Systems and Modeling Unit, Montefiore Institute, University of Liège, 4000 Liège, Belgium.
BMC Bioinformatics. 2013 Apr 24;14:138. doi: 10.1186/1471-2105-14-138.
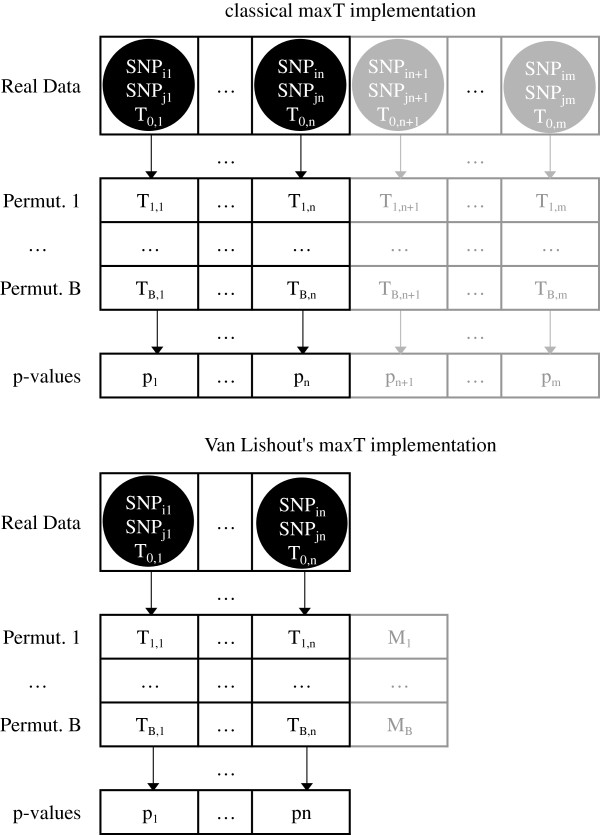
Research in epistasis or gene-gene interaction detection for human complex traits has grown over the last few years. It has been marked by promising methodological developments, improved translation efforts of statistical epistasis to biological epistasis and attempts to integrate different omics information sources into the epistasis screening to enhance power. The quest for gene-gene interactions poses severe multiple-testing problems. In this context, the maxT algorithm is one technique to control the false-positive rate. However, the memory needed by this algorithm rises linearly with the amount of hypothesis tests. Gene-gene interaction studies will require a memory proportional to the squared number of SNPs. A genome-wide epistasis search would therefore require terabytes of memory. Hence, cache problems are likely to occur, increasing the computation time. In this work we present a new version of maxT, requiring an amount of memory independent from the number of genetic effects to be investigated. This algorithm was implemented in C++ in our epistasis screening software MBMDR-3.0.3. We evaluate the new implementation in terms of memory efficiency and speed using simulated data. The software is illustrated on real-life data for Crohn's disease.
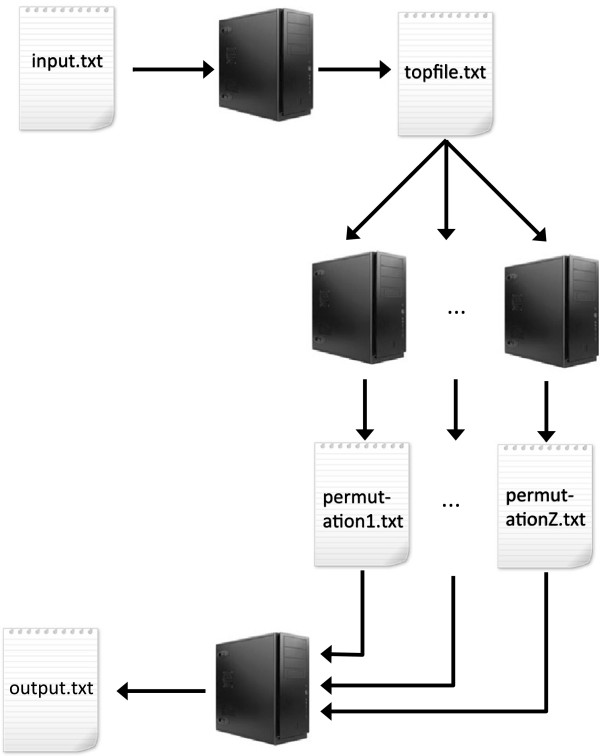
In the case of a binary (affected/unaffected) trait, the parallel workflow of MBMDR-3.0.3 analyzes all gene-gene interactions with a dataset of 100,000 SNPs typed on 1000 individuals within 4 days and 9 hours, using 999 permutations of the trait to assess statistical significance, on a cluster composed of 10 blades, containing each four Quad-Core AMD Opteron(tm) Processor 2352 2.1 GHz. In the case of a continuous trait, a similar run takes 9 days. Our program found 14 SNP-SNP interactions with a multiple-testing corrected p-value of less than 0.05 on real-life Crohn's disease (CD) data.
Our software is the first implementation of the MB-MDR methodology able to solve large-scale SNP-SNP interactions problems within a few days, without using much memory, while adequately controlling the type I error rates. A new implementation to reach genome-wide epistasis screening is under construction. In the context of Crohn's disease, MBMDR-3.0.3 could identify epistasis involving regions that are well known in the field and could be explained from a biological point of view. This demonstrates the power of our software to find relevant phenotype-genotype higher-order associations.
近年来,人类复杂性状的基因-基因互作检测研究取得了长足的发展。这一领域的发展特点是方法学的不断改进,统计互作向生物互作的转化取得了进展,以及试图将不同的组学信息源整合到互作筛选中以提高效能。对基因-基因互作的研究带来了严重的多重检验问题。在这种情况下,maxT 算法是控制假阳性率的一种技术。然而,该算法所需的内存与假设检验的数量呈线性关系。基因-基因互作研究所需的内存与 SNP 数量的平方成正比。因此,全基因组互作搜索需要 terabytes 的内存。因此,很可能会出现缓存问题,从而增加计算时间。在这项工作中,我们提出了一种新的 maxT 版本,该算法所需的内存与要研究的遗传效应数量无关。该算法已在我们的互作筛选软件 MBMDR-3.0.3 中用 C++实现。我们使用模拟数据评估新实现的内存效率和速度。该软件在克罗恩病的真实数据上得到了说明。
在二元(患病/未患病)性状的情况下,MBMDR-3.0.3 的并行工作流程使用 1000 个个体的 100000 个 SNP 数据集,在包含四个四核 AMD Opteron(tm) Processor 2352 2.1GHz 的 10 个刀片的集群上,使用 999 次性状置换,在 4 天 9 小时内分析所有基因-基因互作,并使用 999 次性状置换来评估统计显著性。在连续性状的情况下,类似的运行需要 9 天。我们的程序在真实的克罗恩病(CD)数据中发现了 14 个 SNP-SNP 相互作用,其多重检验校正后的 p 值小于 0.05。
我们的软件是第一个能够在几天内解决大规模 SNP-SNP 相互作用问题的 MB-MDR 方法的实现,同时不需要太多的内存,并且能够适当控制 I 型错误率。正在构建一个新的实现方案,以达到全基因组互作筛选。在克罗恩病的背景下,MBMDR-3.0.3 可以识别已知领域的互作区域,并从生物学角度进行解释。这表明我们的软件具有发现相关表型-基因型高阶关联的能力。