Nickchi Payman, Jafari Mohieddin, Kalantari Shiva
Protein Chemistry & Proteomics Unit, Biotechnology Research Center, Pasteur Institute of Iran, 69, Pasteur St., 13164 Tehran, Iran, School of Biological Sciences, Institute for Research in Fundamental Sciences (IPM), P. O. Box 193955746, Tehran, Iran and Chronic Kidney Disease Research Center (CKDRC), Shahid Beheshti University of Medical Sciences, Tehran, Iran.
Protein Chemistry & Proteomics Unit, Biotechnology Research Center, Pasteur Institute of Iran, 69, Pasteur St., 13164 Tehran, Iran, School of Biological Sciences, Institute for Research in Fundamental Sciences (IPM), P. O. Box 193955746, Tehran, Iran and Chronic Kidney Disease Research Center (CKDRC), Shahid Beheshti University of Medical Sciences, Tehran, Iran Protein Chemistry & Proteomics Unit, Biotechnology Research Center, Pasteur Institute of Iran, 69, Pasteur St., 13164 Tehran, Iran, School of Biological Sciences, Institute for Research in Fundamental Sciences (IPM), P. O. Box 193955746, Tehran, Iran and Chronic Kidney Disease Research Center (CKDRC), Shahid Beheshti University of Medical Sciences, Tehran, Iran
Database (Oxford). 2015 Apr 23;2015:bav037. doi: 10.1093/database/bav037. Print 2015.
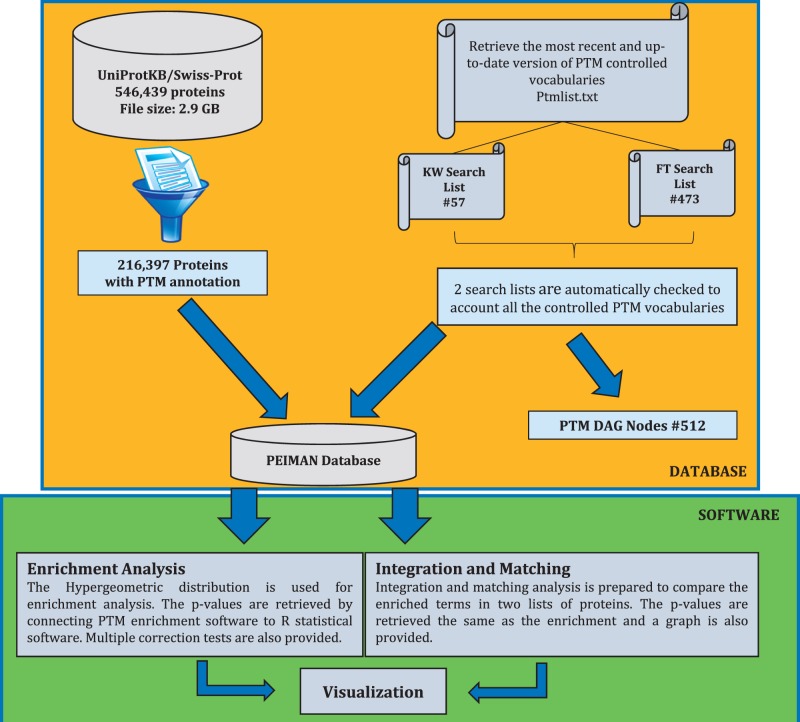
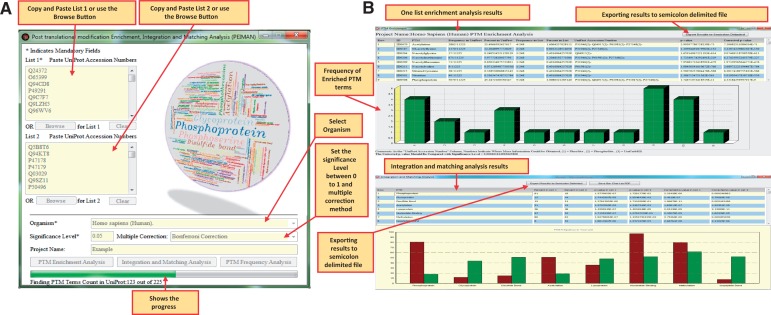
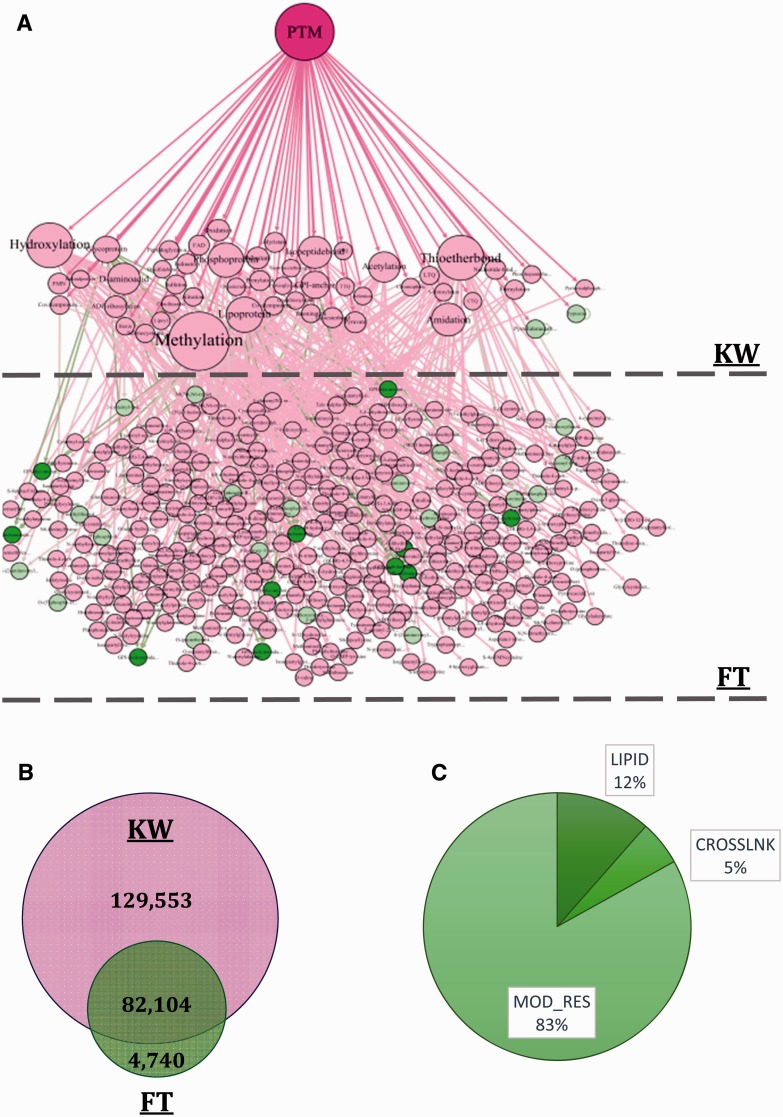
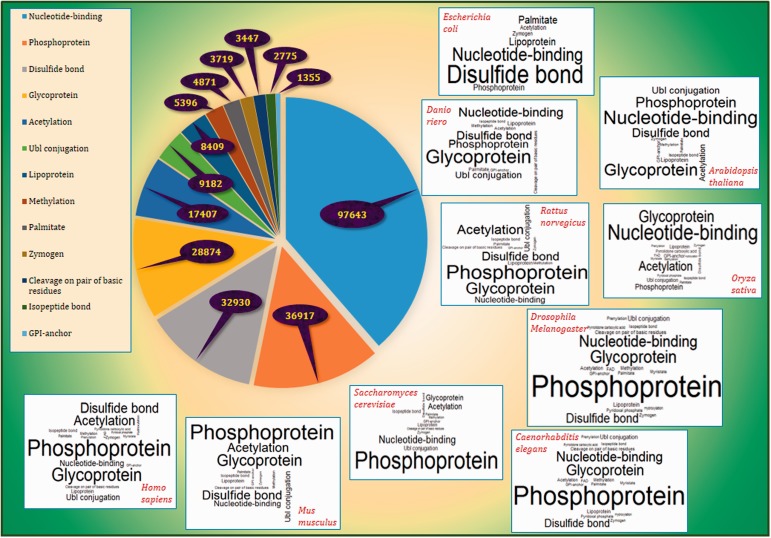
Conventional proteomics has discovered a wide gap between protein sequences and biological functions. The third generation of proteomics was provoked to bridge this gap. Targeted and untargeted post-translational modification (PTM) studies are the most important parts of today's proteomics. Considering the expensive and time-consuming nature of experimental methods, computational methods are developed to study, analyze, predict, count and compute the PTM annotations on proteins. The enrichment analysis softwares are among the common computational biology and bioinformatic software packages. The focus of such softwares is to find the probability of occurrence of the desired biological features in any arbitrary list of genes/proteins. We introduce Post-translational modification Enrichment Integration and Matching Analysis (PEIMAN) software to explore more probable and enriched PTMs on proteins. Here, we also represent the statistics of detected PTM terms used in enrichment analysis in PEIMAN software based on the latest released version of UniProtKB/Swiss-Prot. These results, in addition to giving insight to any given list of proteins, could be useful to design targeted PTM studies for identification and characterization of special chemical groups. Database URL: http://bs.ipm.ir/softwares/PEIMAN/
传统蛋白质组学已发现蛋白质序列与生物学功能之间存在巨大差距。第三代蛋白质组学应运而生,旨在弥合这一差距。靶向和非靶向的翻译后修饰(PTM)研究是当今蛋白质组学最重要的部分。鉴于实验方法既昂贵又耗时,人们开发了计算方法来研究、分析、预测、统计和计算蛋白质上的PTM注释。富集分析软件是常见的计算生物学和生物信息软件包之一。此类软件的重点是在任意基因/蛋白质列表中找到所需生物学特征出现的概率。我们引入翻译后修饰富集整合与匹配分析(PEIMAN)软件,以探索蛋白质上更可能出现且富集的PTM。在此,我们还基于最新发布的UniProtKB/Swiss-Prot版本展示了PEIMAN软件中用于富集分析的检测到的PTM术语的统计数据。这些结果除了能深入了解任何给定的蛋白质列表外,还可能有助于设计靶向PTM研究,以鉴定和表征特殊化学基团。数据库网址:http://bs.ipm.ir/softwares/PEIMAN/