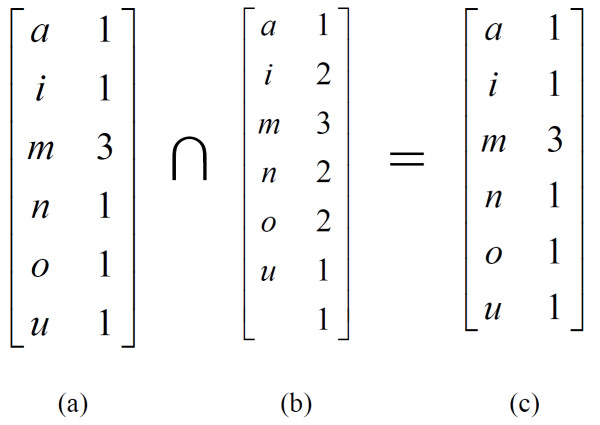Department of Library and Information Science, Yonsei University, 50 Yonsei-ro, Seoul 120-749, Korea.
BMC Bioinformatics. 2014 Jun 14;15:187. doi: 10.1186/1471-2105-15-187.
The significant growth in the volume of electronic biomedical data in recent decades has pointed to the need for approximate string matching algorithms that can expedite tasks such as named entity recognition, duplicate detection, terminology integration, and spelling correction. The task of source integration in the Unified Medical Language System (UMLS) requires considerable expert effort despite the presence of various computational tools. This problem warrants the search for a new method for approximate string matching and its UMLS-based evaluation.
This paper introduces the Longest Approximately Common Prefix (LACP) method as an algorithm for approximate string matching that runs in linear time. We compare the LACP method for performance, precision and speed to nine other well-known string matching algorithms. As test data, we use two multiple-source samples from the Unified Medical Language System (UMLS) and two SNOMED Clinical Terms-based samples. In addition, we present a spell checker based on the LACP method.
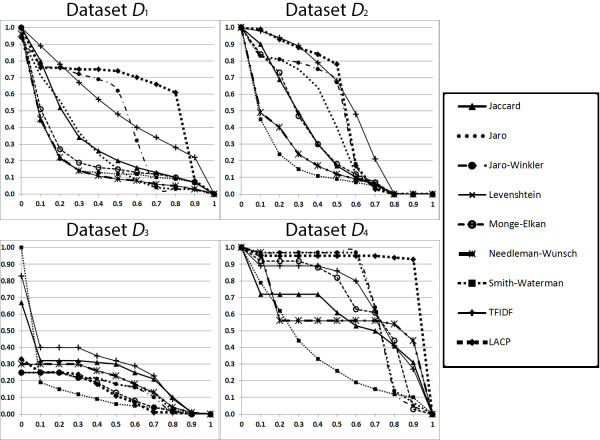
The Longest Approximately Common Prefix method completes its string similarity evaluations in less time than all nine string similarity methods used for comparison. The Longest Approximately Common Prefix outperforms these nine approximate string matching methods in its Maximum F1 measure when evaluated on three out of the four datasets, and in its average precision on two of the four datasets.
近几十年来,电子生物医学数据的数量显著增长,这使得人们需要近似字符串匹配算法,以加速命名实体识别、重复检测、术语集成和拼写纠正等任务。尽管存在各种计算工具,但统一医学语言系统 (UMLS) 的源整合任务仍需要大量的专家努力。因此,需要寻找一种新的近似字符串匹配方法及其基于 UMLS 的评估方法。
本文提出了最长近似公共前缀 (LACP) 方法作为一种近似字符串匹配算法,其运行时间为线性时间。我们将 LACP 方法的性能、精度和速度与其他九种知名的字符串匹配算法进行了比较。作为测试数据,我们使用了来自统一医学语言系统 (UMLS) 的两个多源样本和两个基于 SNOMED Clinical Terms 的样本。此外,我们还展示了一个基于 LACP 方法的拼写检查器。
在四个数据集的三个数据集上,最长近似公共前缀方法在其最大 F1 度量方面优于这九种近似字符串匹配方法,在两个数据集的平均精度方面也优于这九种方法。与用于比较的九种字符串相似度方法相比,最长近似公共前缀方法在完成字符串相似度评估时所需的时间更少。