Max Planck Institute for Human Cognitive and Brain Sciences, Leipzig, Germany ; Group for Neural Theory, Institute of Cognitive Studies, École Normale Supérieure, Paris, France.
PLoS Comput Biol. 2013;9(9):e1003219. doi: 10.1371/journal.pcbi.1003219. Epub 2013 Sep 12.
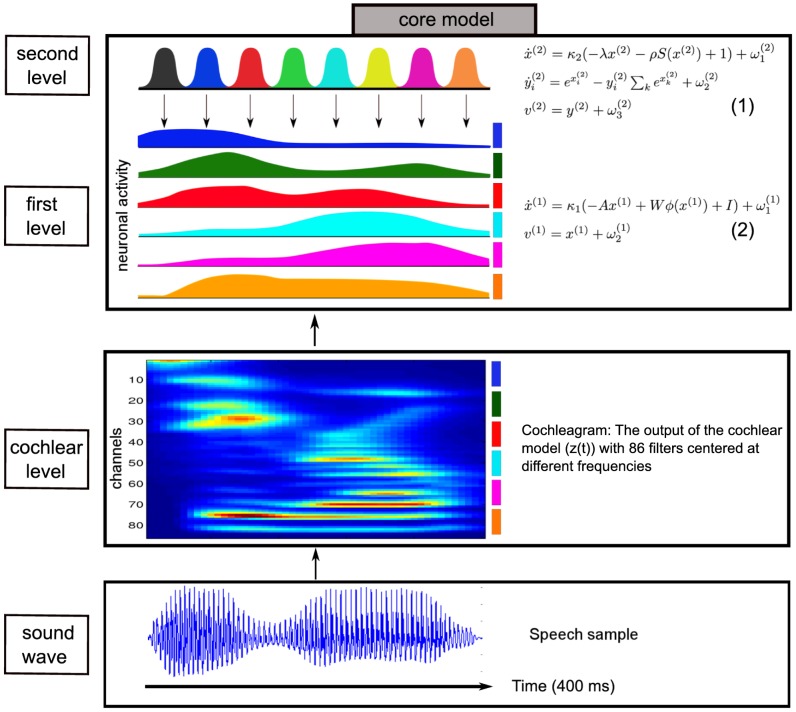
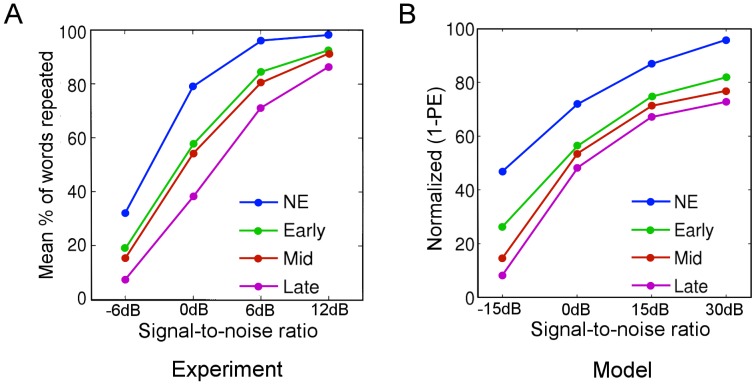
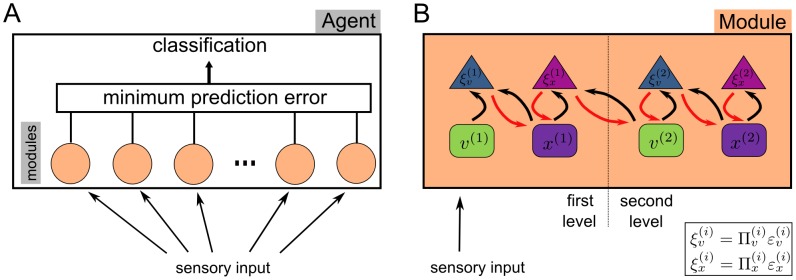
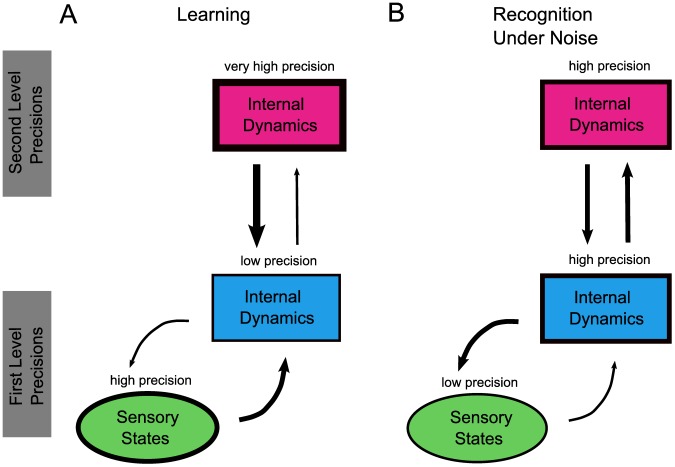
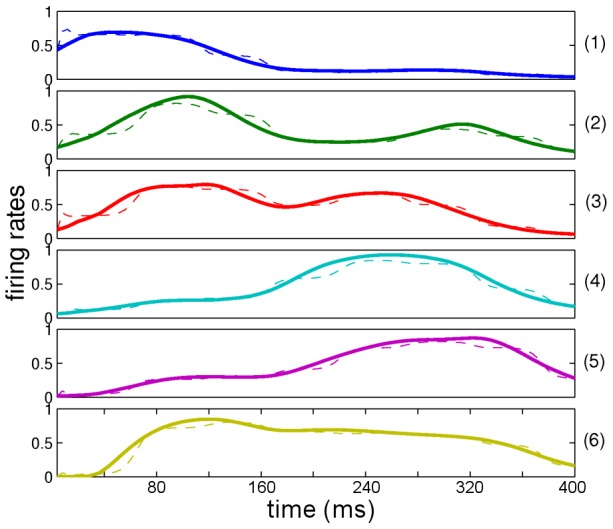
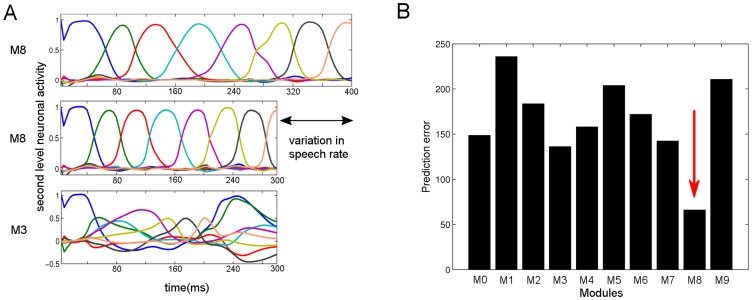
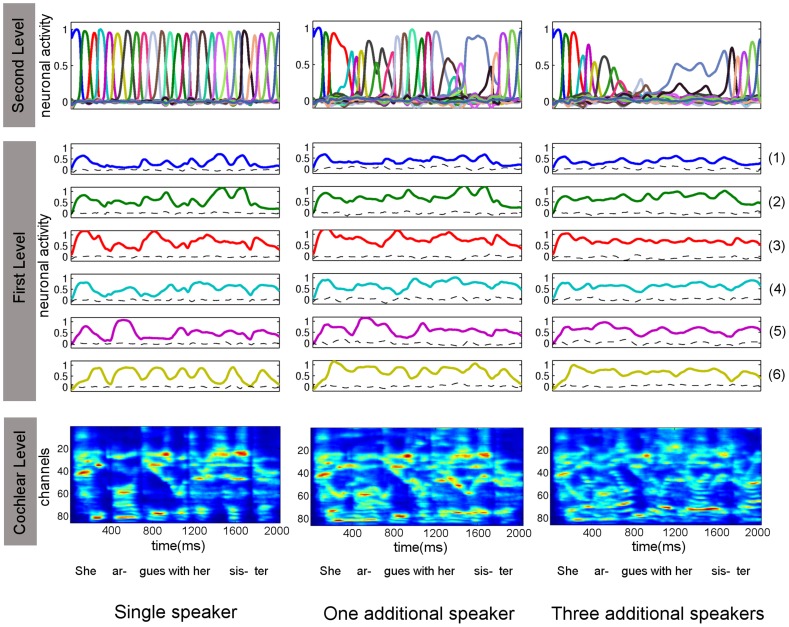
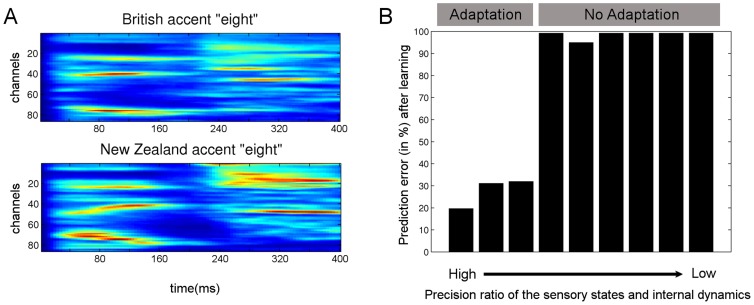
Our knowledge about the computational mechanisms underlying human learning and recognition of sound sequences, especially speech, is still very limited. One difficulty in deciphering the exact means by which humans recognize speech is that there are scarce experimental findings at a neuronal, microscopic level. Here, we show that our neuronal-computational understanding of speech learning and recognition may be vastly improved by looking at an animal model, i.e., the songbird, which faces the same challenge as humans: to learn and decode complex auditory input, in an online fashion. Motivated by striking similarities between the human and songbird neural recognition systems at the macroscopic level, we assumed that the human brain uses the same computational principles at a microscopic level and translated a birdsong model into a novel human sound learning and recognition model with an emphasis on speech. We show that the resulting Bayesian model with a hierarchy of nonlinear dynamical systems can learn speech samples such as words rapidly and recognize them robustly, even in adverse conditions. In addition, we show that recognition can be performed even when words are spoken by different speakers and with different accents-an everyday situation in which current state-of-the-art speech recognition models often fail. The model can also be used to qualitatively explain behavioral data on human speech learning and derive predictions for future experiments.
我们对于人类学习和识别声音序列(尤其是语音)的计算机制的了解仍然非常有限。在破译人类识别语音的确切手段时,存在一个困难,即神经元、微观层面上的实验结果稀缺。在这里,我们通过观察动物模型(即鸣禽)表明,我们对语音学习和识别的神经元计算理解可能会得到极大的提高,因为鸣禽面临着与人类相同的挑战:以在线方式学习和解码复杂的听觉输入。受宏观层面上人类和鸣禽神经识别系统之间惊人相似性的启发,我们假设人类大脑在微观层面上使用相同的计算原则,并将鸟鸣模型转化为一个新的人类声音学习和识别模型,重点是语音。我们表明,具有非线性动力系统层次结构的贝叶斯模型可以快速学习语音样本(如单词)并进行稳健识别,即使在不利条件下也是如此。此外,我们表明,即使单词是由不同的说话者和不同的口音说出的,识别也可以进行——这是当前最先进的语音识别模型经常失败的日常情况。该模型还可以用于定性地解释人类语音学习的行为数据,并为未来的实验得出预测。