Garcia Castro L Jael, McLaughlin C, Garcia A
Institute for Digital Information and Scientific Communication, College of Communication and Information, Florida State University, Tallahassee, Florida, 32306-2651, USA.
J Biomed Semantics. 2013 Apr 15;4 Suppl 1(Suppl 1):S5. doi: 10.1186/2041-1480-4-S1-S5.
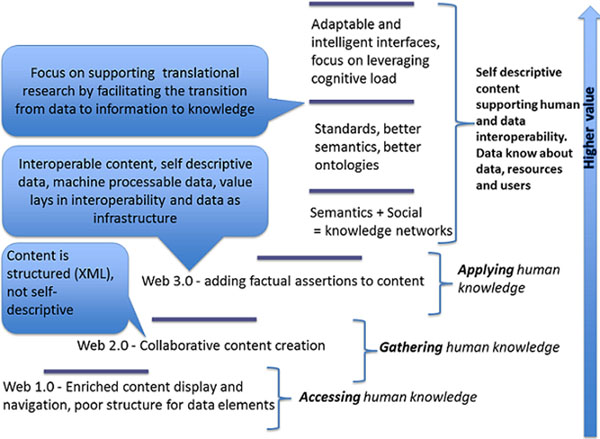
The World Wide Web has become a dissemination platform for scientific and non-scientific publications. However, most of the information remains locked up in discrete documents that are not always interconnected or machine-readable. The connectivity tissue provided by RDF technology has not yet been widely used to support the generation of self-describing, machine-readable documents.
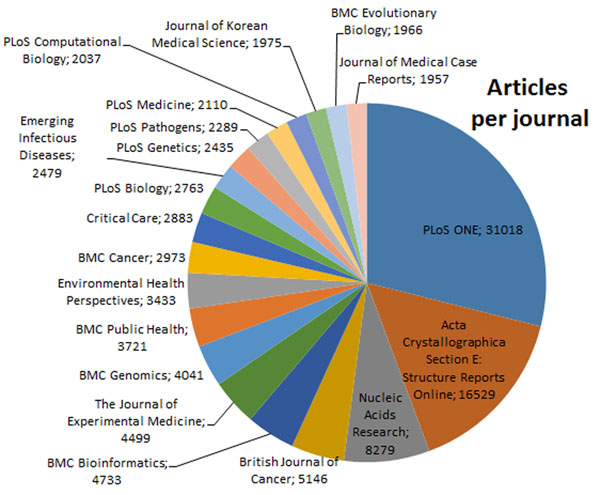
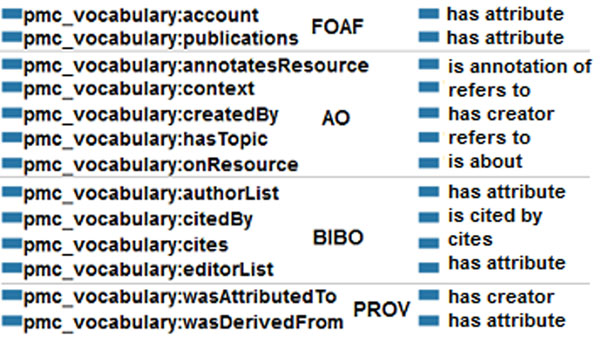
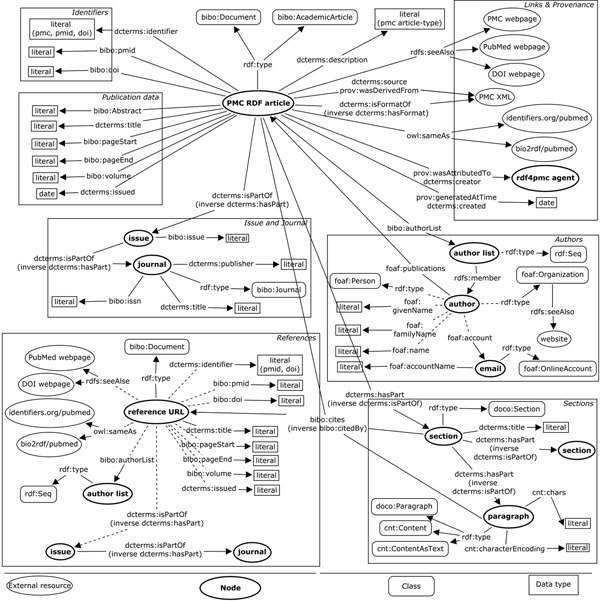
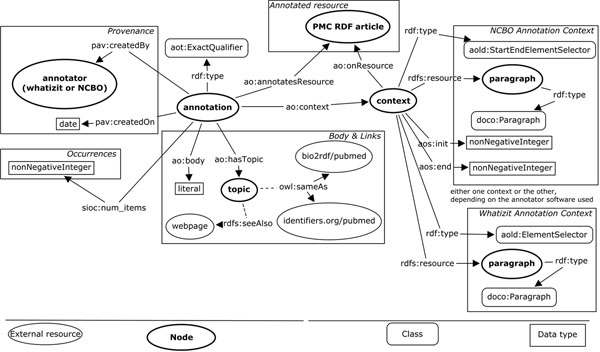
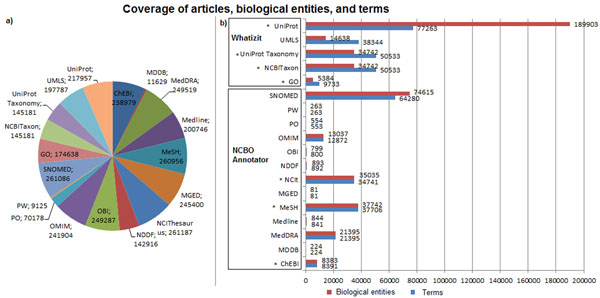
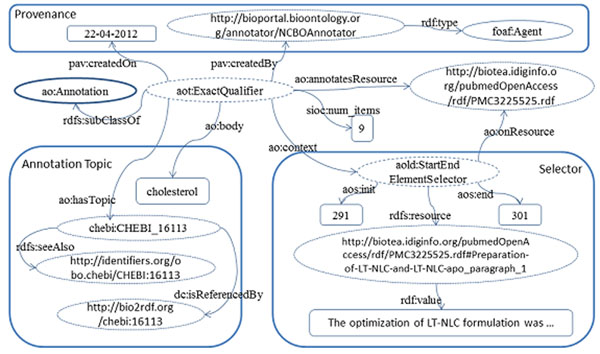
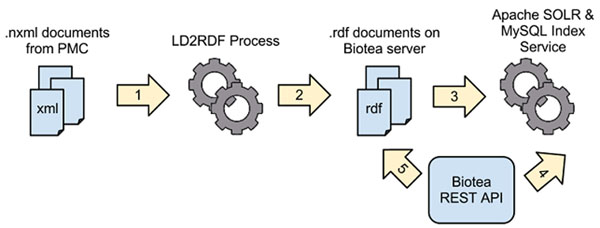
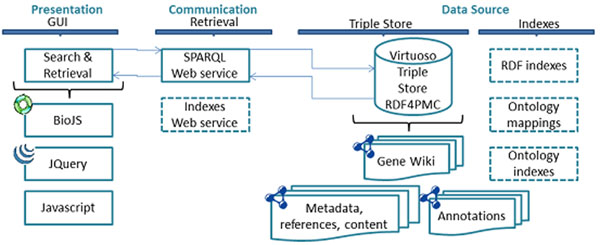
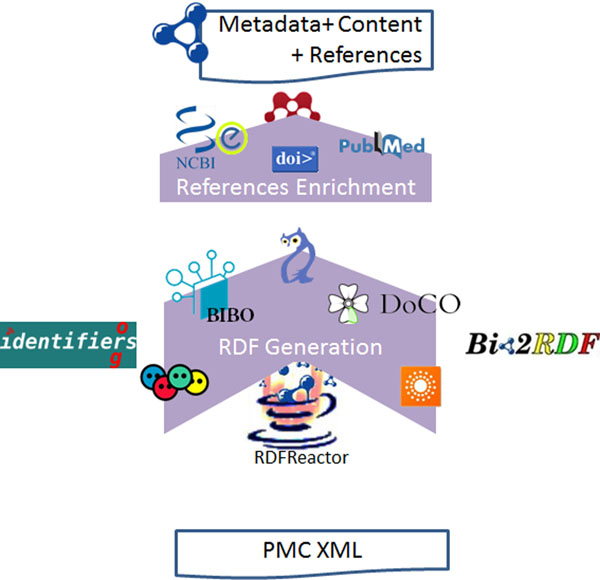
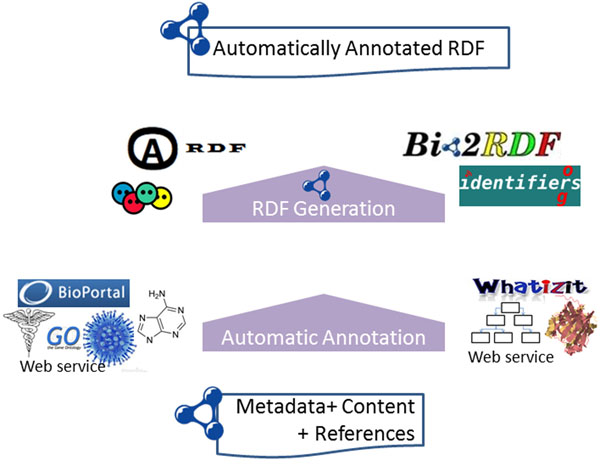
In this paper, we present our approach to the generation of self-describing machine-readable scholarly documents. We understand the scientific document as an entry point and interface to the Web of Data. We have semantically processed the full-text, open-access subset of PubMed Central. Our RDF model and resulting dataset make extensive use of existing ontologies and semantic enrichment services. We expose our model, services, prototype, and datasets at http://biotea.idiginfo.org/
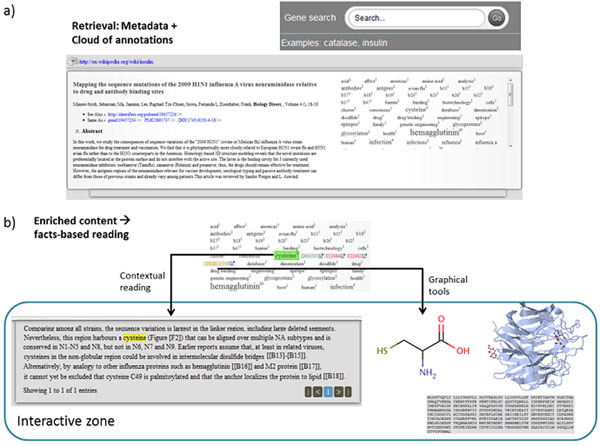
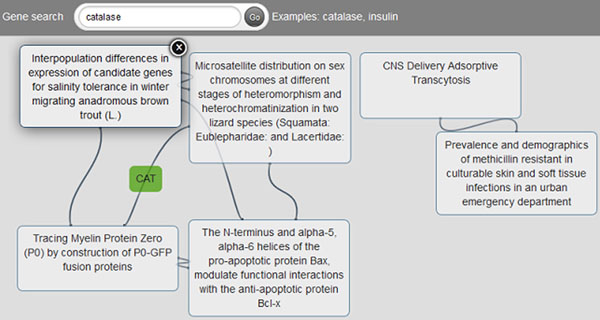
The semantic processing of biomedical literature presented in this paper embeds documents within the Web of Data and facilitates the execution of concept-based queries against the entire digital library. Our approach delivers a flexible and adaptable set of tools for metadata enrichment and semantic processing of biomedical documents. Our model delivers a semantically rich and highly interconnected dataset with self-describing content so that software can make effective use of it.
万维网已成为科学和非科学出版物的传播平台。然而,大多数信息仍被锁定在离散的文档中,这些文档并不总是相互关联或机器可读的。RDF技术提供的连接组织尚未被广泛用于支持生成自我描述的、机器可读的文档。
在本文中,我们展示了生成自我描述的机器可读学术文档的方法。我们将科学文档理解为数据网络的入口点和接口。我们对PubMed Central的全文开放获取子集进行了语义处理。我们的RDF模型和所得数据集广泛使用了现有的本体和语义丰富服务。我们在http://biotea.idiginfo.org/上展示了我们的模型、服务、原型和数据集。
本文中提出的生物医学文献语义处理将文档嵌入数据网络,并便于对整个数字图书馆执行基于概念的查询。我们的方法为生物医学文档的元数据丰富和语义处理提供了一套灵活且可适应的工具。我们的模型提供了一个语义丰富且高度互联的数据集,其内容具有自我描述性,以便软件能够有效利用它。