Broad Institute, 7 Cambridge Center, Cambridge, MA 02142, USA and Massachusetts Institute of Technology, 77 Massachusetts Avenue, Cambridge, MA 02139, USA.
Bioinformatics. 2013 Oct 1;29(19):2387-94. doi: 10.1093/bioinformatics/btt419. Epub 2013 Jul 31.
Kinases of the eukaryotic protein kinase superfamily are key regulators of most aspects eukaryotic cellular behavior and have provided several drug targets including kinases dysregulated in cancers. The rapid increase in the number of genomic sequences has created an acute need to identify and classify members of this important class of enzymes efficiently and accurately.
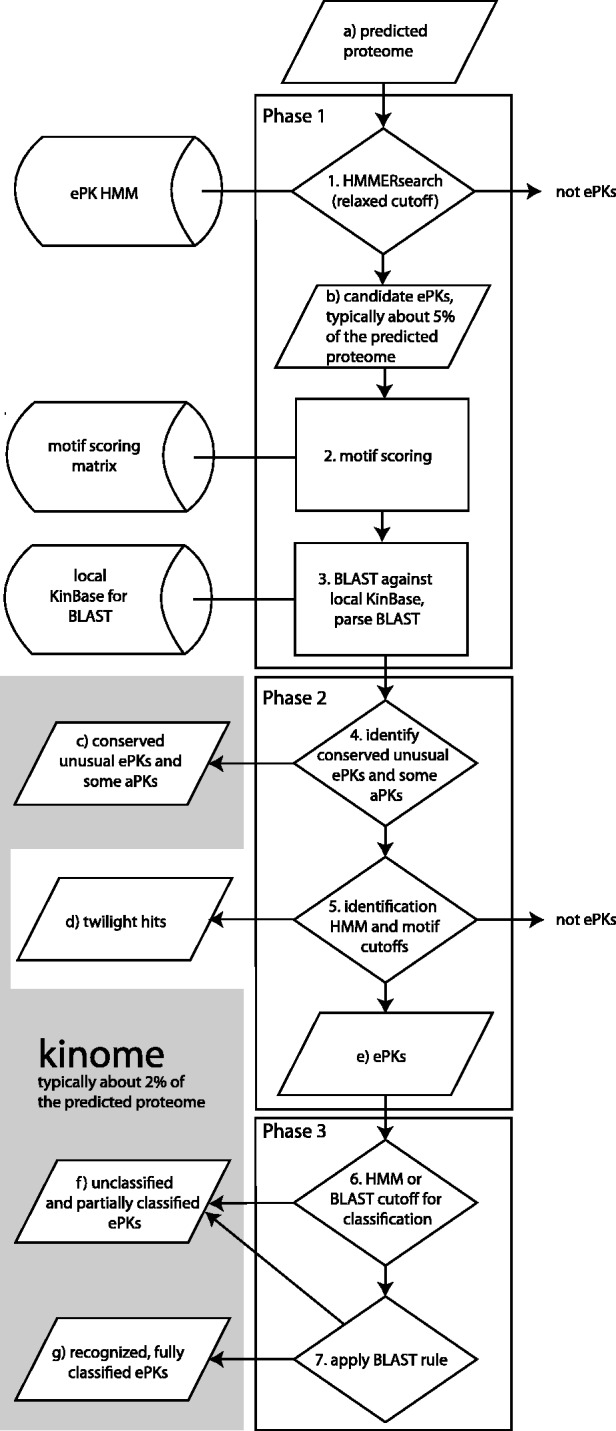
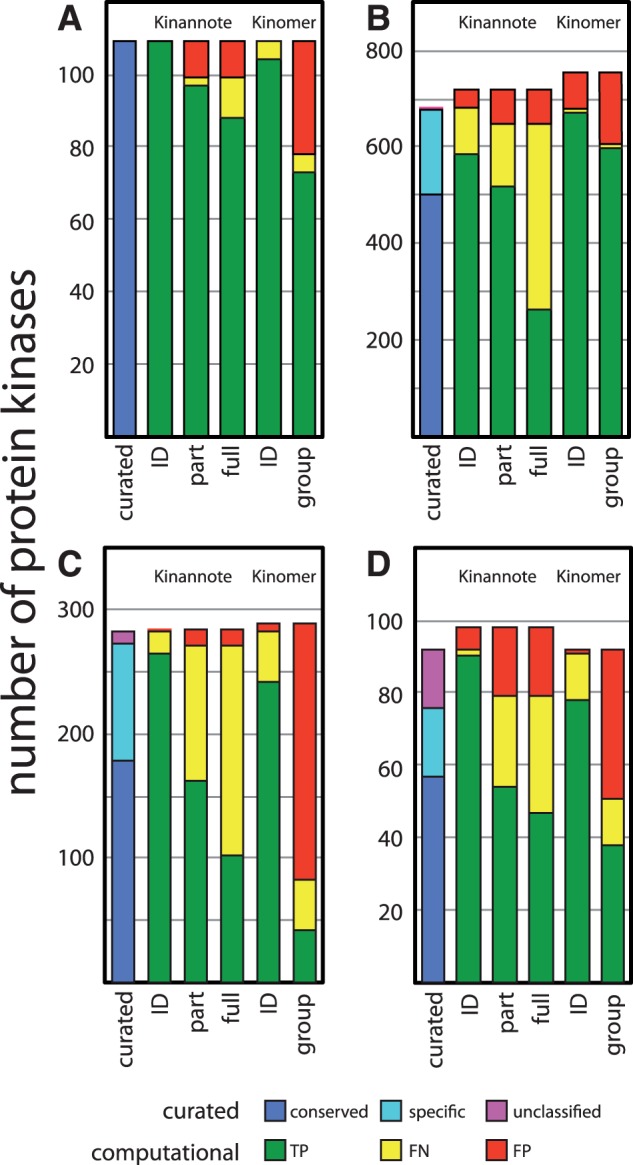
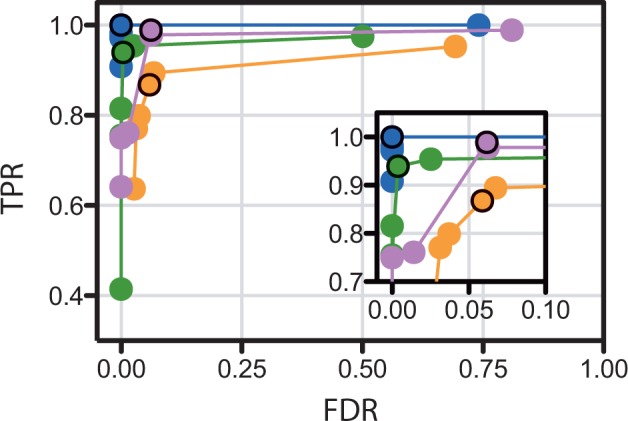
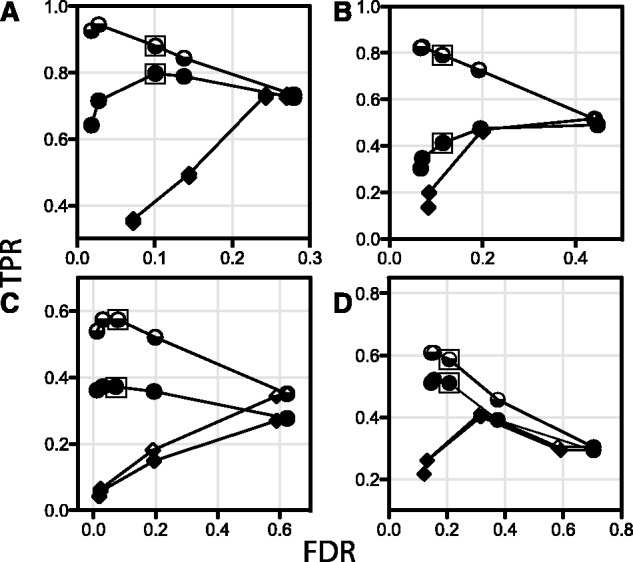
Kinannote produces a draft kinome and comparative analyses for a predicted proteome using a single line command, and it is currently the only tool that automatically classifies protein kinases using the controlled vocabulary of Hanks and Hunter [Hanks and Hunter (1995)]. A hidden Markov model in combination with a position-specific scoring matrix is used by Kinannote to identify kinases, which are subsequently classified using a BLAST comparison with a local version of KinBase, the curated protein kinase dataset from www.kinase.com. Kinannote was tested on the predicted proteomes from four divergent species. The average sensitivity and precision for kinome retrieval from the test species are 94.4 and 96.8%. The ability of Kinannote to classify identified kinases was also evaluated, and the average sensitivity and precision for full classification of conserved kinases are 71.5 and 82.5%, respectively. Kinannote has had a significant impact on eukaryotic genome annotation, providing protein kinase annotations for 36 genomes made public by the Broad Institute in the period spanning 2009 to the present.
Kinannote is freely available at http://sourceforge.net/projects/kinannote.
真核蛋白激酶超家族的激酶是真核细胞行为的大多数方面的关键调节剂,并且已经提供了几个药物靶点,包括在癌症中失调的激酶。基因组序列数量的快速增加,迫切需要有效地和准确地识别和分类这个重要酶类别的成员。
Kinannote 使用单行命令为预测的蛋白质组生成激酶组草案和比较分析,并且它是目前唯一使用 Hanks 和 Hunter 的受控词汇自动对蛋白激酶进行分类的工具[Hanks 和 Hunter (1995)]。Kinannote 使用隐马尔可夫模型结合位置特异性评分矩阵来识别激酶,然后使用与 KinBase 的本地版本(来自 www.kinase.com 的经过精心整理的蛋白激酶数据集)的 BLAST 比较对激酶进行分类。Kinannote 在四个不同物种的预测蛋白质组上进行了测试。从测试物种中检索激酶组的平均灵敏度和精度分别为 94.4%和 96.8%。Kinannote 对识别出的激酶进行分类的能力也进行了评估,保守激酶的完全分类的平均灵敏度和精度分别为 71.5%和 82.5%。Kinannote 对真核基因组注释产生了重大影响,为 Broad 研究所于 2009 年至今公布的 36 个基因组提供了蛋白激酶注释。
Kinannote 可免费在 http://sourceforge.net/projects/kinannote 获得。