 2013;8(2):e56449. doi: 10.1371/journal.pone.0056449. Epub 2013 Feb 20.
Development of sensitive sequence search procedures for the detection of distant relationships between proteins at superfamily/fold level is still a big challenge. The intermediate sequence search approach is the most frequently employed manner of identifying remote homologues effectively. In this study, examination of serine proteases of prolyl oligopeptidase, rhomboid and subtilisin protein families were carried out using plant serine proteases as queries from two genomes including A. thaliana and O. sativa and 13 other families of unrelated folds to identify the distant homologues which could not be obtained using PSI-BLAST.
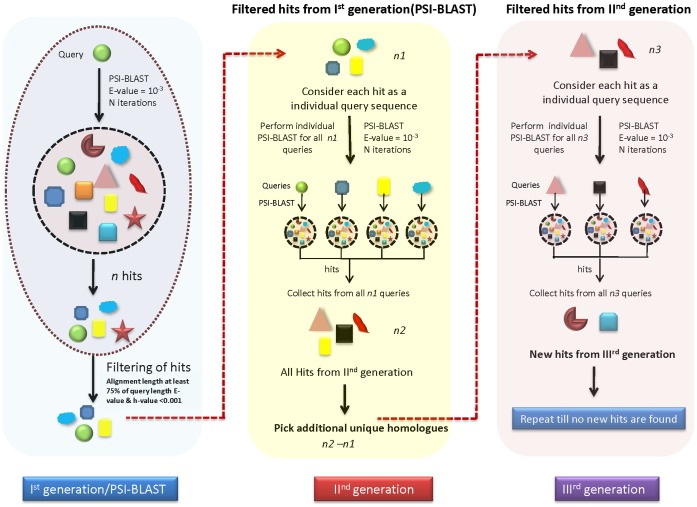
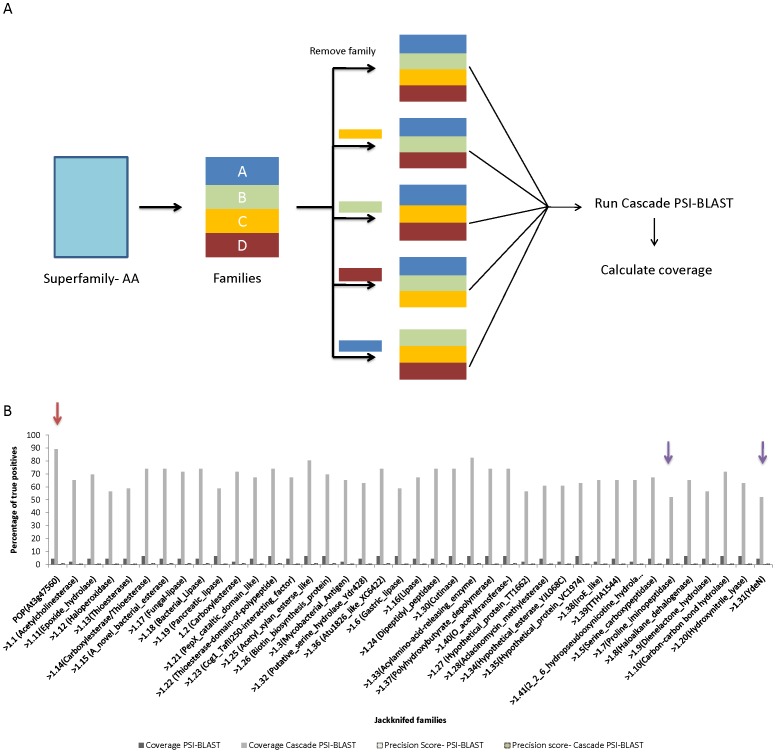
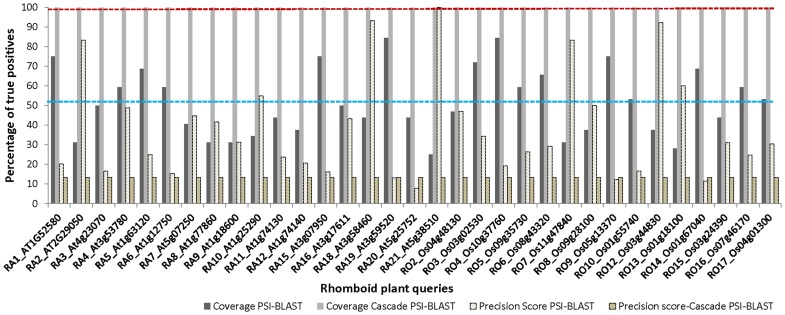
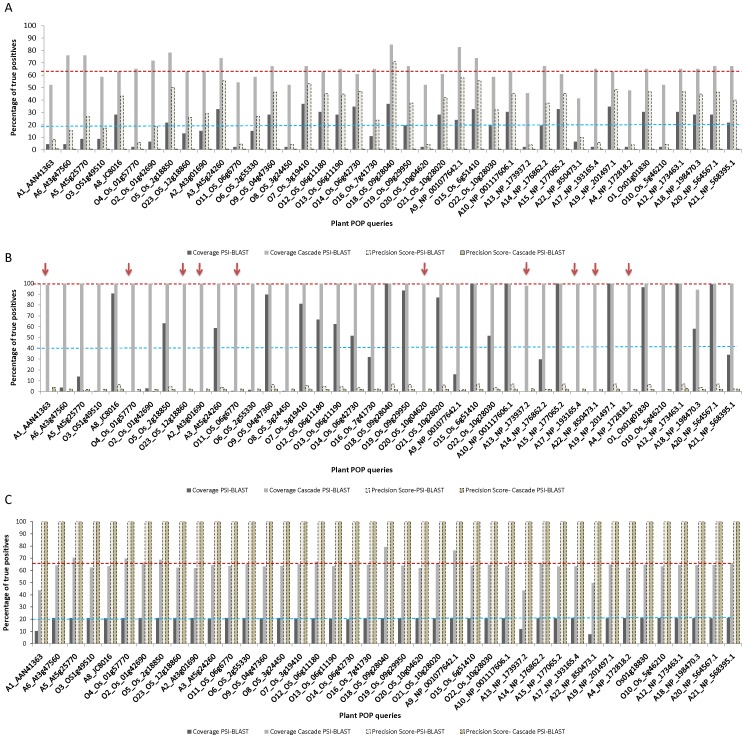
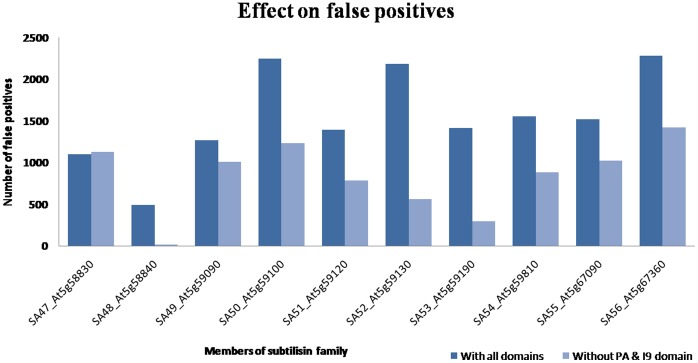
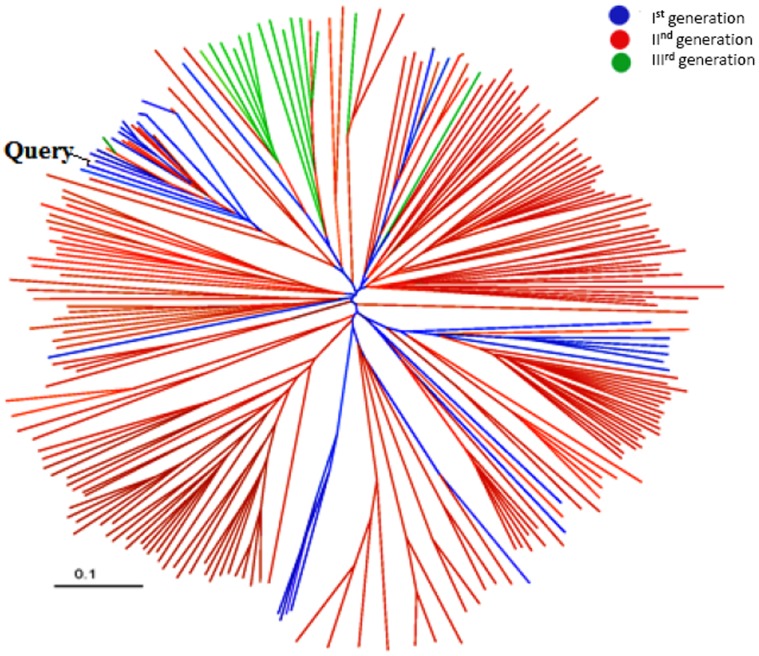
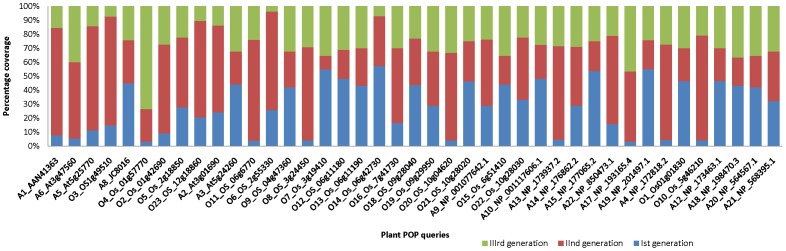
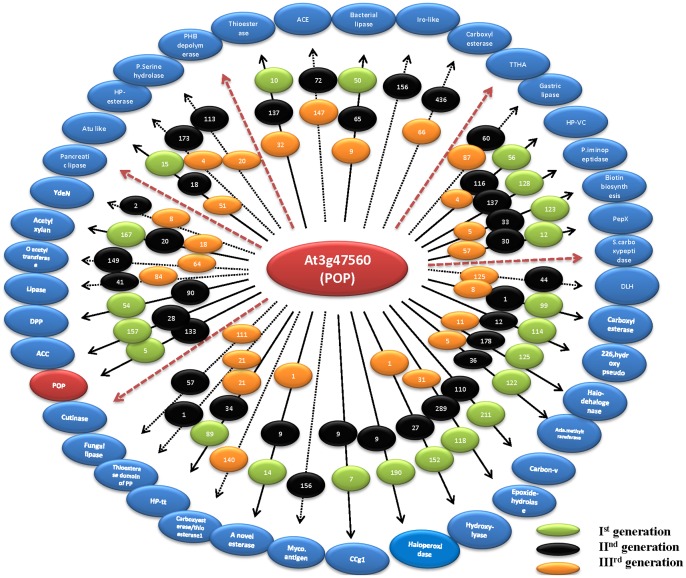
METHODOLOGY/PRINCIPAL FINDINGS: We have proposed to start with multiple queries of classical serine protease members to identify remote homologues in families, using a rigorous approach like Cascade PSI-BLAST. We found that classical sequence based approaches, like PSI-BLAST, showed very low sequence coverage in identifying plant serine proteases. The algorithm was applied on enriched sequence database of homologous domains and we obtained overall average coverage of 88% at family, 77% at superfamily or fold level along with specificity of ~100% and Mathew's correlation coefficient of 0.91. Similar approach was also implemented on 13 other protein families representing every structural class in SCOP database. Further investigation with statistical tests, like jackknifing, helped us to better understand the influence of neighbouring protein families.
CONCLUSIONS/SIGNIFICANCE: Our study suggests that employment of multiple queries of a family for the Cascade PSI-BLAST searches is useful for predicting distant relationships effectively even at superfamily level. We have proposed a generalized strategy to cover all the distant members of a particular family using multiple query sequences. Our findings reveal that prior selection of sequences as query and the presence of neighbouring families can be important for covering the search space effectively in minimal computational time. This study also provides an understanding of the 'bridging' role of related families.
开发用于检测蛋白质超家族/折叠水平之间远距离关系的敏感序列搜索程序仍然是一个巨大的挑战。中间序列搜索方法是最常采用的有效识别远程同源物的方法。在这项研究中,我们使用来自拟南芥和水稻两个基因组的植物丝氨酸蛋白酶作为查询,对脯氨酰寡肽酶、类蛋白和枯草杆菌蛋白酶家族的丝氨酸蛋白酶进行了检查,并对 13 个其他不相关折叠家族进行了检查,以识别无法使用 PSI-BLAST 获得的远程同源物。
方法/主要发现:我们建议使用严格的方法(如级联 PSI-BLAST),从多个经典丝氨酸蛋白酶成员的查询开始,在家族中识别远程同源物。我们发现,经典的基于序列的方法,如 PSI-BLAST,在识别植物丝氨酸蛋白酶时显示出非常低的序列覆盖率。该算法应用于同源结构域的富集序列数据库,我们在家族水平获得了 88%的总体平均覆盖率,在超家族或折叠水平的覆盖率为 77%,特异性约为 100%,马修相关系数为 0.91。我们还对 SCOP 数据库中代表每一个结构类的 13 个其他蛋白质家族实施了类似的方法。使用像 Jackknifing 这样的统计测试的进一步调查,帮助我们更好地理解邻近蛋白质家族的影响。
结论/意义:我们的研究表明,对于级联 PSI-BLAST 搜索,使用家族的多个查询进行查询是有效的,即使在超家族水平也可以有效地预测远距离关系。我们提出了一种通用策略,使用多个查询序列来覆盖特定家族的所有远程成员。我们的发现表明,序列的预先选择作为查询以及邻近家族的存在对于在最小计算时间内有效地覆盖搜索空间是很重要的。这项研究还提供了对相关家族的“桥梁”作用的理解。