Wang Yi-Chia, Kraut Robert E, Levine John M
Language Technologies Institute, School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, United States.
J Med Internet Res. 2015 Apr 20;17(4):e99. doi: 10.2196/jmir.3558.
Although many people with serious diseases participate in online support communities, little research has investigated how participants elicit and provide social support on these sites.
The first goal was to propose and test a model of the dynamic process through which participants in online support communities elicit and provide emotional and informational support. The second was to demonstrate the value of computer coding of conversational data using machine learning techniques (1) by replicating results derived from human-coded data about how people elicit support and (2) by answering questions that are intractable with small samples of human-coded data, namely how exposure to different types of social support predicts continued participation in online support communities. The third was to provide a detailed description of these machine learning techniques to enable other researchers to perform large-scale data analysis in these communities.
Communication among approximately 90,000 registered users of an online cancer support community was analyzed. The corpus comprised 1,562,459 messages organized into 68,158 discussion threads. Amazon Mechanical Turk workers coded (1) 1000 thread-starting messages on 5 attributes (positive and negative emotional self-disclosure, positive and negative informational self-disclosure, questions) and (2) 1000 replies on emotional and informational support. Their judgments were used to train machine learning models that automatically estimated the amount of these 7 attributes in the messages. Across attributes, the average Pearson correlation between human-based judgments and computer-based judgments was .65.
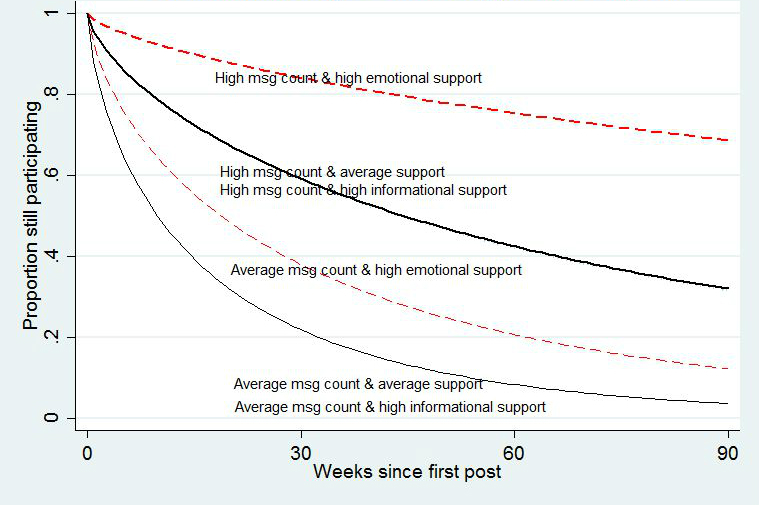
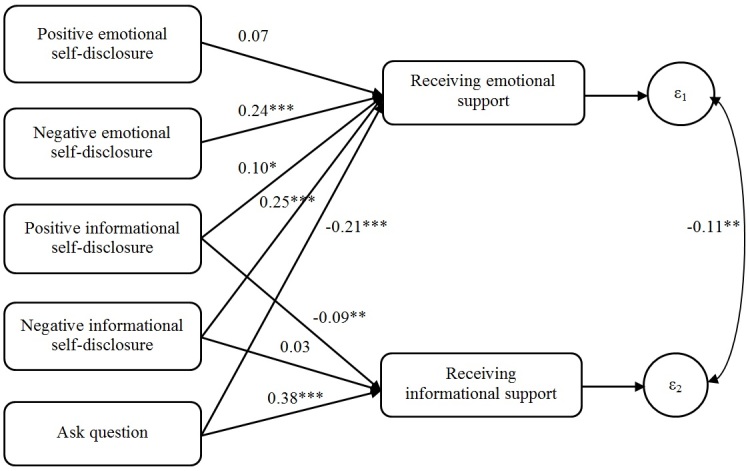
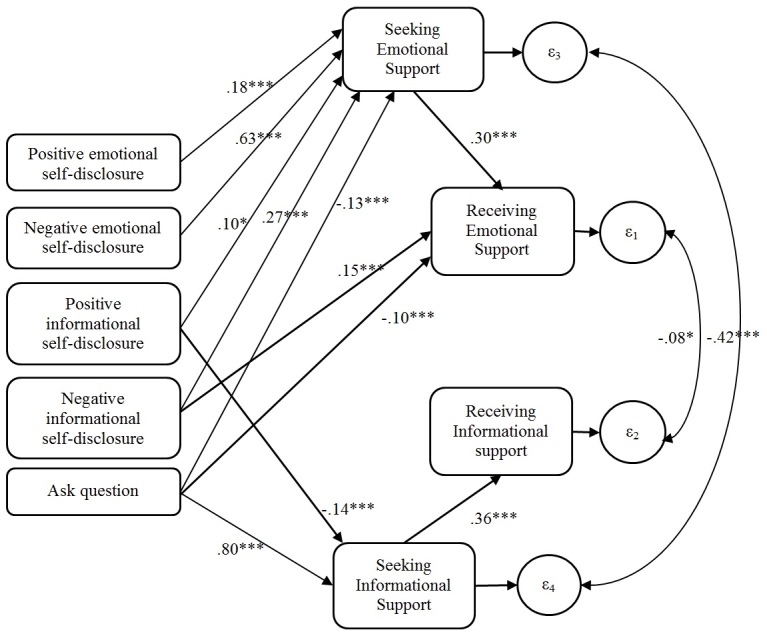
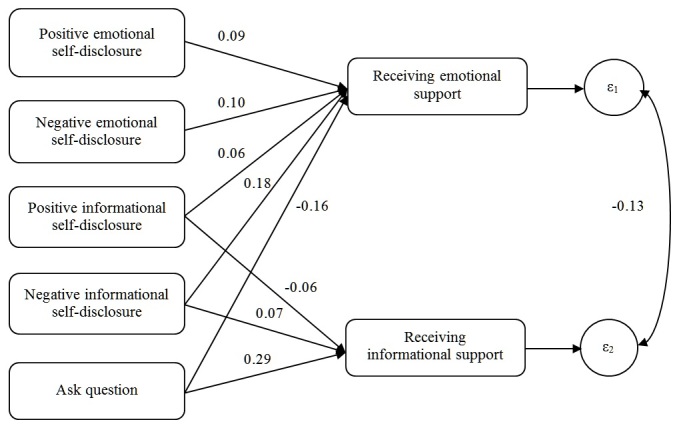
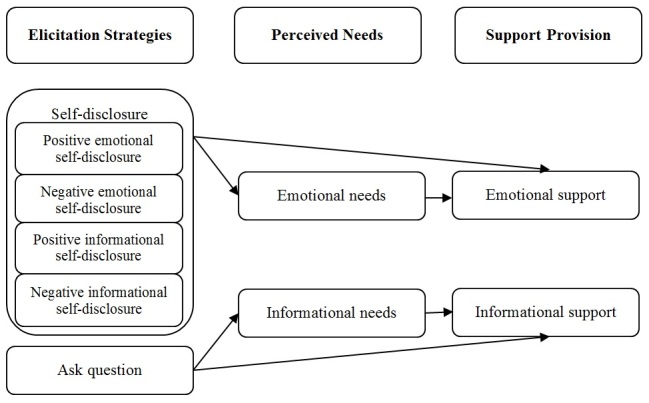
Part 1 used human-coded data to investigate relationships between (1) 4 kinds of self-disclosure and question asking in thread-starting posts and (2) the amount of emotional and informational support in the first reply. Self-disclosure about negative emotions (beta=.24, P<.001), negative events (beta=.25, P<.001), and positive events (beta=.10, P=.02) increased emotional support. However, asking questions depressed emotional support (beta=-.21, P<.001). In contrast, asking questions increased informational support (beta=.38, P<.001), whereas positive informational self-disclosure depressed it (beta=-.09, P=.003). Self-disclosure led to the perception of emotional needs, which elicited emotional support, whereas asking questions led to the perception of informational needs, which elicited informational support. Part 2 used machine-coded data to replicate these results. Part 3 analyzed the machine-coded data and showed that exposure to more emotional support predicted staying in the group longer 33% (hazard ratio=0.67, P<.001), whereas exposure to more informational support predicted leaving the group sooner (hazard ratio=1.05, P<.001).
Self-disclosure is effective in eliciting emotional support, whereas question asking is effective in eliciting informational support. Moreover, perceptions that people desire particular kinds of support influence the support they receive. Finally, the type of support people receive affects the likelihood of their staying in or leaving the group. These results demonstrate the utility of machine learning methods for investigating the dynamics of social support exchange in online support communities.
尽管许多患有严重疾病的人参与在线支持社区,但很少有研究调查参与者如何在这些网站上寻求和提供社会支持。
第一个目标是提出并测试一个动态过程模型,通过该模型,在线支持社区的参与者寻求和提供情感及信息支持。第二个目标是通过使用机器学习技术对对话数据进行计算机编码来证明其价值:(1)通过复制从人工编码数据中得出的关于人们如何寻求支持的结果;(2)通过回答少量人工编码数据难以解决的问题,即接触不同类型的社会支持如何预测在在线支持社区中的持续参与。第三个目标是详细描述这些机器学习技术,以使其他研究人员能够在这些社区中进行大规模数据分析。
对一个在线癌症支持社区中约90,000名注册用户之间的交流进行了分析。语料库包含1,562,459条消息,这些消息被组织成68,158个讨论线程。亚马逊土耳其机器人工作者对(1)1000条发起线程的消息的5个属性(积极和消极情感自我表露、积极和消极信息自我表露、问题)进行编码,以及(2)1000条关于情感和信息支持的回复进行编码。他们的判断被用于训练机器学习模型,该模型自动估计消息中这7个属性的数量。在各个属性上,基于人工判断和基于计算机判断之间的平均皮尔逊相关系数为0.65。
第一部分使用人工编码数据来研究(1)发起线程的帖子中4种自我表露和提问与(2)第一个回复中的情感和信息支持量之间的关系。关于负面情绪(β = 0.24,P <.001)、负面事件(β = 0.25,P <.001)和正面事件(β = 0.10,P = 0.02)的自我表露增加了情感支持。然而,提问会降低情感支持(β = -0.21,P <.001)。相比之下,提问增加了信息支持(β = 0.38,P <.001),而积极的信息自我表露则降低了信息支持(β = -0.09,P = 0.003)。自我表露导致对情感需求的感知,从而引发情感支持,而提问导致对信息需求的感知,从而引发信息支持。第二部分使用机器编码数据来复制这些结果。第三部分分析了机器编码数据,并表明接触更多情感支持预测在群体中停留更长时间的可能性高33%(风险比 = 0.67,P <.001),而接触更多信息支持预测更早离开群体(风险比 = 1.05,P <.001)。
自我表露在引发情感支持方面有效,而提问在引发信息支持方面有效。此外,人们渴望特定类型支持的认知会影响他们获得的支持。最后,人们获得的支持类型会影响他们留在群体或离开群体的可能性。这些结果证明了机器学习方法在研究在线支持社区中社会支持交换动态方面的实用性。