Zuo Xiaoyu, Rao Shaoqi, Fan An, Lin Meihua, Li Haoli, Zhao Xiaolei, Qin Jiheng
Department of Medical Statistics and Epidemiology, Sun Yat-Sen University, Guangzhou, China.
PLoS One. 2013 Dec 10;8(12):e81984. doi: 10.1371/journal.pone.0081984. eCollection 2013.
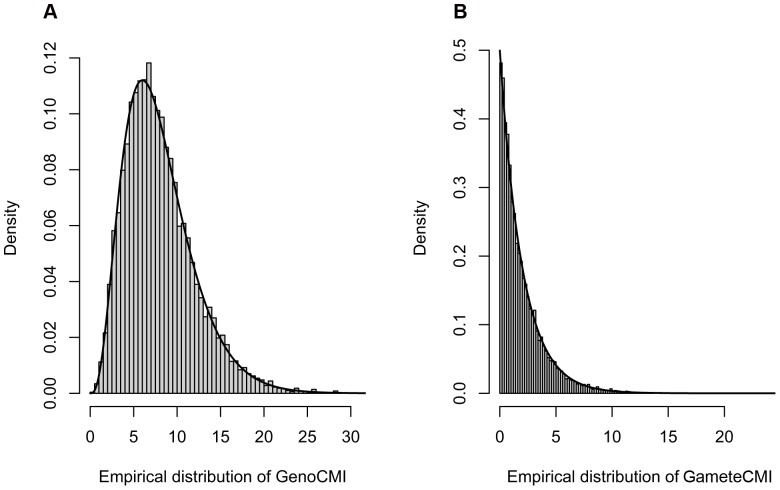
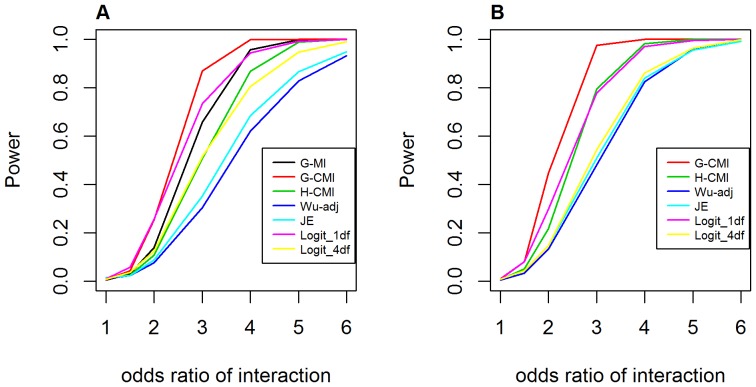
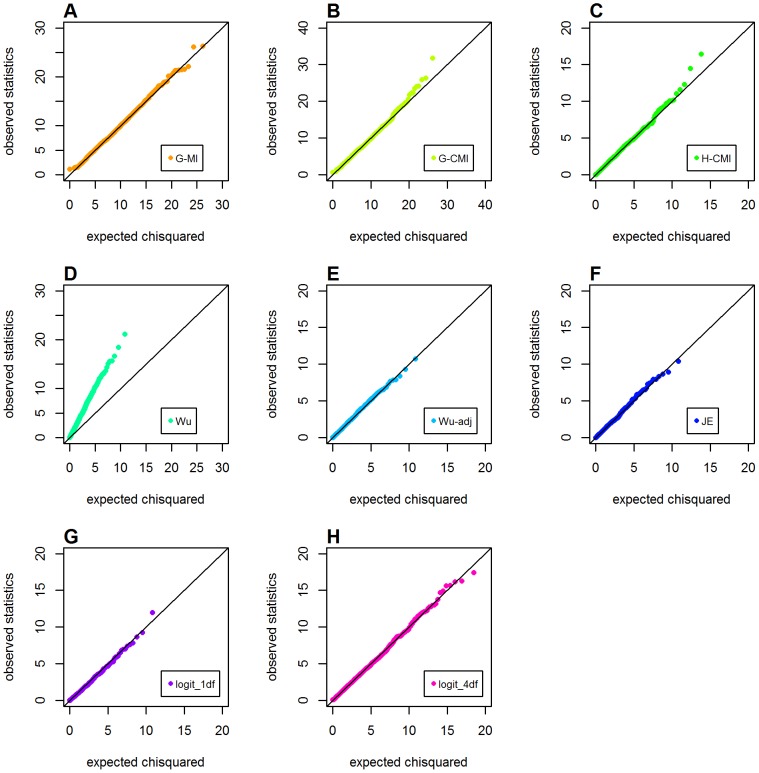
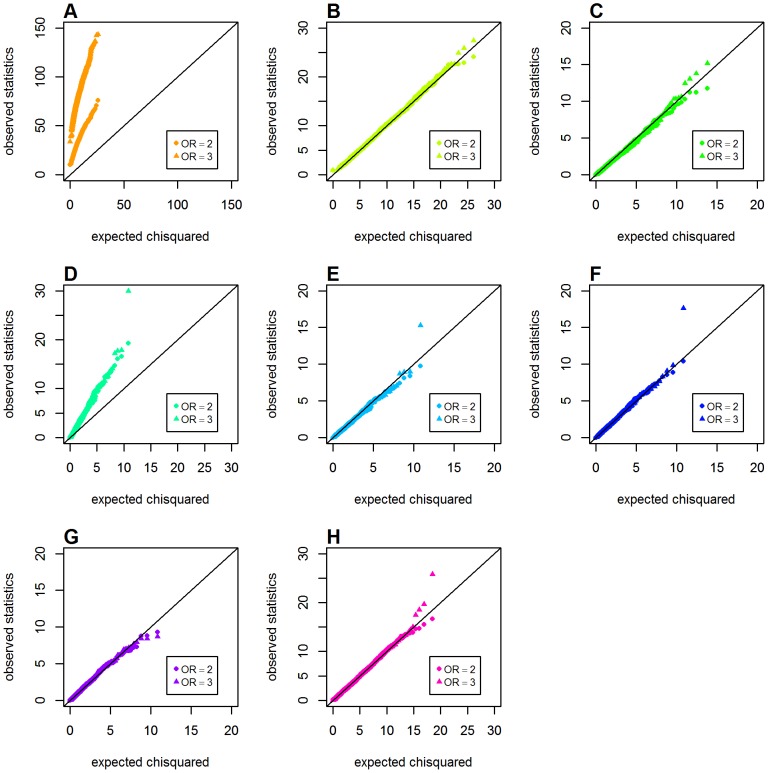
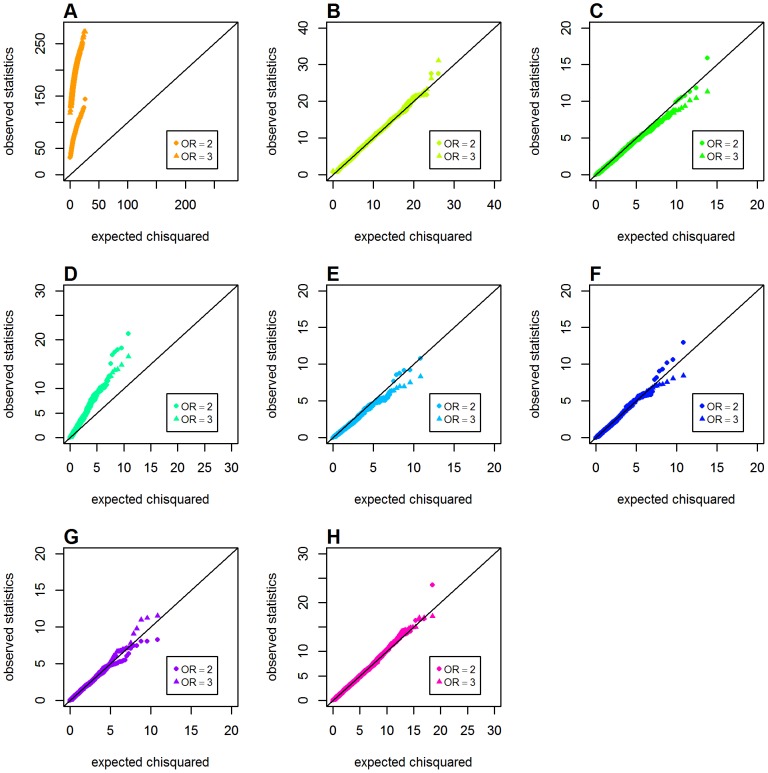
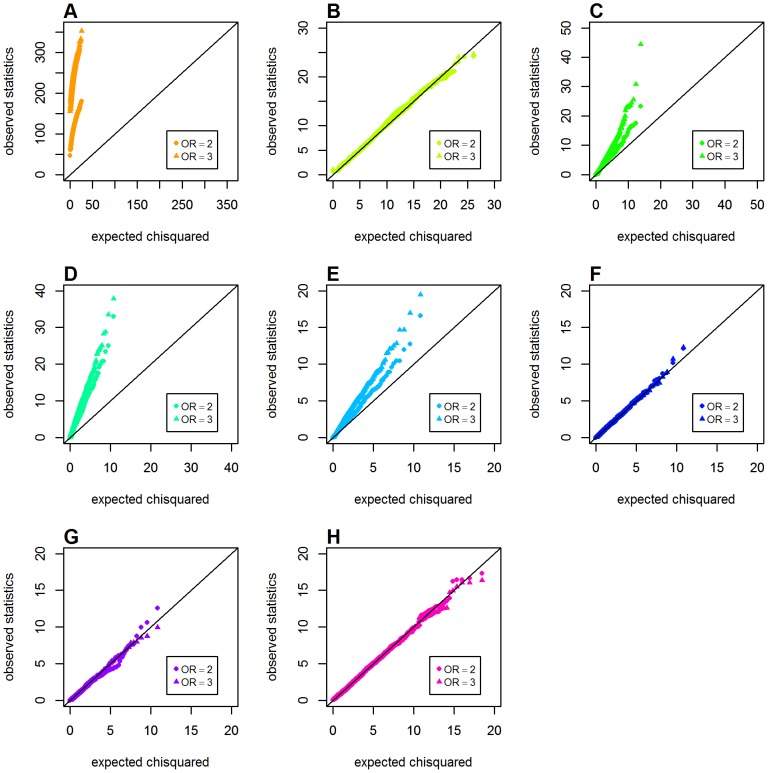
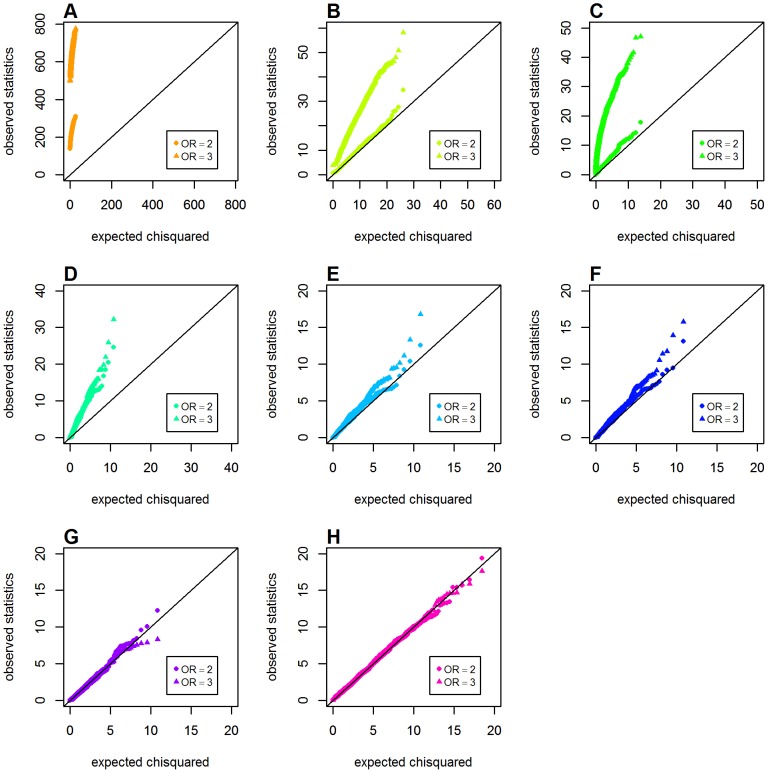
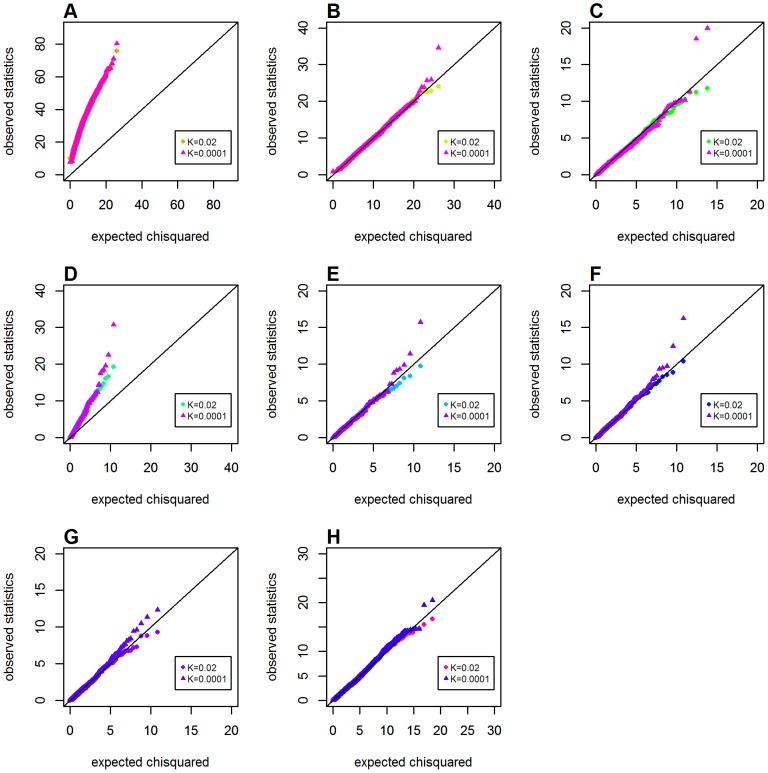
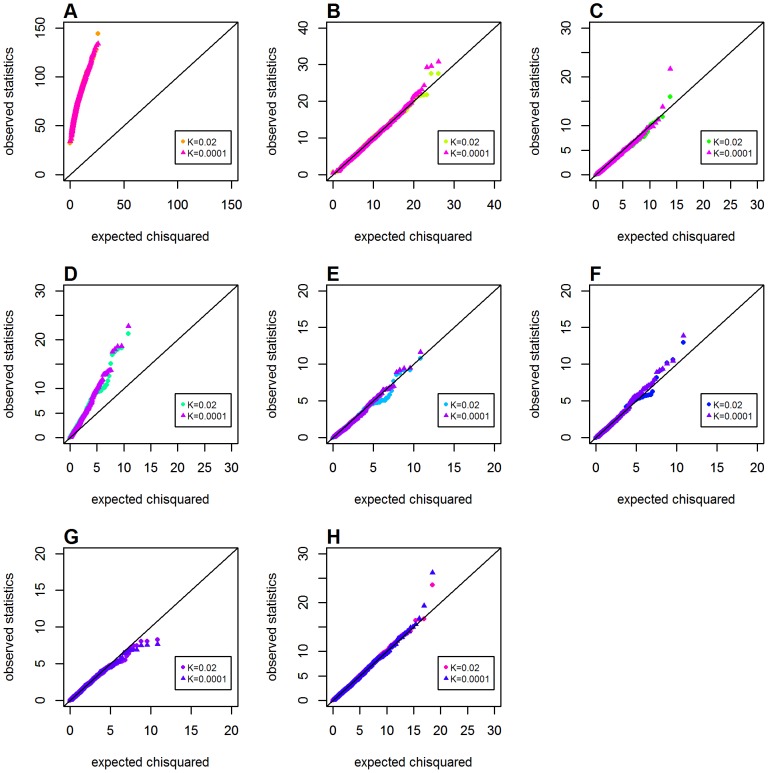
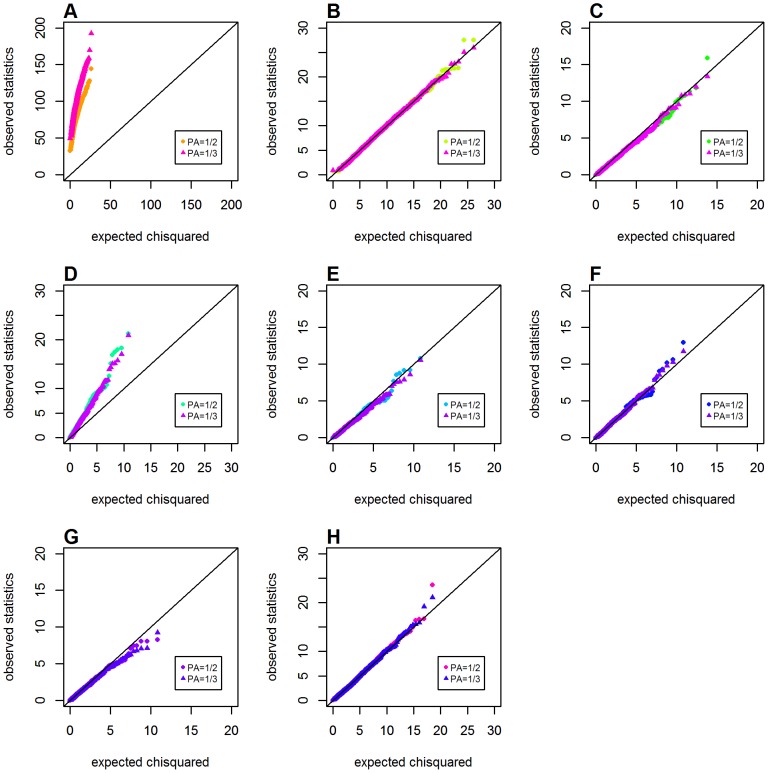
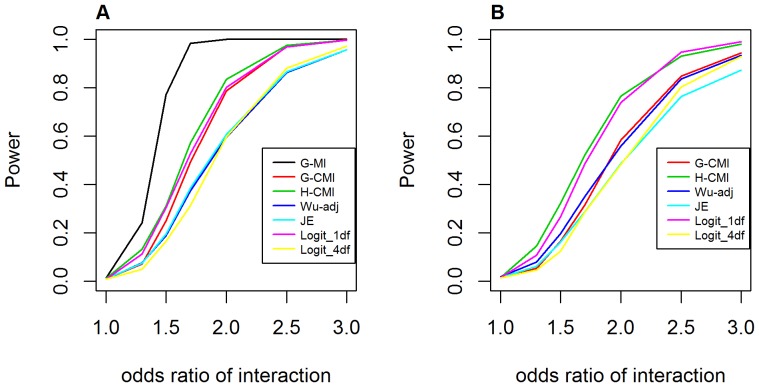
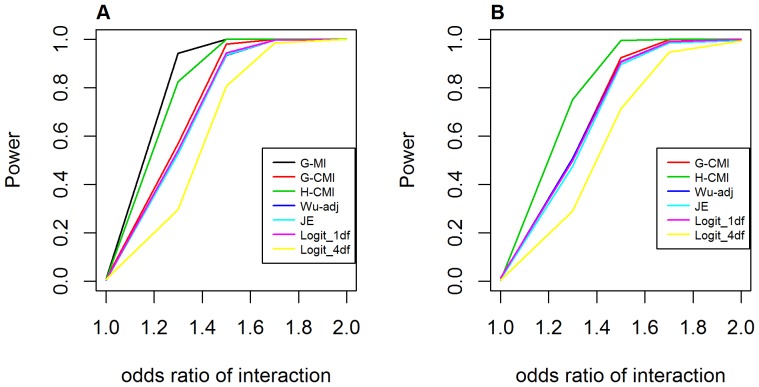
Genome-wide analysis of gene-gene interactions has been recognized as a powerful avenue to identify the missing genetic components that can not be detected by using current single-point association analysis. Recently, several model-free methods (e.g. the commonly used information based metrics and several logistic regression-based metrics) were developed for detecting non-linear dependence between genetic loci, but they are potentially at the risk of inflated false positive error, in particular when the main effects at one or both loci are salient. In this study, we proposed two conditional entropy-based metrics to challenge this limitation. Extensive simulations demonstrated that the two proposed metrics, provided the disease is rare, could maintain consistently correct false positive rate. In the scenarios for a common disease, our proposed metrics achieved better or comparable control of false positive error, compared to four previously proposed model-free metrics. In terms of power, our methods outperformed several competing metrics in a range of common disease models. Furthermore, in real data analyses, both metrics succeeded in detecting interactions and were competitive with the originally reported results or the logistic regression approaches. In conclusion, the proposed conditional entropy-based metrics are promising as alternatives to current model-based approaches for detecting genuine epistatic effects.
基因-基因相互作用的全基因组分析已被公认为是一种强大的途径,可用于识别那些通过当前单点关联分析无法检测到的缺失遗传成分。最近,人们开发了几种无模型方法(例如常用的基于信息的指标和几种基于逻辑回归的指标)来检测基因座之间的非线性依赖性,但它们存在假阳性错误率虚高的风险,尤其是当一个或两个基因座的主效应显著时。在本研究中,我们提出了两种基于条件熵的指标来应对这一局限性。大量模拟表明,所提出的两种指标在疾病罕见的情况下能够始终保持正确的假阳性率。在常见疾病的情形中,与之前提出的四种无模型指标相比,我们提出的指标在控制假阳性错误方面表现更好或相当。在效能方面,我们的方法在一系列常见疾病模型中优于其他几种竞争指标。此外,在实际数据分析中两种指标都成功检测到了相互作用,并且与最初报道的结果或逻辑回归方法相比具有竞争力。总之,所提出的基于条件熵的指标有望成为当前基于模型的方法的替代方法,用于检测真正的上位性效应。