SANOFI R&D, Translational Sciences, Chilly Mazarin, 91385, France.
Laboratoire de Probabilités et Modèles Aléatoires, Université Pierre et Marie Curie, 4, place Jussieu, Paris Cedex 05, 75252, France.
BMC Bioinformatics. 2018 Jun 18;19(1):231. doi: 10.1186/s12859-018-2229-8.
Part of the missing heritability in Genome Wide Association Studies (GWAS) is expected to be explained by interactions between genetic variants, also called epistasis. Various statistical methods have been developed to detect epistasis in case-control GWAS. These methods face major statistical challenges due to the number of tests required, the complexity of the Linkage Disequilibrium (LD) structure, and the lack of consensus regarding the definition of epistasis. Their limited impact in terms of uncovering new biological knowledge might be explained in part by the limited amount of experimental data available to validate their statistical performances in a realistic GWAS context. In this paper, we introduce a simulation pipeline for generating real scale GWAS data, including epistasis and realistic LD structure. We evaluate five exhaustive bivariate interaction methods, fastepi, GBOOST, SHEsisEpi, DSS, and IndOR. Two hundred thirty four different disease scenarios are considered in extensive simulations. We report the performances of each method in terms of false positive rate control, power, area under the ROC curve (AUC), and computation time using a GPU. Finally we compare the result of each methods on a real GWAS of type 2 diabetes from the Welcome Trust Case Control Consortium.
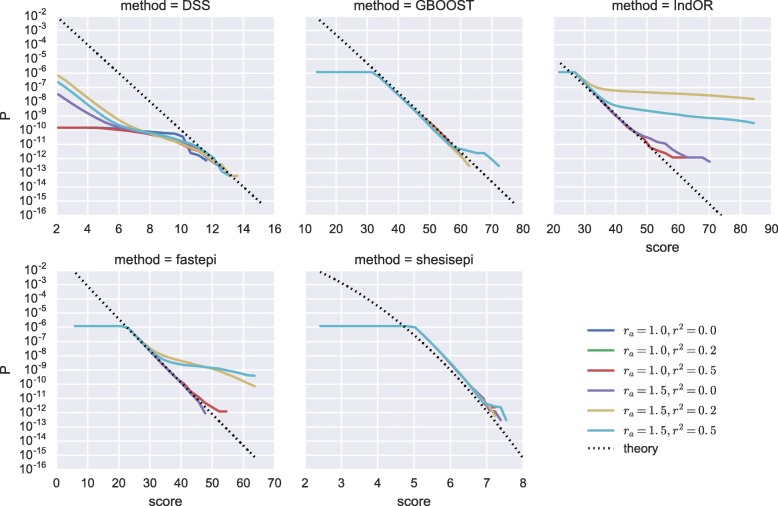
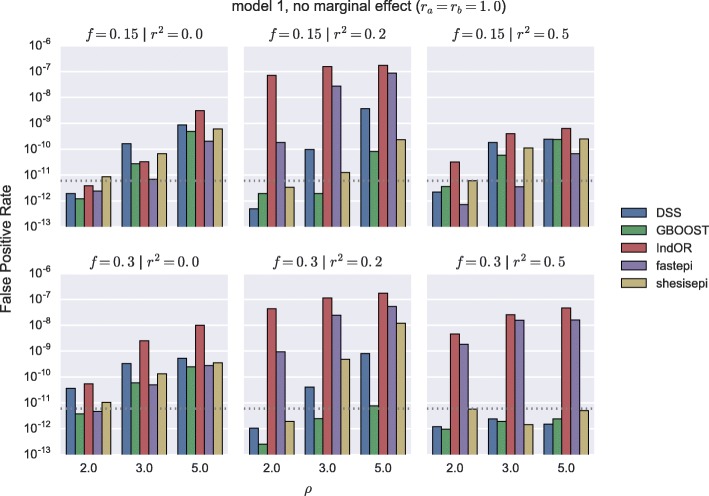
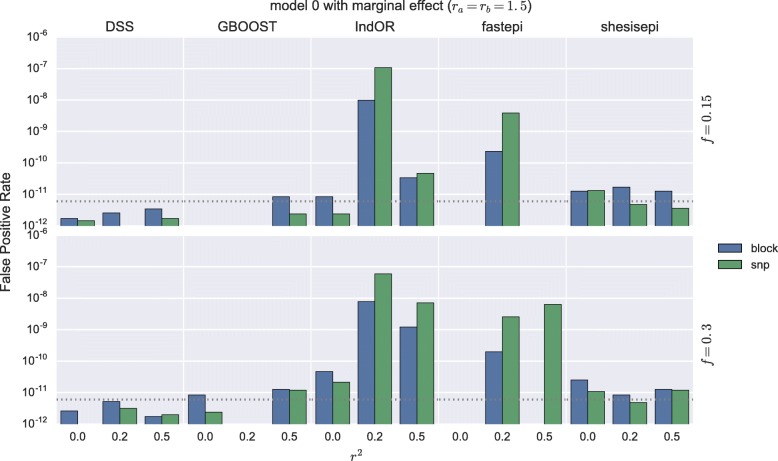
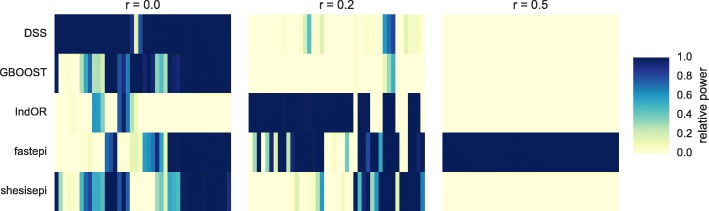
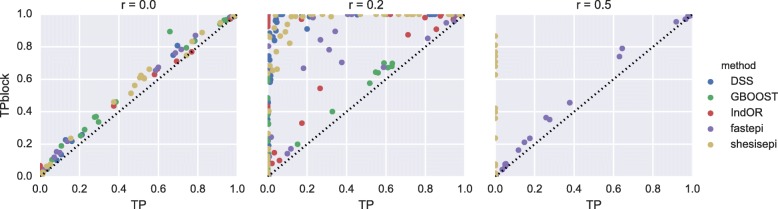
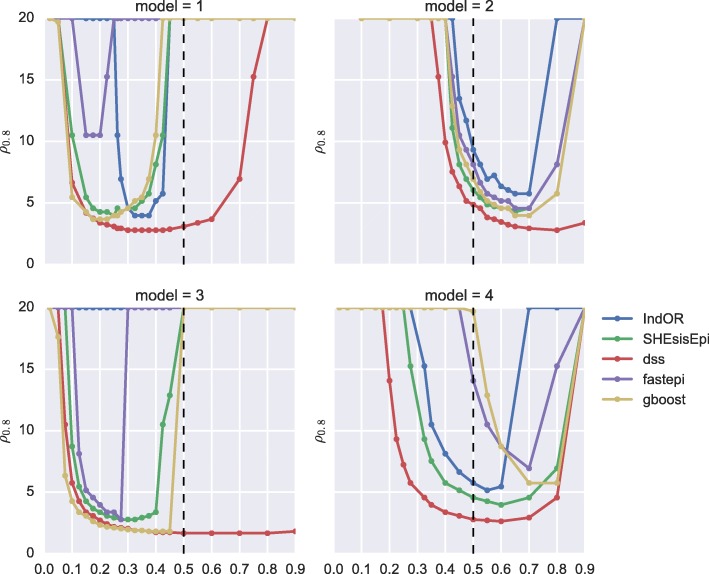
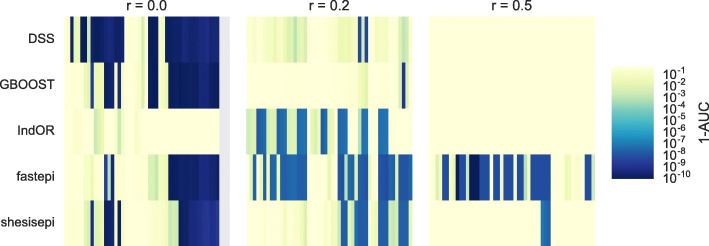
GBOOST, SHEsisEpi and DSS allow a satisfactory control of the false positive rate. fastepi and IndOR present an increase in false positive rate in presence of LD between causal SNPs, with our definition of epistasis. DSS performs best in terms of power and AUC in most scenarios with no or weak LD between causal SNPs. All methods can exhaustively analyze a GWAS with 6.10 SNPs and 15,000 samples in a couple of hours using a GPU.
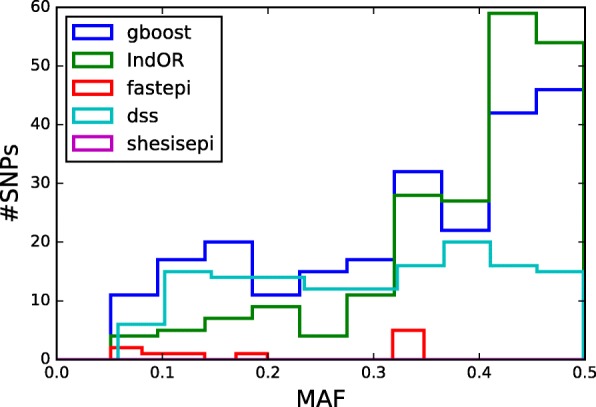
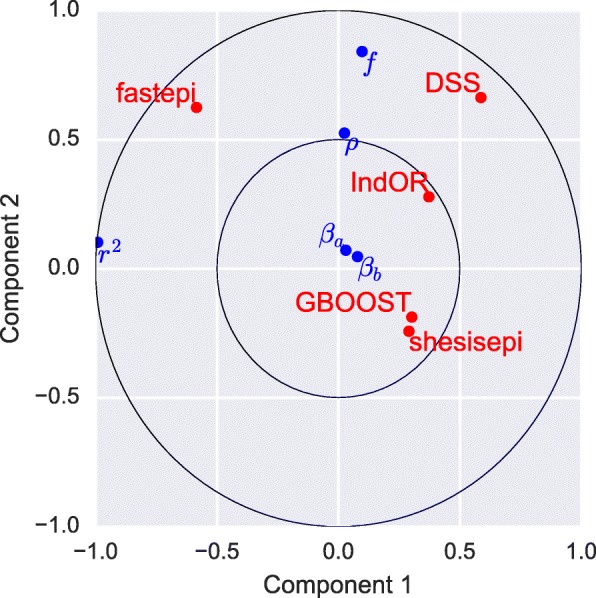
This study confirms that computation time is no longer a limiting factor for performing an exhaustive search of epistasis in large GWAS. For this task, using DSS on SNP pairs with limited LD seems to be a good strategy to achieve the best statistical performance. A combination approach using both DSS and GBOOST is supported by the simulation results and the analysis of the WTCCC dataset demonstrated that this approach can detect distinct genes in epistasis. Finally, weak epistasis between common variants will be detectable with existing methods when GWAS of a few tens of thousands cases and controls are available.
全基因组关联研究(GWAS)中部分遗传易感性缺失预计可以通过遗传变异之间的相互作用来解释,这种相互作用也被称为上位性。已经开发了各种统计方法来检测病例对照 GWAS 中的上位性。由于需要进行的测试数量众多、连锁不平衡(LD)结构的复杂性以及关于上位性定义的共识缺乏,这些方法面临着重大的统计挑战。它们在揭示新的生物学知识方面的影响有限,部分原因可能是由于缺乏可用的实验数据来验证它们在真实 GWAS 背景下的统计性能。在本文中,我们引入了一个用于生成真实规模 GWAS 数据的模拟管道,包括上位性和真实 LD 结构。我们评估了五种全面的双变量相互作用方法,即 fastepi、GBOOST、SHEsisEpi、DSS 和 IndOR。在广泛的模拟中考虑了 234 种不同的疾病情况。我们报告了每种方法在假阳性率控制、功效、ROC 曲线下面积(AUC)和使用 GPU 的计算时间方面的性能。最后,我们将每种方法在来自 Welcome Trust Case Control Consortium 的 2 型糖尿病真实 GWAS 上的结果进行了比较。
GBOOST、SHEsisEpi 和 DSS 可以令人满意地控制假阳性率。fastepi 和 IndOR 在我们定义的上位性存在因果 SNP 之间的 LD 时,假阳性率会增加。在因果 SNP 之间没有或弱 LD 的大多数情况下,DSS 在功效和 AUC 方面表现最佳。所有方法都可以在几个小时内使用 GPU 对具有 6.10 个 SNP 和 15000 个样本的 GWAS 进行全面分析。
这项研究证实,计算时间不再是在大型 GWAS 中进行上位性全面搜索的限制因素。对于这项任务,在 SNP 对之间使用 DSS 并且 LD 有限似乎是实现最佳统计性能的一种好策略。模拟结果支持 DSS 和 GBOOST 的组合方法,WTCCC 数据集的分析表明,这种方法可以检测到上位性中的不同基因。最后,当有几万个病例和对照的 GWAS 时,现有方法可以检测到常见变体之间较弱的上位性。