Ghosh Debashis, Li Song
Department of Biostatistics and Informatics, Colorado School of Public Health, Aurora, CO, USA.
Duke Institute for Genome Sciences and Policy, Duke University, Durham, NC, USA.
Cancer Inform. 2014 Oct 15;13(Suppl 4):25-33. doi: 10.4137/CIN.S13969. eCollection 2014.
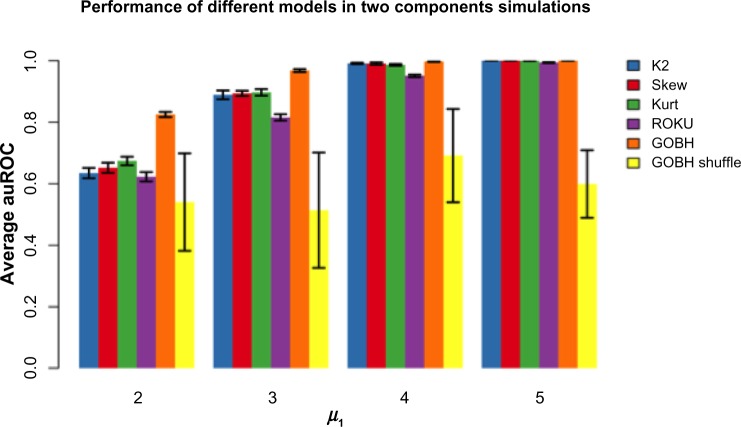
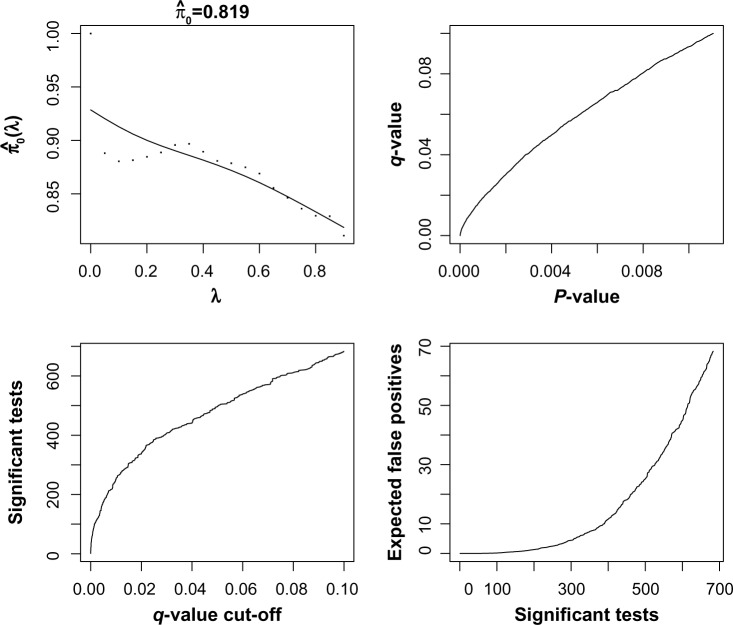
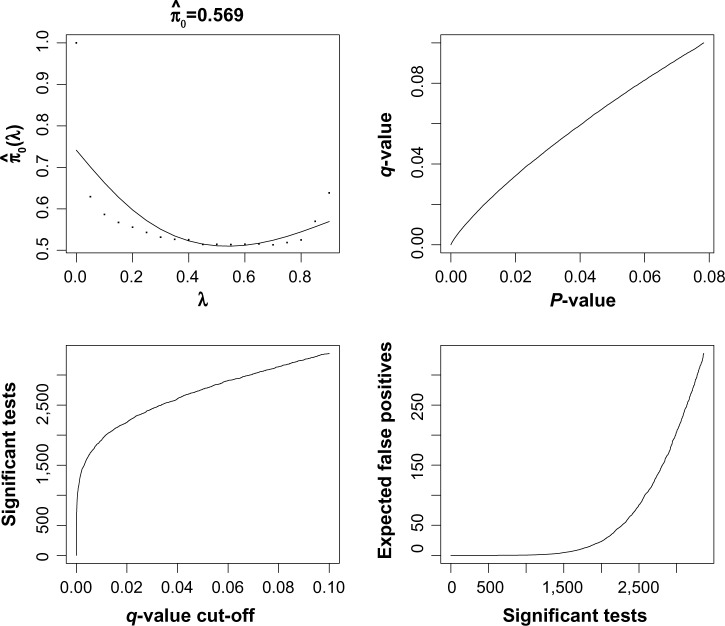
In much of the analysis of high-throughput genomic data, "interesting" genes have been selected based on assessment of differential expression between two groups or generalizations thereof. Most of the literature focuses on changes in mean expression or the entire distribution. In this article, we explore the use of C(α) tests, which have been applied in other genomic data settings. Their use for the outlier expression problem, in particular with continuous data, is problematic but nevertheless motivates new statistics that give an unsupervised analog to previously developed outlier profile analysis approaches. Some simulation studies are used to evaluate the proposal. A bivariate extension is described that can accommodate data from two platforms on matched samples. The proposed methods are applied to data from a prostate cancer study.
在许多高通量基因组数据分析中,“有趣的”基因是根据两组之间差异表达的评估或其概括来选择的。大多数文献关注的是平均表达的变化或整个分布。在本文中,我们探讨了C(α)检验的应用,该检验已应用于其他基因组数据设置中。它们用于异常值表达问题,特别是对于连续数据,存在问题,但仍然激发了新的统计方法,这些方法给出了与先前开发的异常值概况分析方法类似的无监督方法。一些模拟研究用于评估该提议。描述了一种双变量扩展,它可以适应来自匹配样本的两个平台的数据。所提出的方法应用于前列腺癌研究的数据。