Kim Seungill, Kim Myung-Shin, Kim Yong-Min, Yeom Seon-In, Cheong Kyeongchae, Kim Ki-Tae, Jeon Jongbum, Kim Sunggil, Kim Do-Sun, Sohn Seong-Han, Lee Yong-Hwan, Choi Doil
Department of Plant Science, Seoul National University, Seoul, Korea Interdisciplinary Program in Agricultural Genomics, Seoul National University, Seoul, Korea.
Korea Bioinformation Center, Korea Research Institute of Bioscience and Biotechnology, Daejon, Korea.
DNA Res. 2015 Feb;22(1):19-27. doi: 10.1093/dnares/dsu035. Epub 2014 Oct 31.
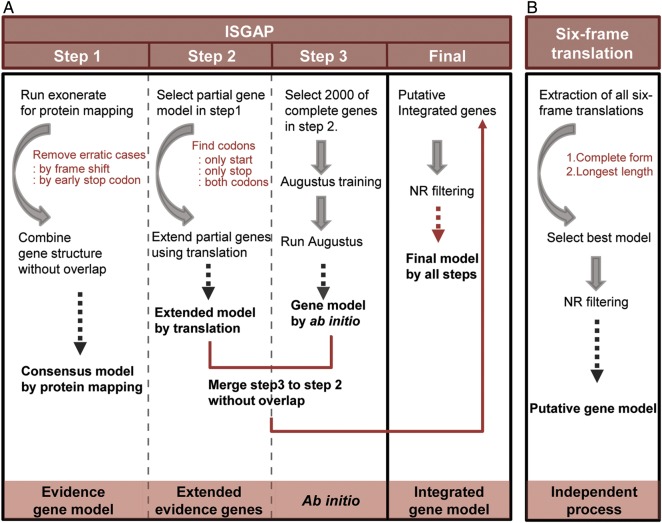
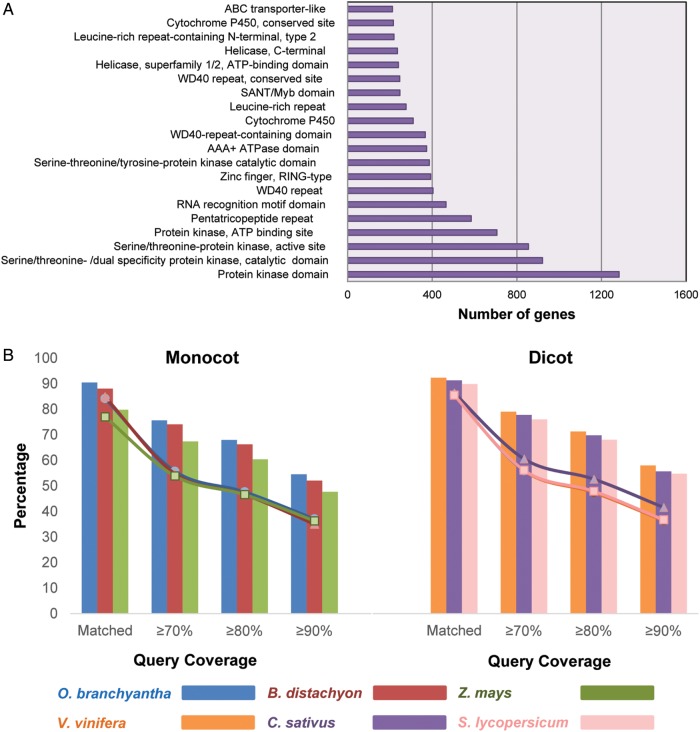
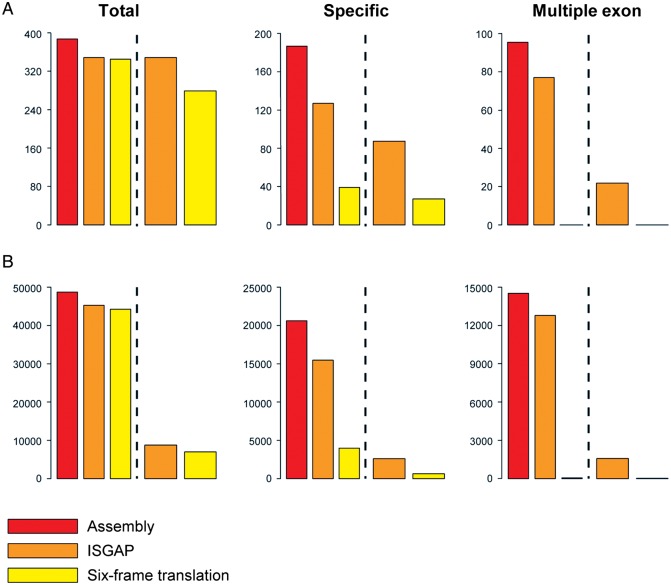
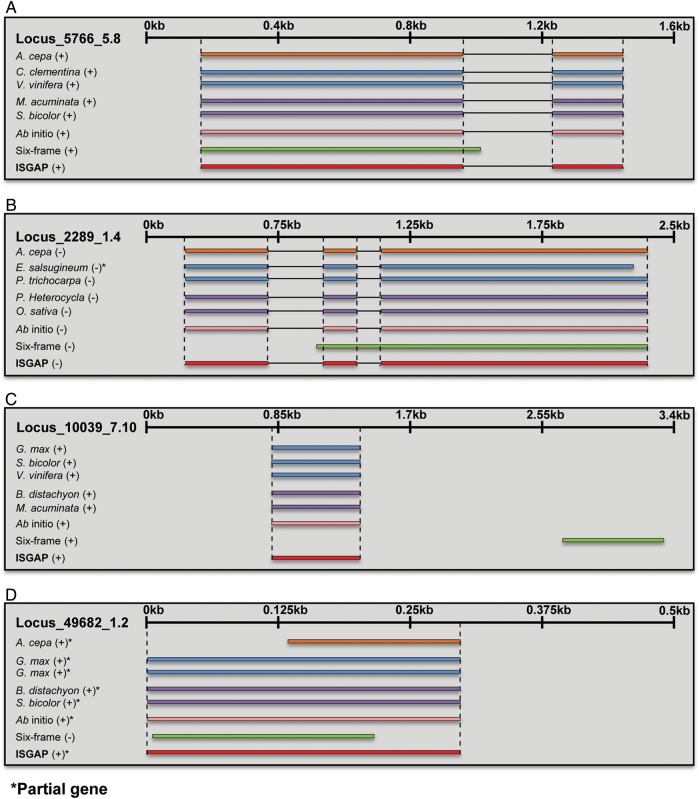
The onion (Allium cepa L.) is one of the most widely cultivated and consumed vegetable crops in the world. Although a considerable amount of onion transcriptome data has been deposited into public databases, the sequences of the protein-coding genes are not accurate enough to be used, owing to non-coding sequences intermixed with the coding sequences. We generated a high-quality, annotated onion transcriptome from de novo sequence assembly and intensive structural annotation using the integrated structural gene annotation pipeline (ISGAP), which identified 54,165 protein-coding genes among 165,179 assembled transcripts totalling 203.0 Mb by eliminating the intron sequences. ISGAP performed reliable annotation, recognizing accurate gene structures based on reference proteins, and ab initio gene models of the assembled transcripts. Integrative functional annotation and gene-based SNP analysis revealed a whole biological repertoire of genes and transcriptomic variation in the onion. The method developed in this study provides a powerful tool for the construction of reference gene sets for organisms based solely on de novo transcriptome data. Furthermore, the reference genes and their variation described here for the onion represent essential tools for molecular breeding and gene cloning in Allium spp.
洋葱(Allium cepa L.)是世界上种植和消费最为广泛的蔬菜作物之一。尽管已有大量洋葱转录组数据存入公共数据库,但由于编码序列中混杂着非编码序列,蛋白质编码基因的序列准确性不足以供使用。我们使用综合结构基因注释流程(ISGAP),通过从头序列组装和密集的结构注释,生成了高质量的、有注释的洋葱转录组。该流程通过去除内含子序列,在总计203.0 Mb的165,179个组装转录本中鉴定出54,165个蛋白质编码基因。ISGAP基于参考蛋白质以及组装转录本的从头基因模型,进行了可靠的注释,识别出准确的基因结构。综合功能注释和基于基因的单核苷酸多态性分析揭示了洋葱基因的完整生物学特征和转录组变异。本研究中开发的方法为仅基于从头转录组数据构建生物体参考基因集提供了一个强大的工具。此外,这里描述的洋葱参考基因及其变异是葱属植物分子育种和基因克隆的重要工具。