Vavoulis Dimitrios V, Francescatto Margherita, Heutink Peter, Gough Julian
Genome Biol. 2015 Feb 20;16(1):39. doi: 10.1186/s13059-015-0604-6.
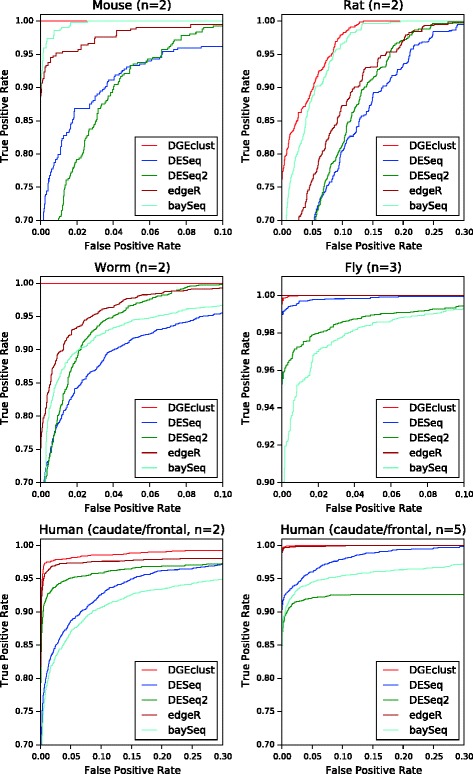
We present a statistical methodology, DGEclust, for differential expression analysis of digital expression data. Our method treats differential expression as a form of clustering, thus unifying these two concepts. Furthermore, it simultaneously addresses the problem of how many clusters are supported by the data and uncertainty in parameter estimation. DGEclust successfully identifies differentially expressed genes under a number of different scenarios, maintaining a low error rate and an excellent control of its false discovery rate with reasonable computational requirements. It is formulated to perform particularly well on low-replicated data and be applicable to multi-group data. DGEclust is available at http://dvav.github.io/dgeclust/.
我们提出了一种用于数字表达数据差异表达分析的统计方法DGEclust。我们的方法将差异表达视为一种聚类形式,从而统一了这两个概念。此外,它同时解决了数据支持多少个聚类以及参数估计中的不确定性问题。DGEclust在许多不同情况下都能成功识别差异表达基因,保持较低的错误率,并能很好地控制其错误发现率,同时具有合理的计算要求。它被设计为在低重复数据上表现特别出色,并且适用于多组数据。可在http://dvav.github.io/dgeclust/获取DGEclust。