Department of Experimental Psychology, University of Cambridge, UK.
Trends Hear. 2014 Oct 13;18:2331216514550620. doi: 10.1177/2331216514550620.
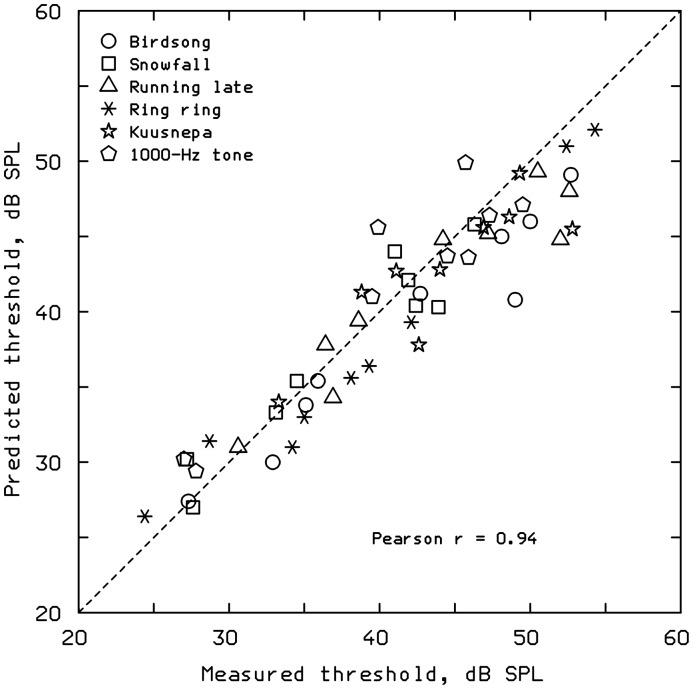
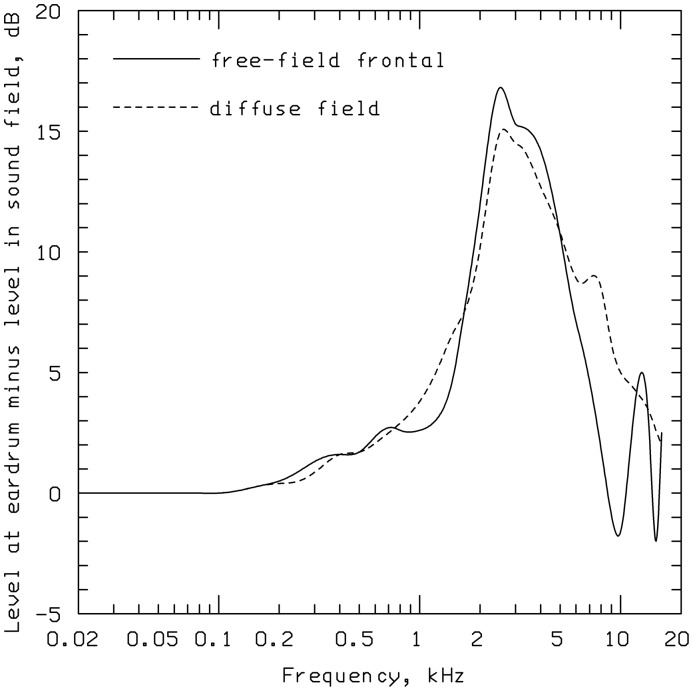
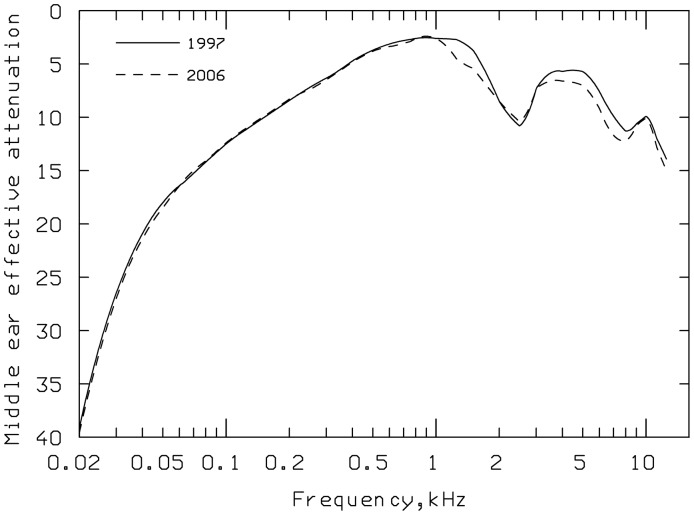
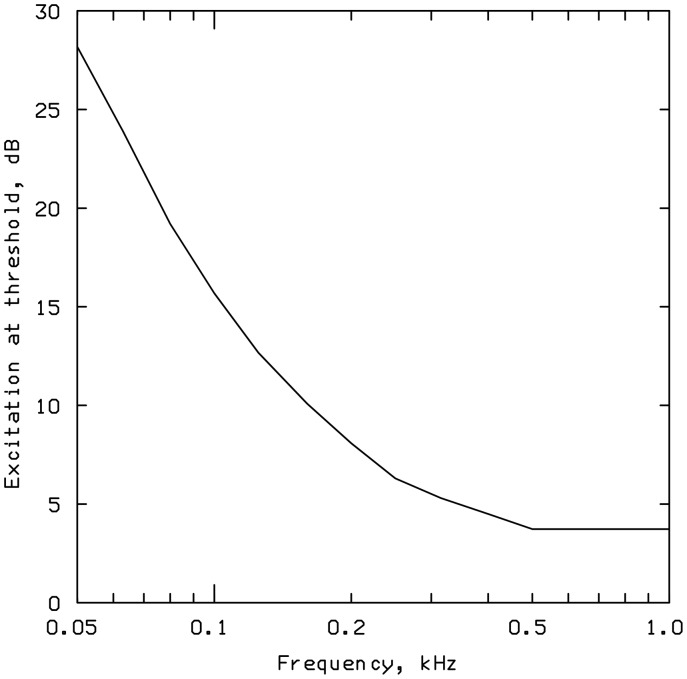
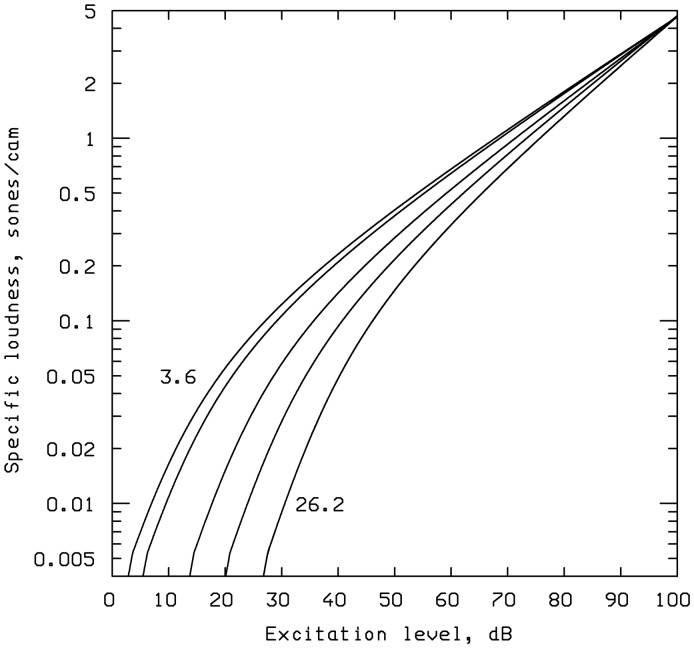
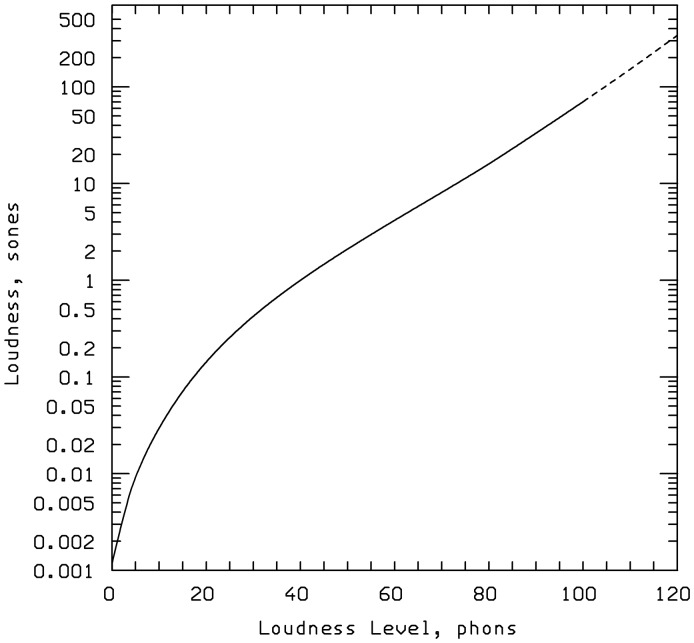
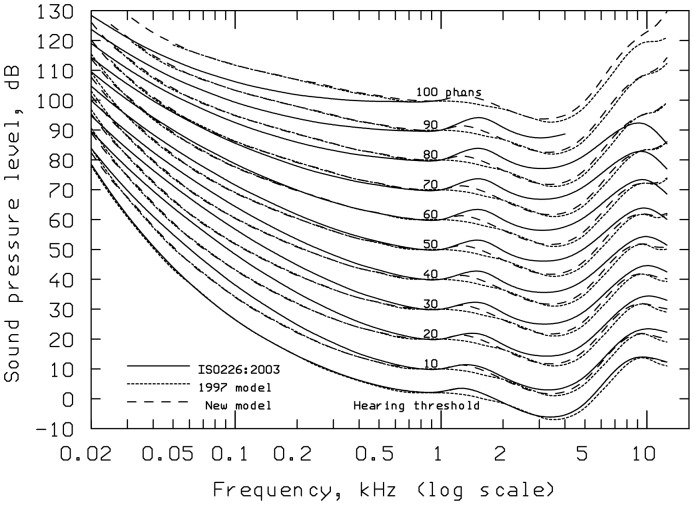
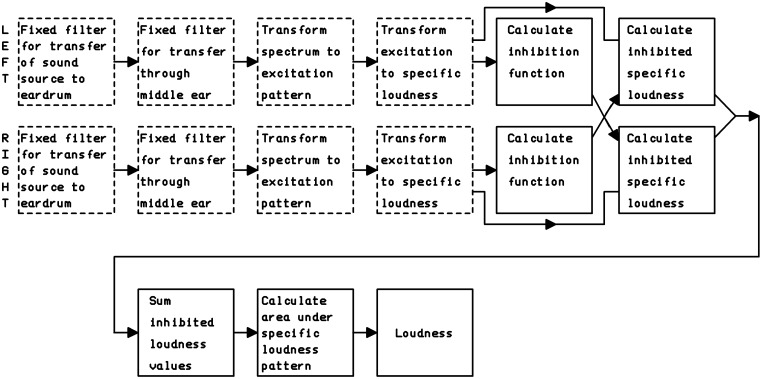
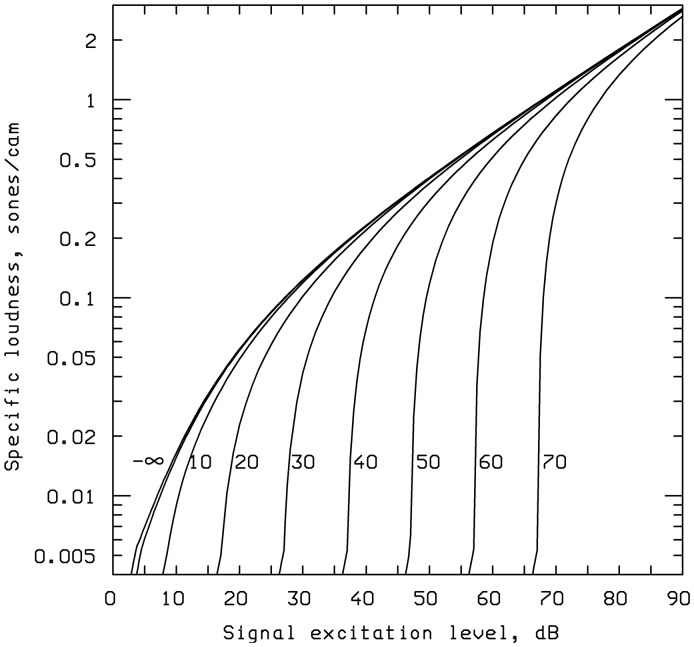
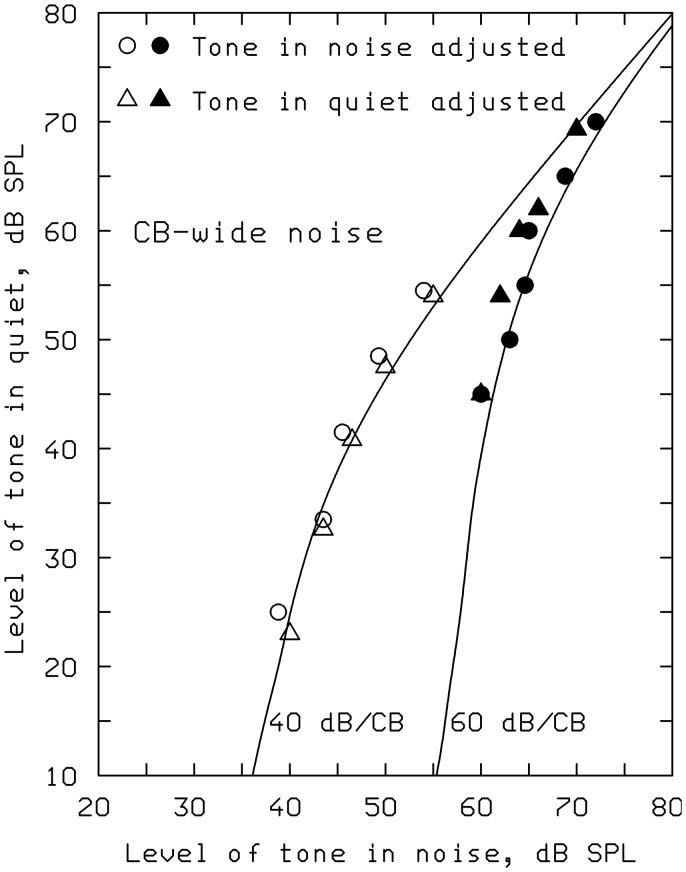
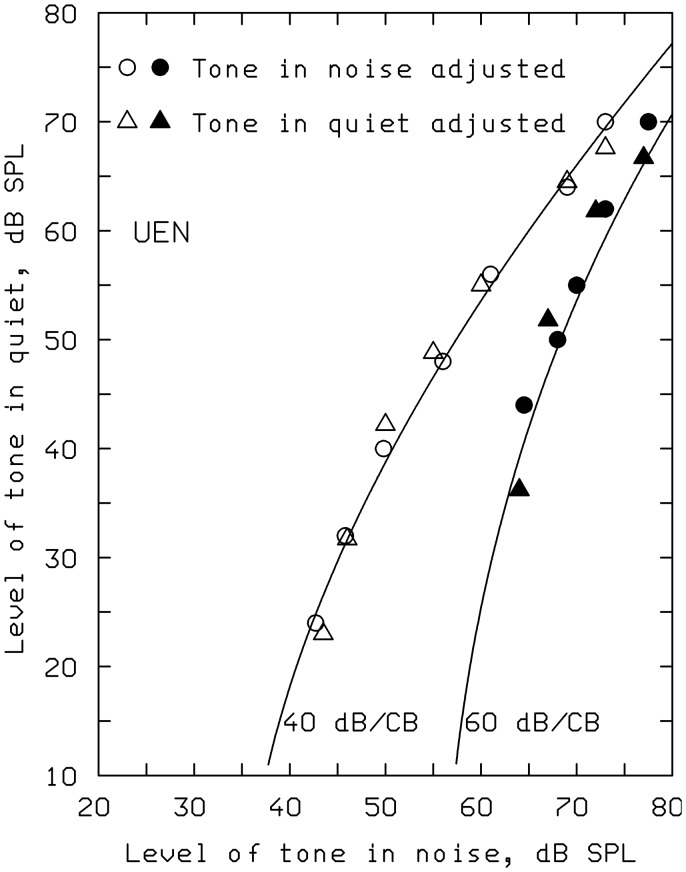
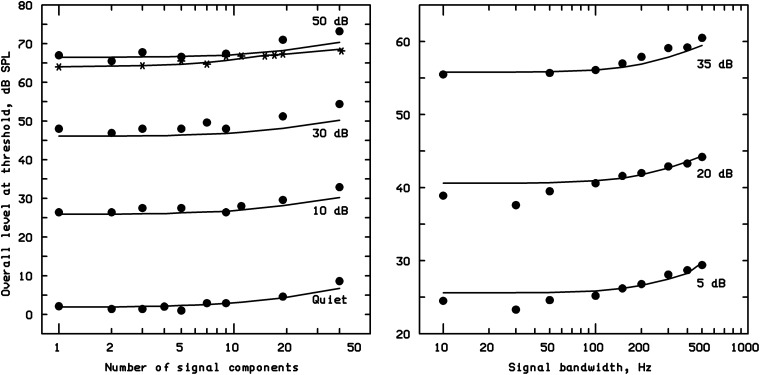
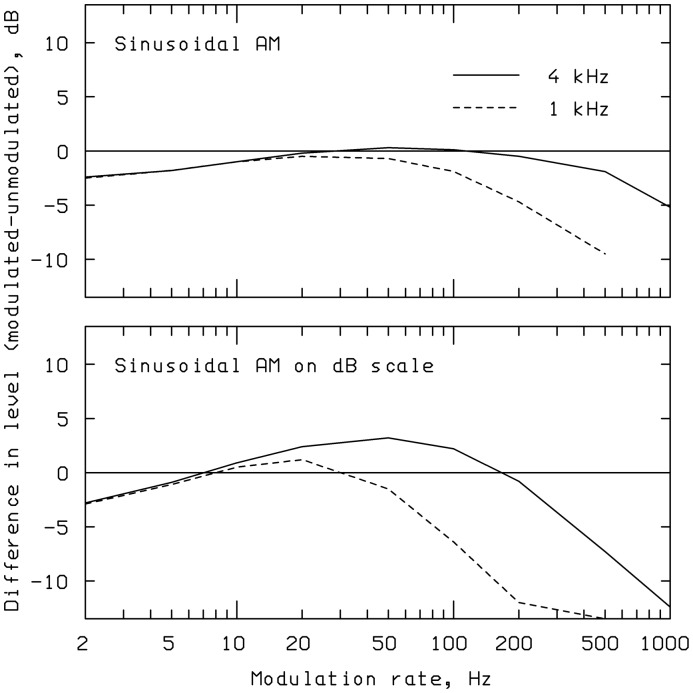
This article reviews the evolution of a series of models of loudness developed in Cambridge, UK. The first model, applicable to stationary sounds, was based on modifications of the model developed by Zwicker, including the introduction of a filter to allow for the effects of transfer of sound through the outer and middle ear prior to the calculation of an excitation pattern, and changes in the way that the excitation pattern was calculated. Later, modifications were introduced to the assumed middle-ear transfer function and to the way that specific loudness was calculated from excitation level. These modifications led to a finite calculated loudness at absolute threshold, which made it possible to predict accurately the absolute thresholds of broadband and narrowband sounds, based on the assumption that the absolute threshold corresponds to a fixed small loudness. The model was also modified to give predictions of partial loudness-the loudness of one sound in the presence of another. This allowed predictions of masked thresholds based on the assumption that the masked threshold corresponds to a fixed small partial loudness. Versions of the model for time-varying sounds were developed, which allowed prediction of the masked threshold of any sound in a background of any other sound. More recent extensions incorporate binaural processing to account for the summation of loudness across ears. In parallel, versions of the model for predicting loudness for hearing-impaired ears have been developed and have been applied to the development of methods for fitting multichannel compression hearing aids.
本文回顾了在英国剑桥开发的一系列响度模型的演变。第一个模型适用于稳态声音,是基于对 Zwicker 开发的模型的修改,包括引入滤波器以允许在计算激励模式之前考虑声音通过外耳和中耳的传输效应,以及修改计算激励模式的方式。后来,对假设的中耳传输函数和从激励水平计算特定响度的方式进行了修改。这些修改导致在绝对阈值处产生有限的计算响度,这使得根据绝对阈值对应于固定小响度的假设,能够准确预测宽带和窄带声音的绝对阈值。该模型还经过修改以提供部分响度的预测——即在另一个声音存在的情况下一个声音的响度。这允许根据掩蔽阈值对应于固定小部分响度的假设,对掩蔽阈值进行预测。为了预测时变声音,开发了该模型的版本,这允许根据任何声音在任何其他声音背景下的掩蔽阈值进行预测。最近的扩展版本包含了双耳处理,以解释双耳响度的总和。与此同时,为预测听力受损耳朵的响度开发了模型的版本,并将其应用于开发多通道压缩助听器的方法。