Gao Junfeng, Wang Zhao, Yang Yong, Zhang Wenjia, Tao Chunyi, Guan Jinan, Rao Nini
College of Biomedical Engineering, South-Central University for Nationalities, Wuhan, People's Republic of China.
PLoS One. 2013 Jun 3;8(6):e64704. doi: 10.1371/journal.pone.0064704. Print 2014.
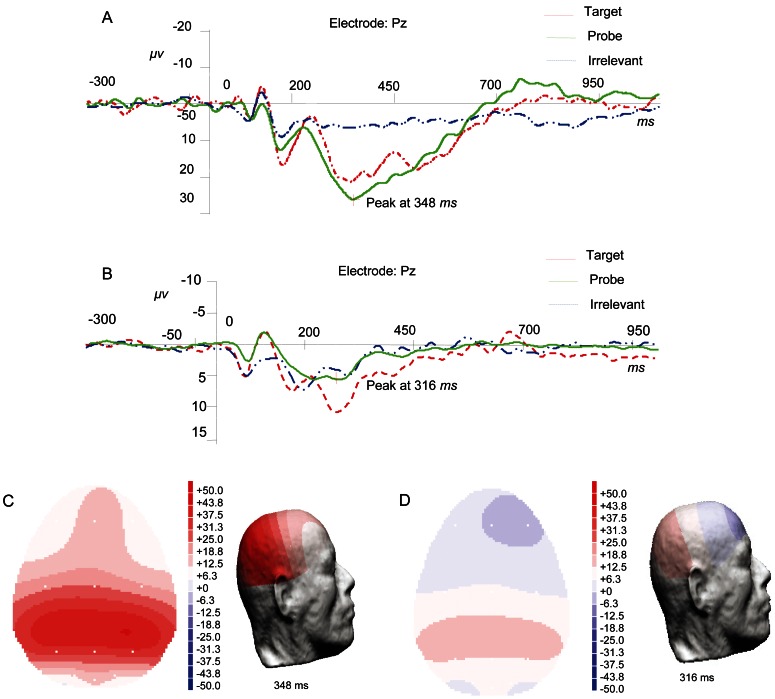
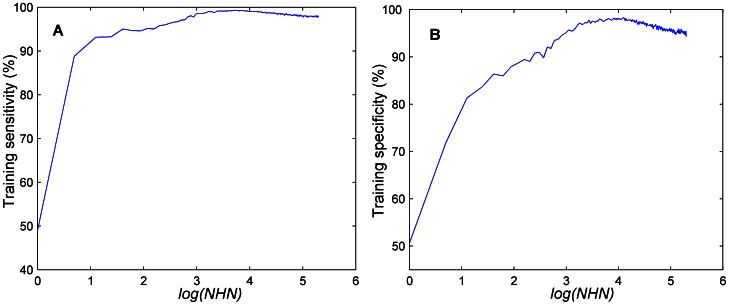
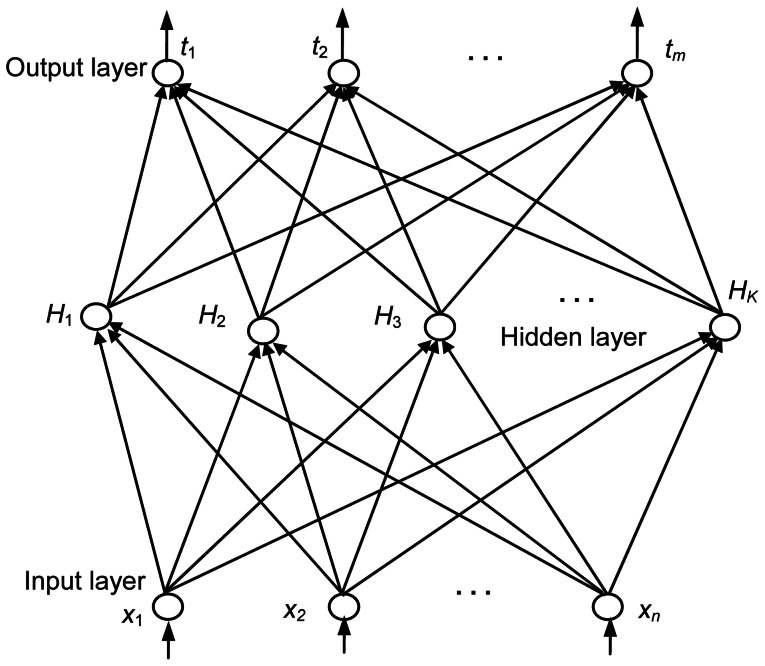
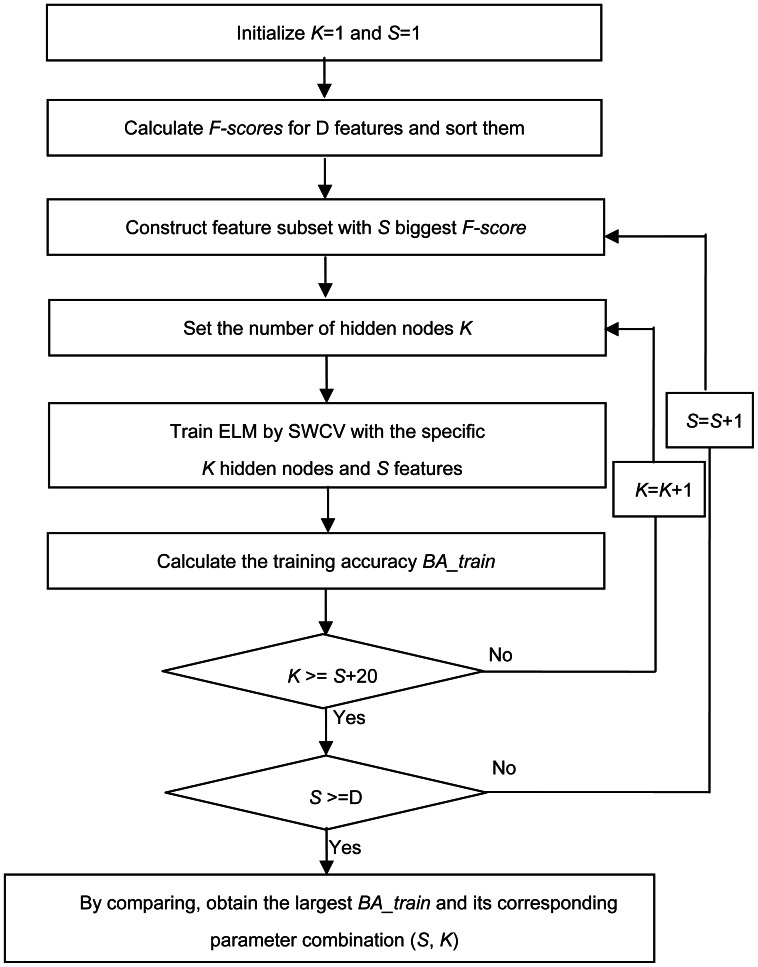
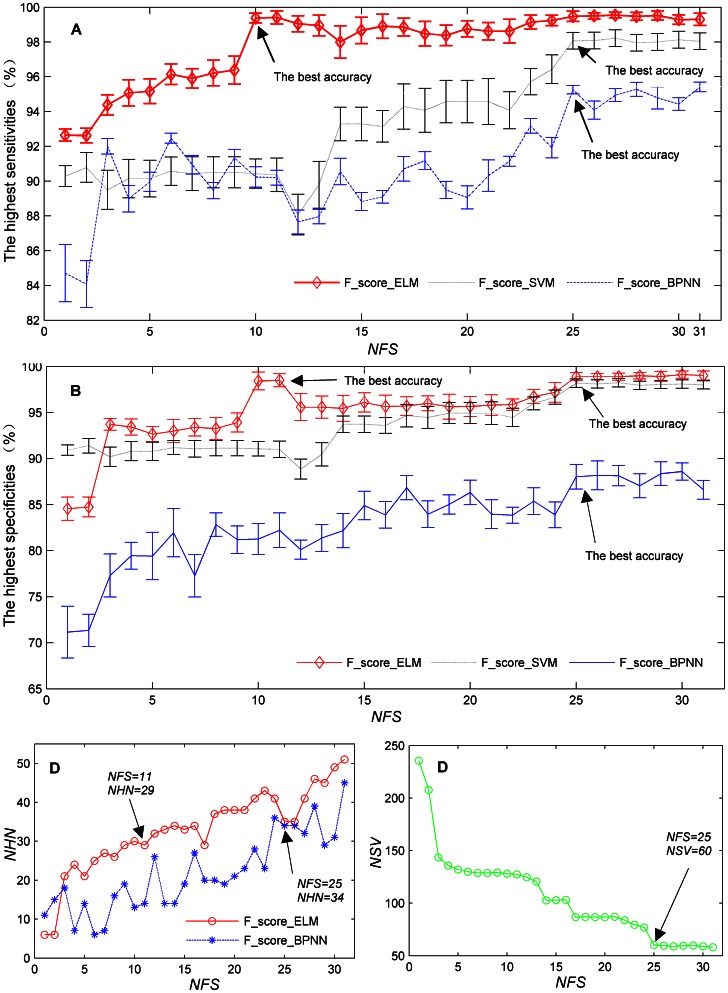
A new machine learning method referred to as F-score_ELM was proposed to classify the lying and truth-telling using the electroencephalogram (EEG) signals from 28 guilty and innocent subjects. Thirty-one features were extracted from the probe responses from these subjects. Then, a recently-developed classifier called extreme learning machine (ELM) was combined with F-score, a simple but effective feature selection method, to jointly optimize the number of the hidden nodes of ELM and the feature subset by a grid-searching training procedure. The method was compared to two classification models combining principal component analysis with back-propagation network and support vector machine classifiers. We thoroughly assessed the performance of these classification models including the training and testing time, sensitivity and specificity from the training and testing sets, as well as network size. The experimental results showed that the number of the hidden nodes can be effectively optimized by the proposed method. Also, F-score_ELM obtained the best classification accuracy and required the shortest training and testing time.
一种名为F-score_ELM的新机器学习方法被提出来,用于利用28名有罪和无罪受试者的脑电图(EEG)信号对说谎和讲真话进行分类。从这些受试者的探测反应中提取了31个特征。然后,将一种最近开发的名为极限学习机(ELM)的分类器与F-score(一种简单但有效的特征选择方法)相结合,通过网格搜索训练过程共同优化ELM的隐藏节点数量和特征子集。该方法与将主成分分析与反向传播网络和支持向量机分类器相结合的两种分类模型进行了比较。我们全面评估了这些分类模型的性能,包括训练和测试时间、训练集和测试集的敏感性和特异性以及网络规模。实验结果表明,所提出的方法可以有效地优化隐藏节点的数量。此外,F-score_ELM获得了最佳的分类准确率,并且所需的训练和测试时间最短。