Kuan Pei-Fen
Departments of Applied Mathematics and Statistics, Stony Brook University, Stony Brook, NY, USA.
Cancer Inform. 2014 Oct 29;13(Suppl 7):1-10. doi: 10.4137/CIN.S16352. eCollection 2014.
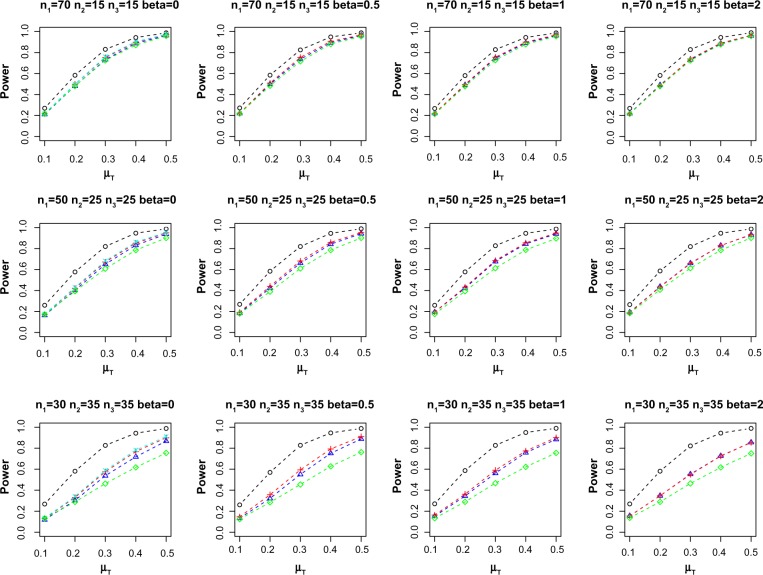
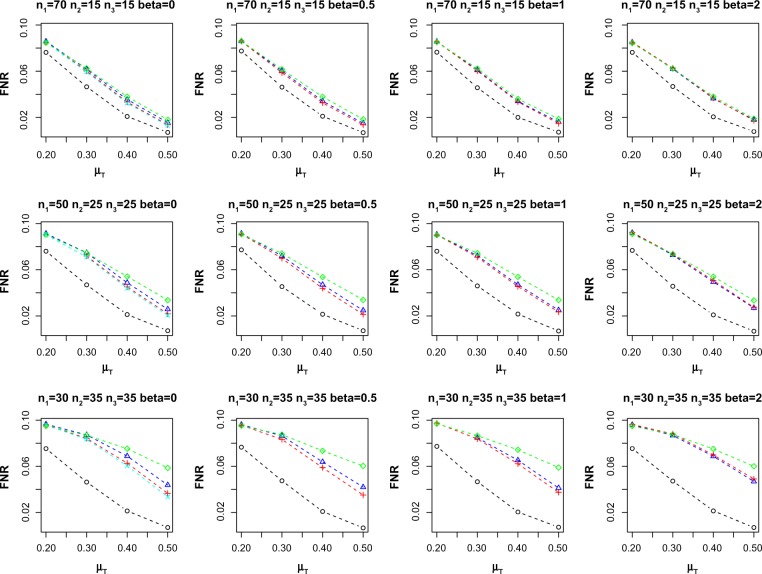
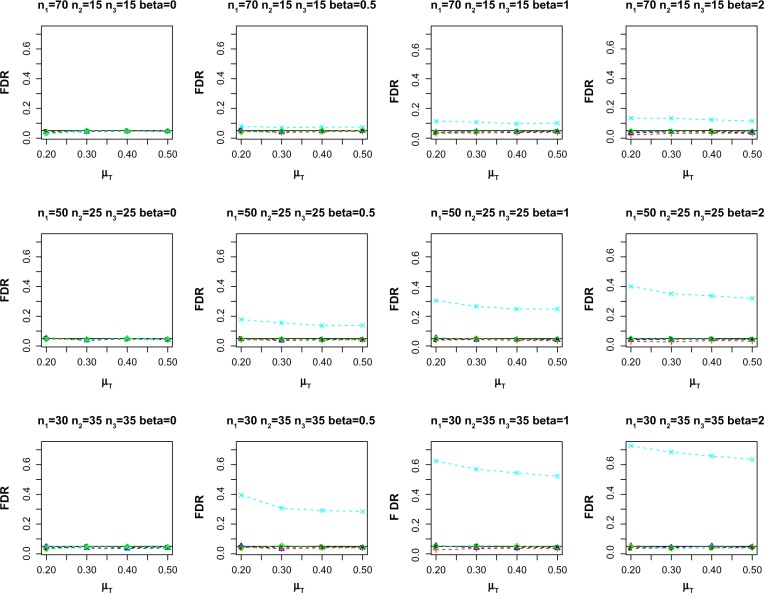
This paper focuses on the problem of partially matched samples in the presence of confounders. We propose using propensity score matching to adjust for confounding factors for the subset of data with incomplete pairs, followed by integrating the P-values computed from the complete and incomplete paired samples, respectively. Several simulations and a case study on DNA methylation are considered to evaluate the operating characteristics of the proposed method.
本文聚焦于存在混杂因素时部分匹配样本的问题。我们建议使用倾向得分匹配来调整不完全配对数据子集中的混杂因素,随后分别整合从完全配对和不完全配对样本计算出的P值。通过若干模拟以及一项关于DNA甲基化的案例研究来评估所提方法的操作特性。