Peters Shanan E, Zhang Ce, Livny Miron, Ré Christopher
Department of Geoscience, University of Wisconsin-Madison, Madison, Wisconsin, United States of America.
Computer Sciences Department, University of Wisconsin-Madison, Madison, Wisconsin, United States of America.
PLoS One. 2014 Dec 1;9(12):e113523. doi: 10.1371/journal.pone.0113523. eCollection 2014.
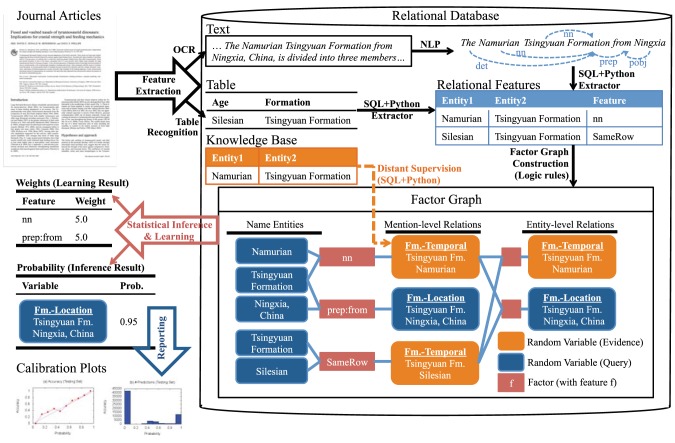
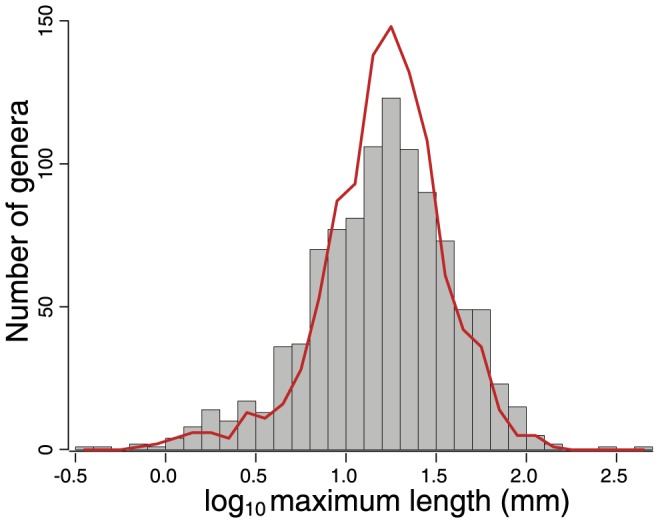
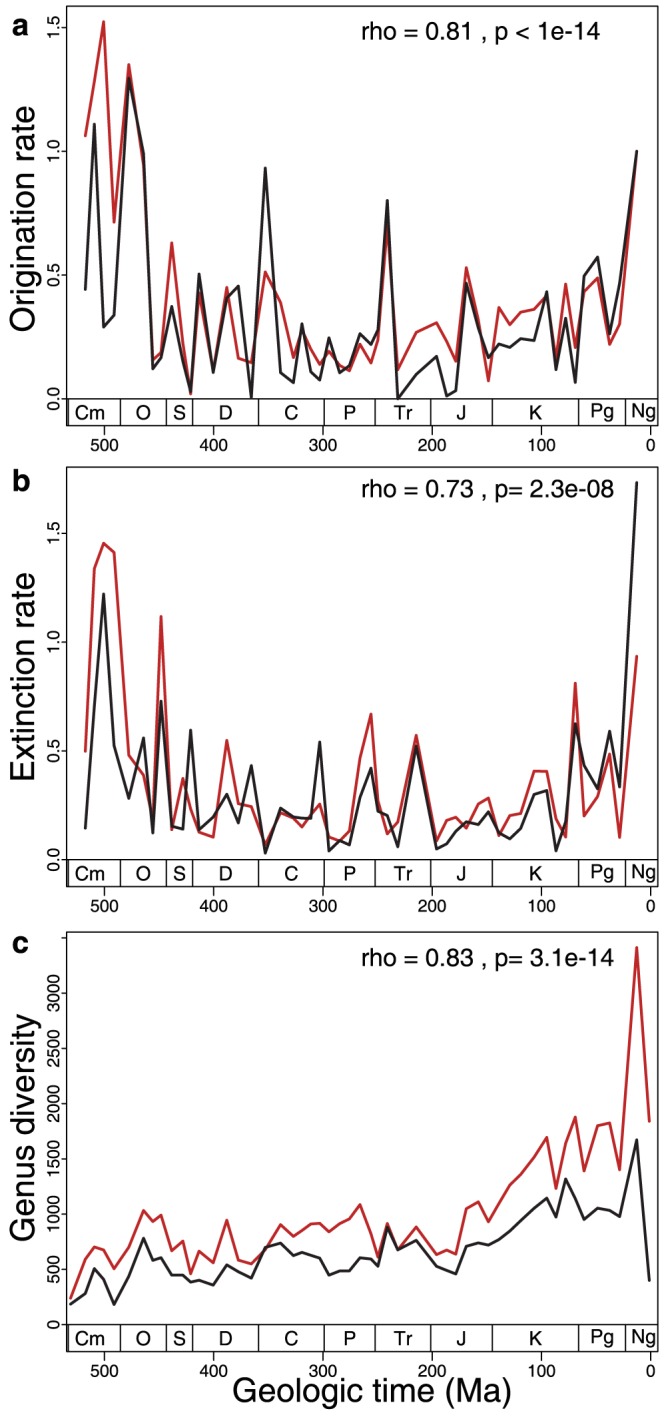
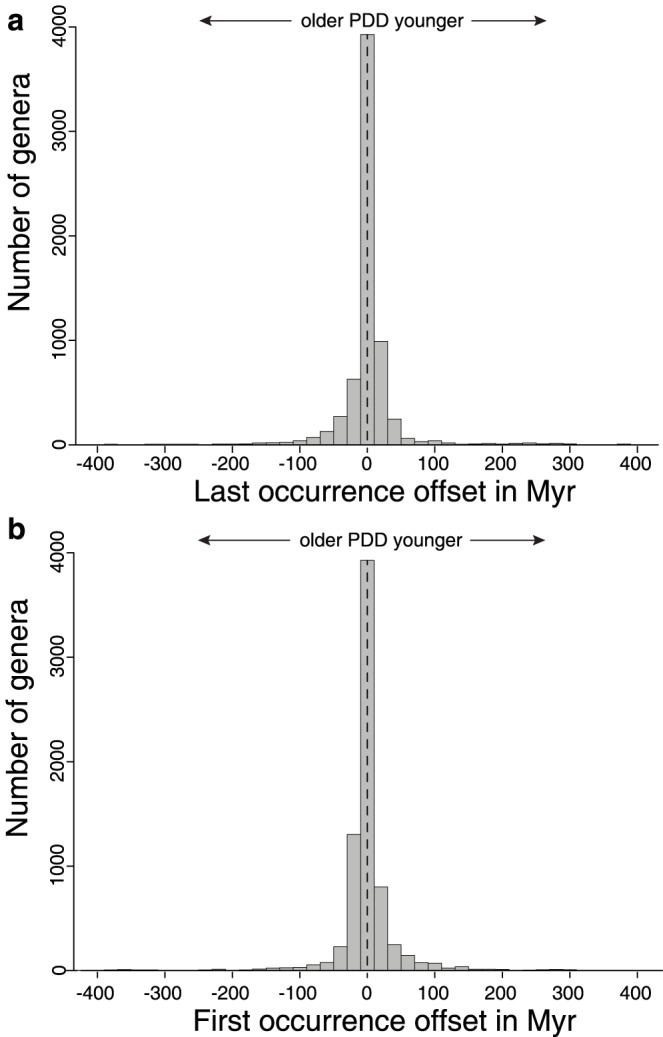
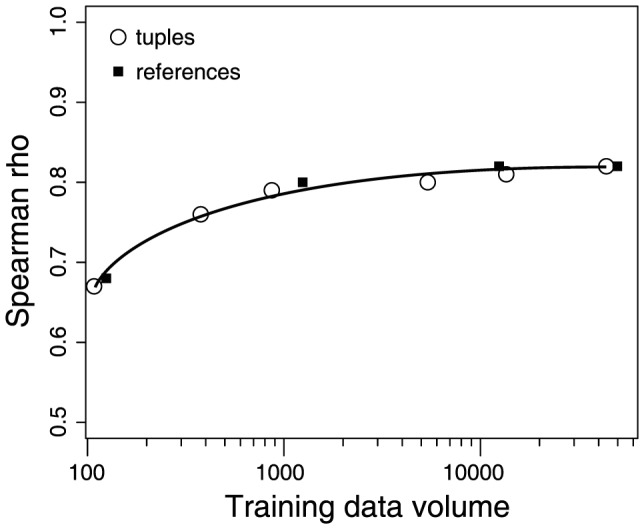
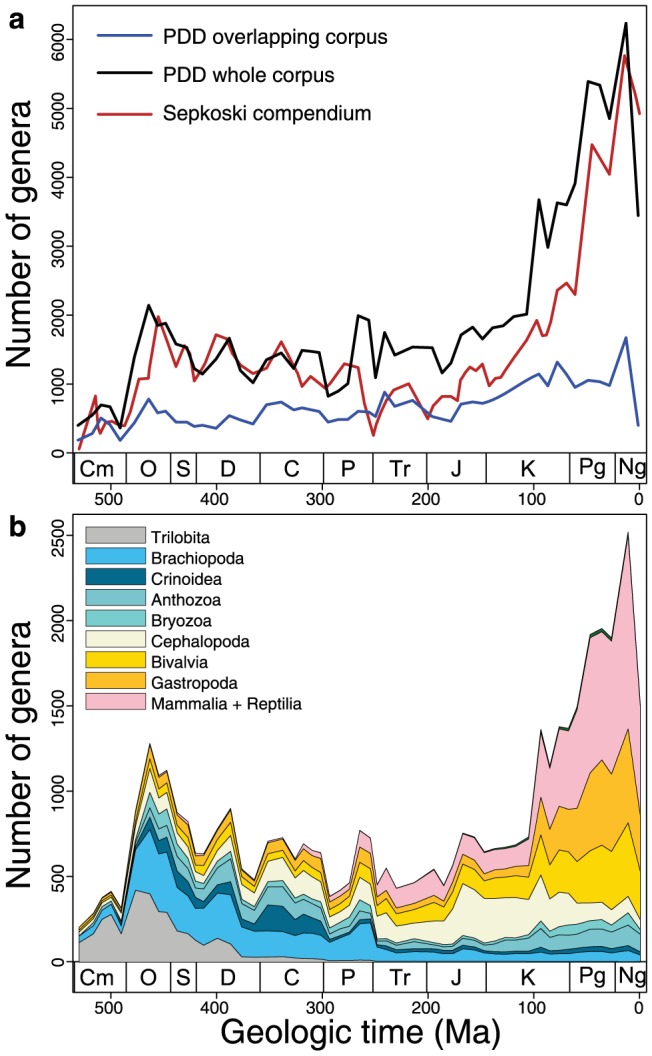
Many aspects of macroevolutionary theory and our understanding of biotic responses to global environmental change derive from literature-based compilations of paleontological data. Existing manually assembled databases are, however, incomplete and difficult to assess and enhance with new data types. Here, we develop and validate the quality of a machine reading system, PaleoDeepDive, that automatically locates and extracts data from heterogeneous text, tables, and figures in publications. PaleoDeepDive performs comparably to humans in several complex data extraction and inference tasks and generates congruent synthetic results that describe the geological history of taxonomic diversity and genus-level rates of origination and extinction. Unlike traditional databases, PaleoDeepDive produces a probabilistic database that systematically improves as information is added. We show that the system can readily accommodate sophisticated data types, such as morphological data in biological illustrations and associated textual descriptions. Our machine reading approach to scientific data integration and synthesis brings within reach many questions that are currently underdetermined and does so in ways that may stimulate entirely new modes of inquiry.
宏观进化理论的许多方面以及我们对生物对全球环境变化反应的理解都源于基于文献的古生物学数据汇编。然而,现有的手动汇编数据库并不完整,难以用新的数据类型进行评估和扩充。在此,我们开发并验证了一种机器阅读系统PaleoDeepDive的质量,该系统能自动从出版物中的异构文本、表格和图表中定位并提取数据。在几个复杂的数据提取和推理任务中,PaleoDeepDive的表现与人类相当,并生成了一致的综合结果,这些结果描述了分类多样性的地质历史以及属级别的起源和灭绝速率。与传统数据库不同,PaleoDeepDive生成一个概率数据库,随着信息的添加,该数据库会系统地改进。我们表明,该系统能够轻松容纳复杂的数据类型,比如生物插图中的形态学数据以及相关的文本描述。我们用于科学数据整合与综合的机器阅读方法使得许多目前尚未确定的问题变得可以解决,并且能够以可能激发全新探究模式的方式做到这一点。