Centre for GeoGenetics, Natural History Museum of Denmark, University of Copenhagen, Oestervoldgade 5-7, DK-1350, Copenhagen, Denmark.
BMC Bioinformatics. 2013 Oct 2;14:289. doi: 10.1186/1471-2105-14-289.
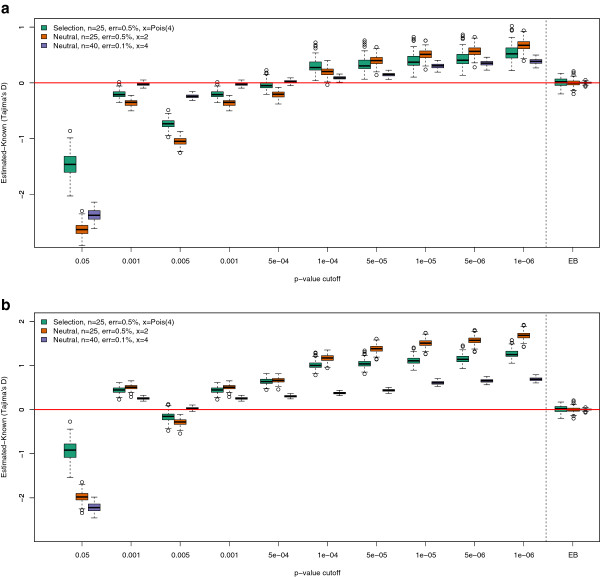
A number of different statistics are used for detecting natural selection using DNA sequencing data, including statistics that are summaries of the frequency spectrum, such as Tajima's D. These statistics are now often being applied in the analysis of Next Generation Sequencing (NGS) data. However, estimates of frequency spectra from NGS data are strongly affected by low sequencing coverage; the inherent technology dependent variation in sequencing depth causes systematic differences in the value of the statistic among genomic regions.
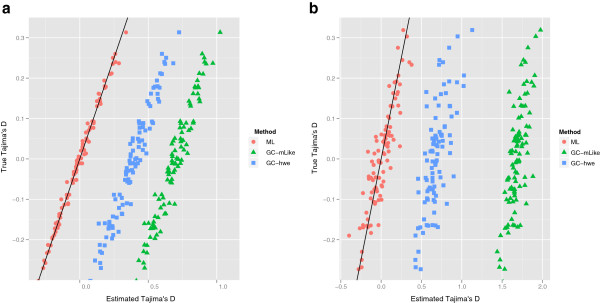
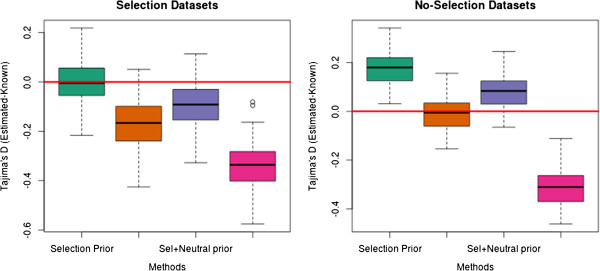
We have developed an approach that accommodates the uncertainty of the data when calculating site frequency based neutrality test statistics. A salient feature of this approach is that it implicitly solves the problems of varying sequencing depth, missing data and avoids the need to infer variable sites for the analysis and thereby avoids ascertainment problems introduced by a SNP discovery process.
Using an empirical Bayes approach for fast computations, we show that this method produces results for low-coverage NGS data comparable to those achieved when the genotypes are known without uncertainty. We also validate the method in an analysis of data from the 1000 genomes project. The method is implemented in a fast framework which enables researchers to perform these neutrality tests on a genome-wide scale.
许多不同的统计数据被用于使用 DNA 测序数据检测自然选择,包括对频谱进行总结的统计数据,如 Tajima 的 D。这些统计数据现在经常被应用于下一代测序(NGS)数据的分析。然而,NGS 数据中频谱的估计受到低测序覆盖度的强烈影响;测序深度固有的依赖技术的变化导致统计数据在基因组区域之间的系统差异。
我们开发了一种方法,在计算基于位点频率的中性测试统计数据时,考虑到数据的不确定性。该方法的一个显著特点是,它隐式地解决了测序深度变化、缺失数据的问题,避免了为分析推断可变位点的需要,从而避免了 SNP 发现过程中引入的确定问题。
我们使用经验贝叶斯方法进行快速计算,结果表明,对于低覆盖 NGS 数据,该方法的结果与基因型不确定时的结果相当。我们还在对 1000 个基因组项目数据的分析中验证了该方法。该方法在一个快速的框架中实现,使研究人员能够在全基因组范围内进行这些中性测试。