Lisboa Francy Junio Gonçalves, Peres-Neto Pedro R, Chaer Guilherme Montandon, Jesus Ederson da Conceição, Mitchell Ruth Joy, Chapman Stephen James, Berbara Ricardo Luis Louro
Soil Science Department, Agronomy Institute, Federal Rural University of Rio de Janeiro, Seropédica-RJ, Brazil; The James Hutton Institute, Craigiebuckler, Aberdeen, United Kingdom.
Canada Research Chair in Spatial Modelling and Biodiversity; Université du Québec à Montréal, Département des sciences biologiques, Québec, Canada.
PLoS One. 2014 Jun 27;9(6):e101238. doi: 10.1371/journal.pone.0101238. eCollection 2014.
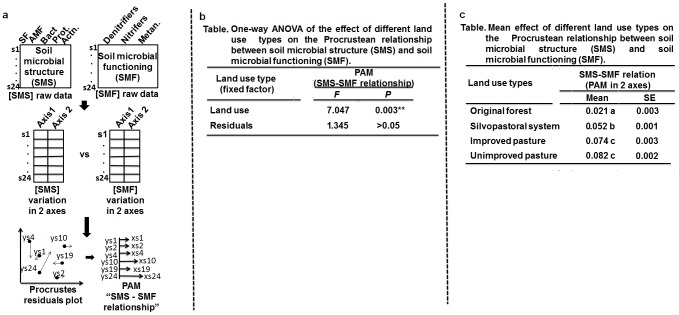
The correlation of multivariate data is a common task in investigations of soil biology and in ecology in general. Procrustes analysis and the Mantel test are two approaches that often meet this objective and are considered analogous in many situations especially when used as a statistical test to assess the statistical significance between multivariate data tables. Here we call the attention of ecologists to the advantages of a less familiar application of the Procrustean framework, namely the Procrustean association metric (a vector of Procrustean residuals). These residuals represent differences in fit between multivariate data tables regarding homologous observations (e.g., sampling sites) that can be used to estimate local levels of association (e.g., some groups of sites are more similar in their association between biotic and environmental features than other groups of sites). Given that in the Mantel framework, multivariate information is translated into a pairwise distance matrix, we lose the ability to contrast homologous data points across dimensions and data matrices after their fit. In this paper, we attempt to familiarize ecologists with the benefits of using these Procrustean residual differences to further gain insights about the processes underlying the association among multivariate data tables using real and hypothetical examples.
多变量数据的相关性分析是土壤生物学研究以及整个生态学研究中的常见任务。普氏分析和曼特尔检验是常用于实现这一目标的两种方法,在许多情况下它们被视为类似方法,尤其是当用作统计检验来评估多变量数据表之间的统计显著性时。在此,我们提请生态学家注意普氏框架一种不太为人熟悉的应用的优势,即普氏关联度量(普氏残差向量)。这些残差表示多变量数据表在同源观测值(例如采样点)方面拟合度的差异,可用于估计局部关联水平(例如,某些采样点组在生物和环境特征之间的关联比其他采样点组更为相似)。鉴于在曼特尔框架中,多变量信息被转化为成对距离矩阵,在拟合之后我们就失去了跨维度和数据矩阵对比同源数据点的能力。在本文中,我们试图通过实际和假设的例子,让生态学家熟悉使用这些普氏残差差异的益处,以便进一步深入了解多变量数据表之间关联背后的过程。