Bioinformatics Group, Department of Computer Science, University College London, London, United Kingdom.
PLoS One. 2013 May 22;8(5):e63754. doi: 10.1371/journal.pone.0063754. Print 2013.
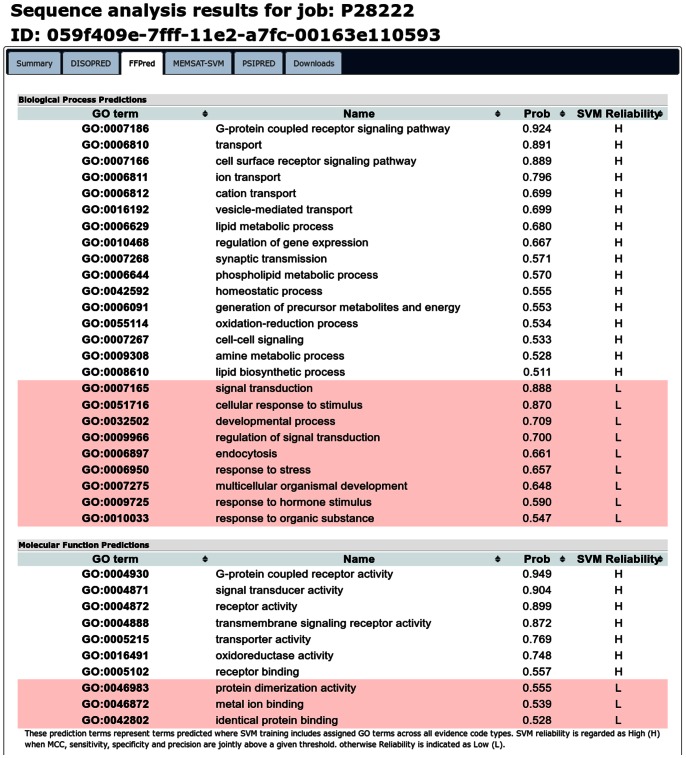
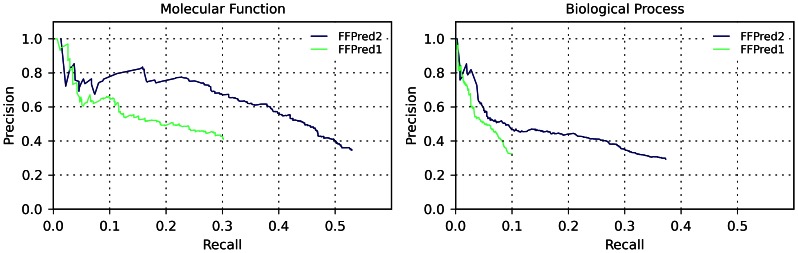
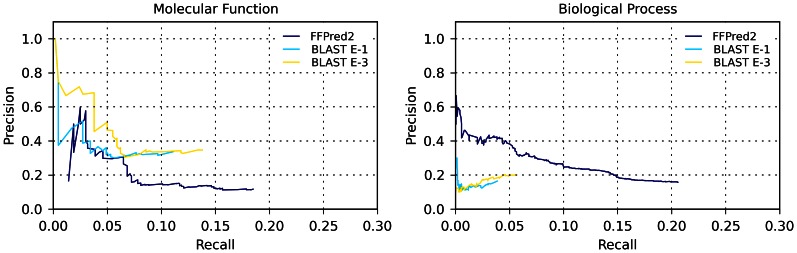
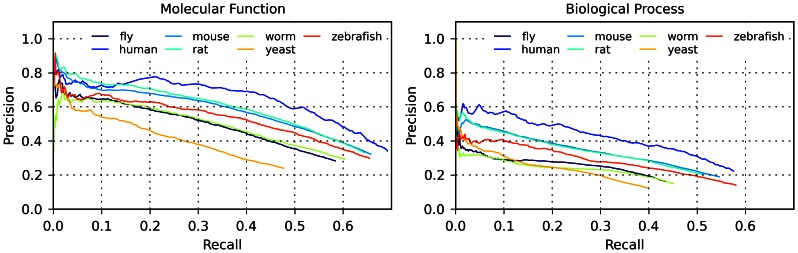
To understand fully cell behaviour, biologists are making progress towards cataloguing the functional elements in the human genome and characterising their roles across a variety of tissues and conditions. Yet, functional information - either experimentally validated or computationally inferred by similarity - remains completely missing for approximately 30% of human proteins. FFPred was initially developed to bridge this gap by targeting sequences with distant or no homologues of known function and by exploiting clear patterns of intrinsic disorder associated with particular molecular activities and biological processes. Here, we present an updated and improved version, which builds on larger datasets of protein sequences and annotations, and uses updated component feature predictors as well as revised training procedures. FFPred 2.0 includes support vector regression models for the prediction of 442 Gene Ontology (GO) terms, which largely expand the coverage of the ontology and of the biological process category in particular. The GO term list mainly revolves around macromolecular interactions and their role in regulatory, signalling, developmental and metabolic processes. Benchmarking experiments on newly annotated proteins show that FFPred 2.0 provides more accurate functional assignments than its predecessor and the ProtFun server do; also, its assignments can complement information obtained using BLAST-based transfer of annotations, improving especially prediction in the biological process category. Furthermore, FFPred 2.0 can be used to annotate proteins belonging to several eukaryotic organisms with a limited decrease in prediction quality. We illustrate all these points through the use of both precision-recall plots and of the COGIC scores, which we recently proposed as an alternative numerical evaluation measure of function prediction accuracy.
为了全面理解细胞行为,生物学家正在努力对人类基因组中的功能元件进行编目,并在各种组织和条件下对其功能进行描述。然而,大约有 30%的人类蛋白质的功能信息(无论是通过实验验证还是通过相似性计算推断的)仍然完全缺失。FFPred 最初是为了弥补这一空白而开发的,它的目标是针对那些具有已知功能的远缘或无同源序列,并利用与特定分子活性和生物过程相关的明显的无序结构模式。在这里,我们提出了一个更新和改进的版本,该版本基于更大的蛋白质序列和注释数据集,并使用更新的组件特征预测器以及修订的训练程序。FFPred 2.0 包括 442 个基因本体 (GO) 术语的支持向量回归模型预测,这在很大程度上扩大了本体的覆盖范围,特别是生物过程类别。GO 术语列表主要围绕着大分子相互作用及其在调节、信号转导、发育和代谢过程中的作用。对新注释蛋白质的基准测试实验表明,FFPred 2.0 提供的功能分配比其前身和 ProtFun 服务器更准确;此外,其分配可以补充使用基于 BLAST 的注释转移获得的信息,特别是在生物过程类别中。此外,FFPred 2.0 可以用于对属于几个真核生物的蛋白质进行注释,而预测质量的下降有限。我们通过使用精度-召回图和 COGIC 分数来说明所有这些点,我们最近提出 COGIC 分数作为功能预测准确性的替代数值评估指标。