Department of Internal Medicine, University of Michigan, Ann Arbor, Michigan, USA.
BMJ Open. 2013 Aug 1;3(8):e002847. doi: 10.1136/bmjopen-2013-002847.
Missing laboratory data is a common issue, but the optimal method of imputation of missing values has not been determined. The aims of our study were to compare the accuracy of four imputation methods for missing completely at random laboratory data and to compare the effect of the imputed values on the accuracy of two clinical predictive models.
Retrospective cohort analysis of two large data sets.
A tertiary level care institution in Ann Arbor, Michigan.
The Cirrhosis cohort had 446 patients and the Inflammatory Bowel Disease cohort had 395 patients.
Non-missing laboratory data were randomly removed with varying frequencies from two large data sets, and we then compared the ability of four methods-missForest, mean imputation, nearest neighbour imputation and multivariate imputation by chained equations (MICE)-to impute the simulated missing data. We characterised the accuracy of the imputation and the effect of the imputation on predictive ability in two large data sets.
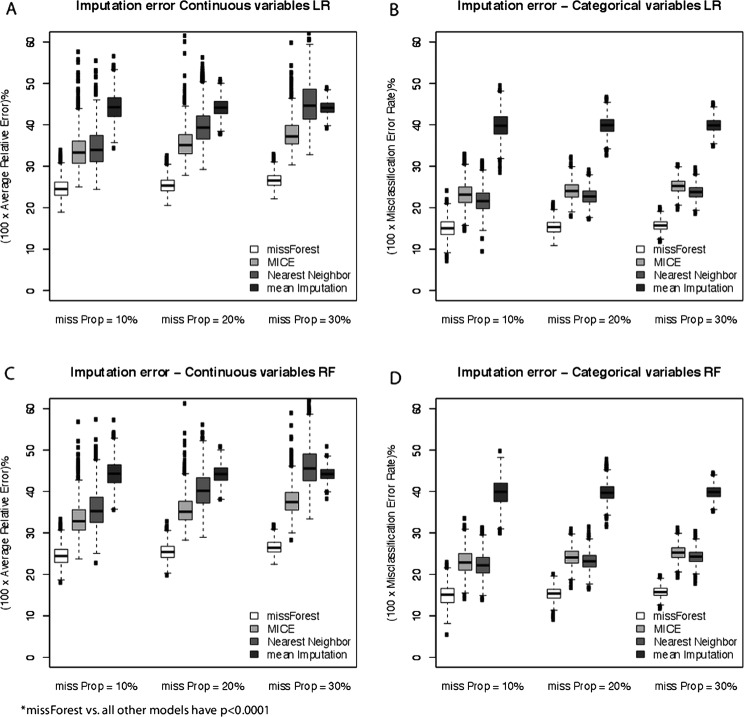
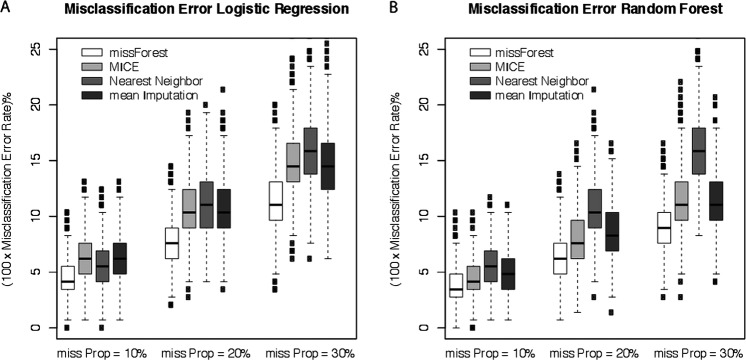
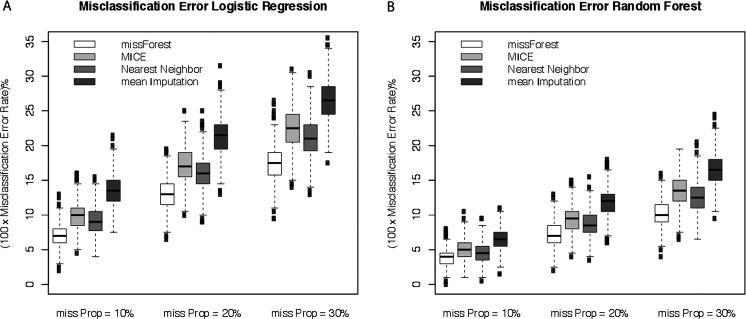
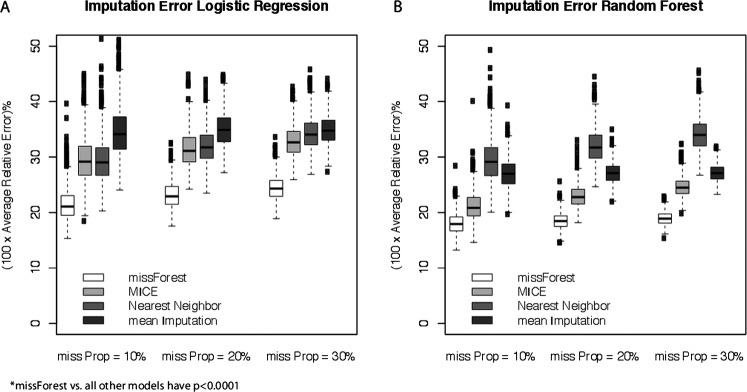
MissForest had the least imputation error for both continuous and categorical variables at each frequency of missingness, and it had the smallest prediction difference when models used imputed laboratory values. In both data sets, MICE had the second least imputation error and prediction difference, followed by the nearest neighbour and mean imputation.
MissForest is a highly accurate method of imputation for missing laboratory data and outperforms other common imputation techniques in terms of imputation error and maintenance of predictive ability with imputed values in two clinical predicative models.
缺失的实验室数据是一个常见的问题,但最佳的缺失值插补方法尚未确定。我们的研究目的是比较四种完全随机缺失的实验室数据插补方法的准确性,并比较插补值对两种临床预测模型准确性的影响。
对两个大型数据集进行回顾性队列分析。
密歇根州安阿伯市的一个三级护理机构。
肝硬化队列有 446 名患者,炎症性肠病队列有 395 名患者。
两种大型数据集的非缺失实验室数据随机以不同频率缺失,并比较四种方法(missForest、均值插补、最近邻插补和链式方程多元插补(MICE))模拟缺失数据的插补能力。我们描述了插补的准确性以及插补对两种大型数据集预测能力的影响。
在每种缺失频率下,missForest 对连续和分类变量的插补误差最小,当模型使用插补的实验室值时,其预测差异最小。在两个数据集中,MICE 的插补误差和预测差异最小,其次是最近邻和均值插补。
missForest 是一种高度准确的缺失实验室数据插补方法,在两种临床预测模型中,在插补误差和维持插补值的预测能力方面优于其他常见的插补技术。