Cleves Ann E, Jain Ajay N
Helen Diller Family Comprehensive Cancer Center, University of California, San Francisco, CA, USA.
J Comput Aided Mol Des. 2015 Jun;29(6):485-509. doi: 10.1007/s10822-015-9846-3. Epub 2015 May 5.
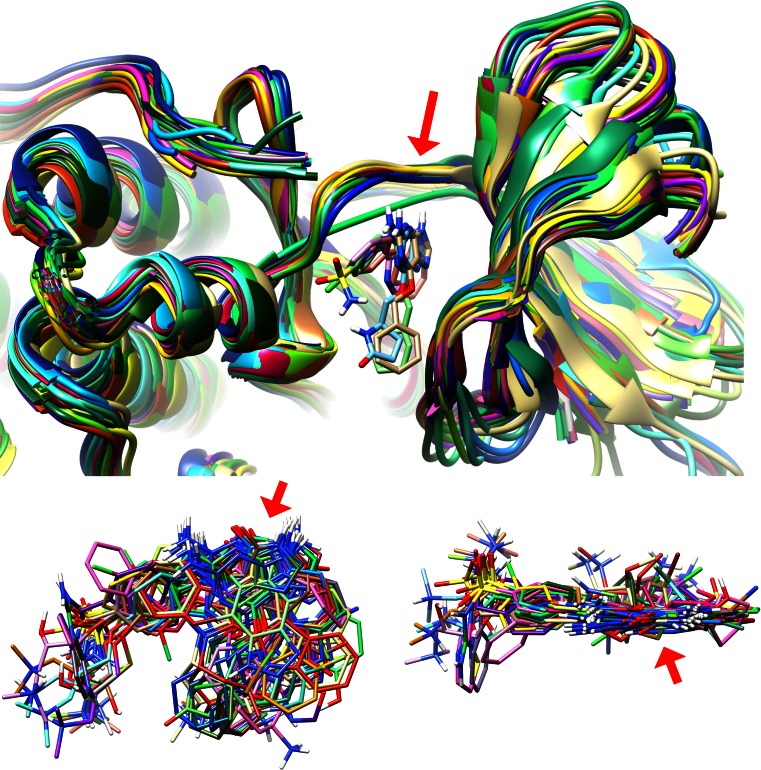
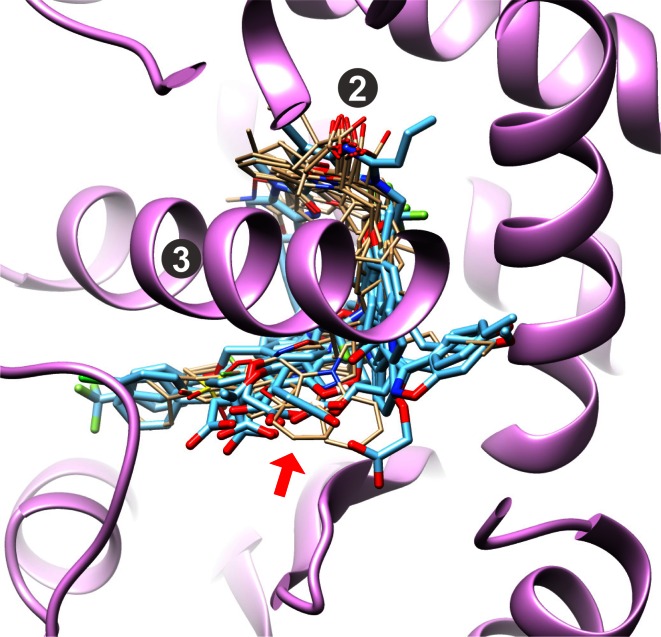
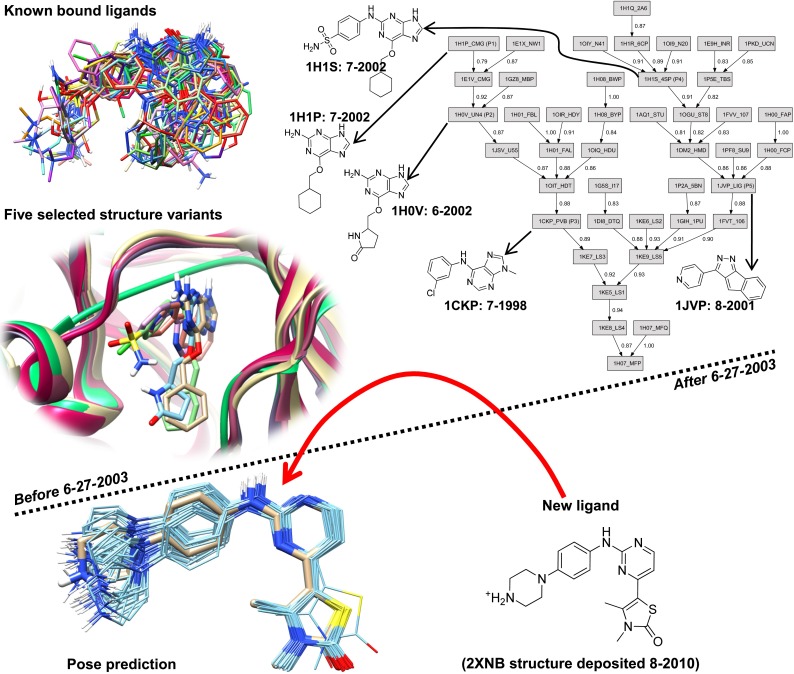
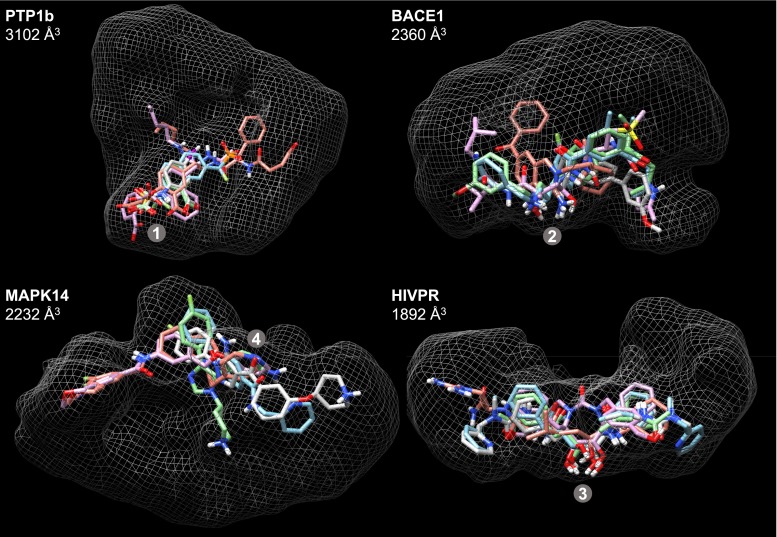
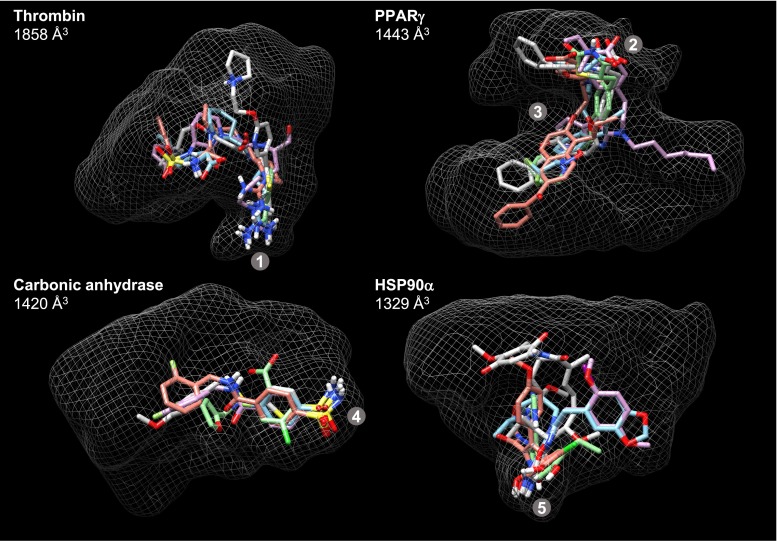
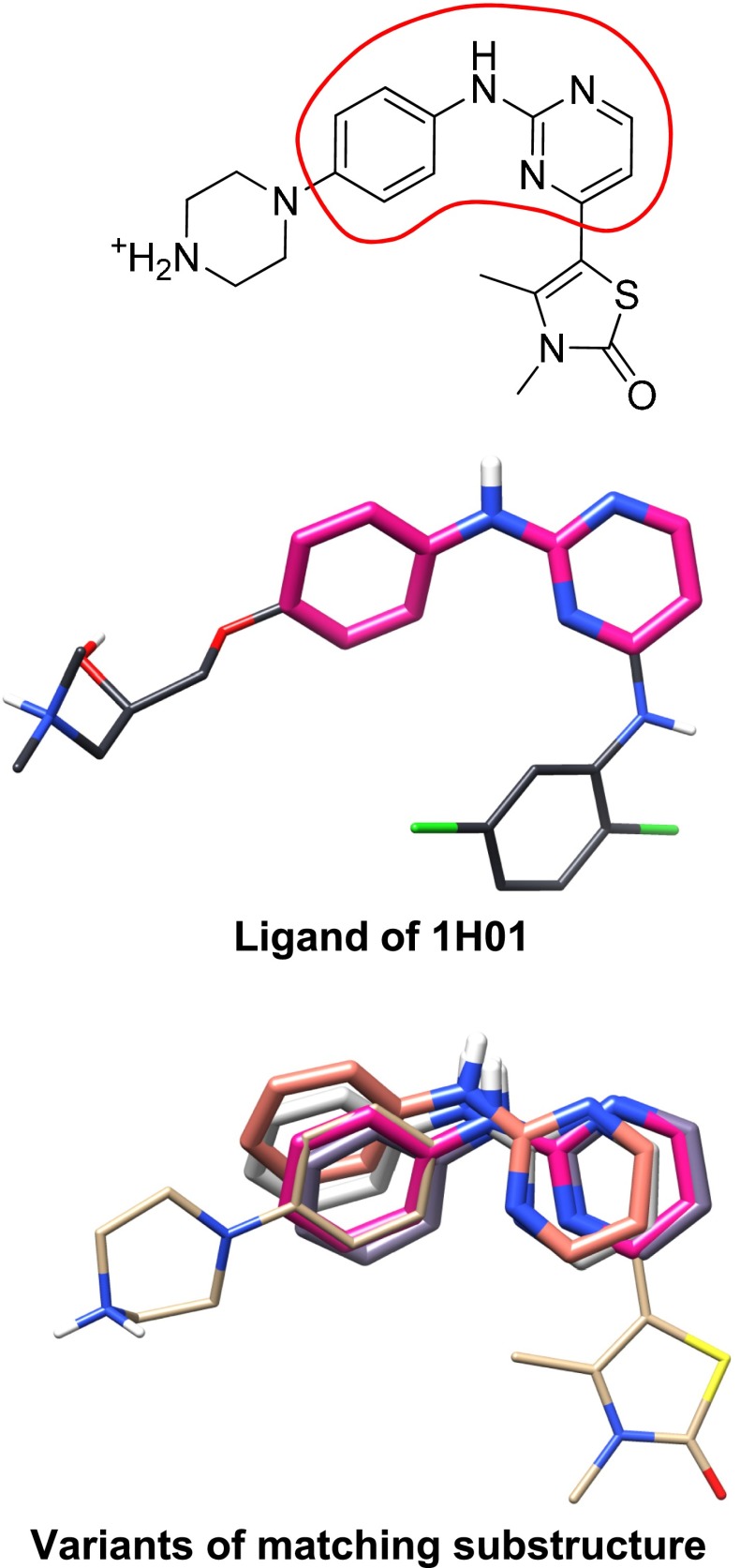
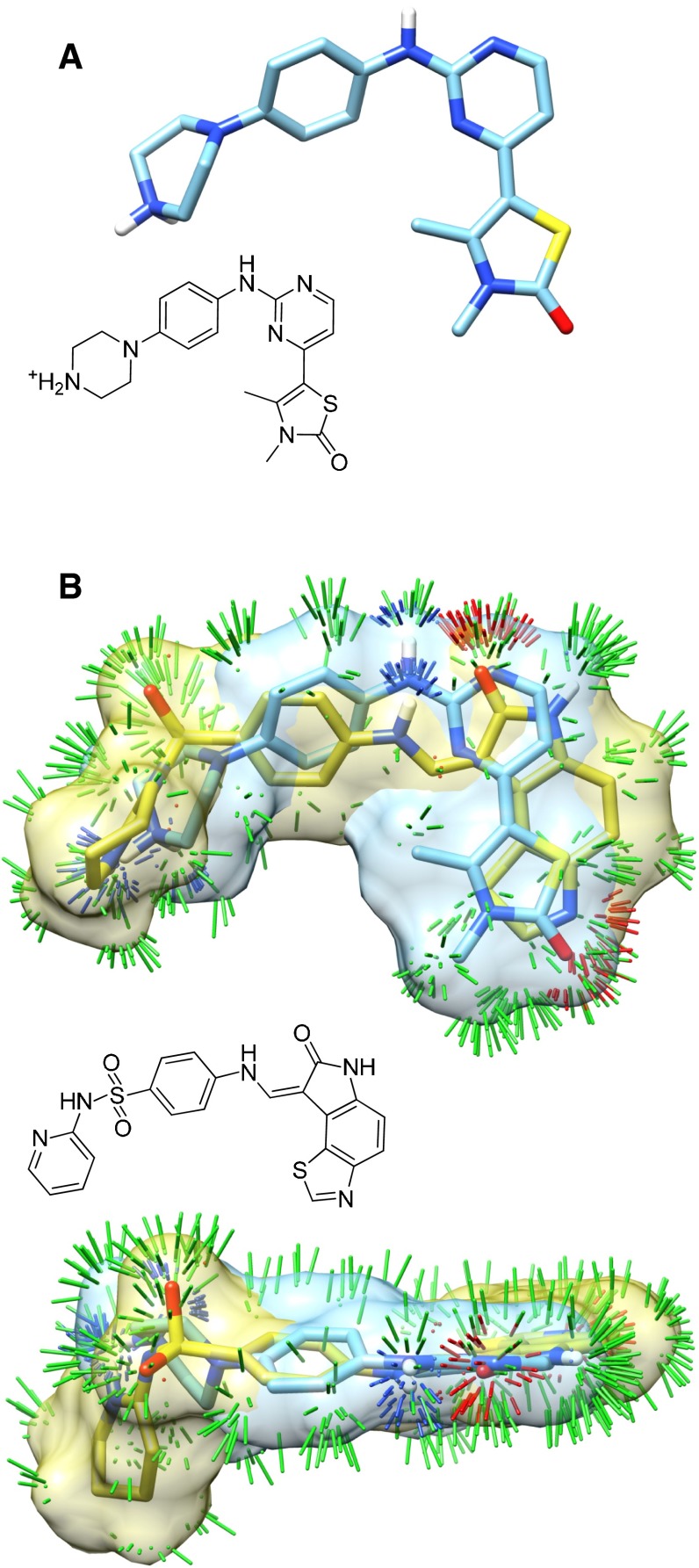
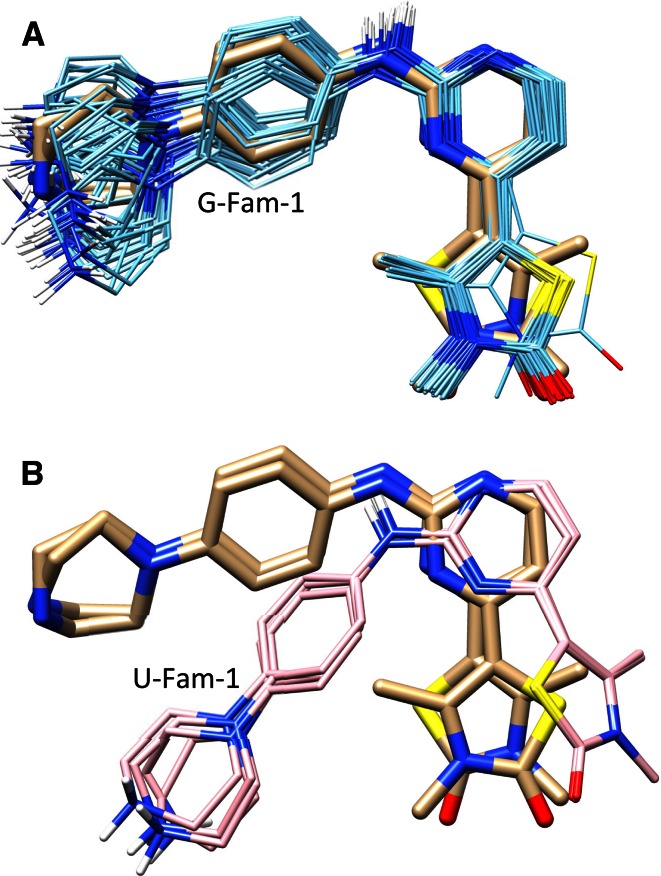
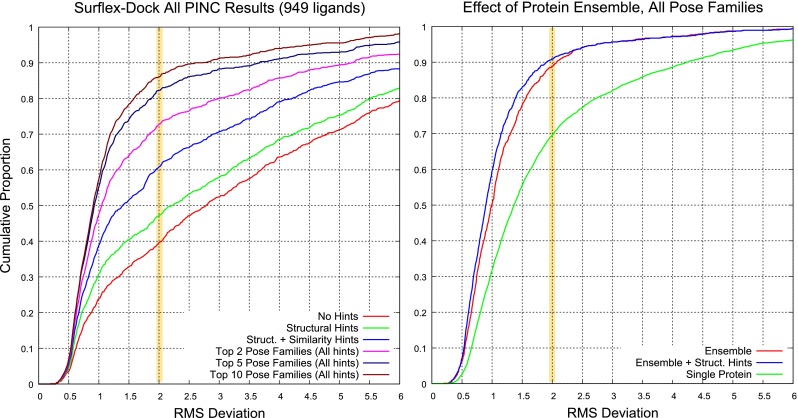
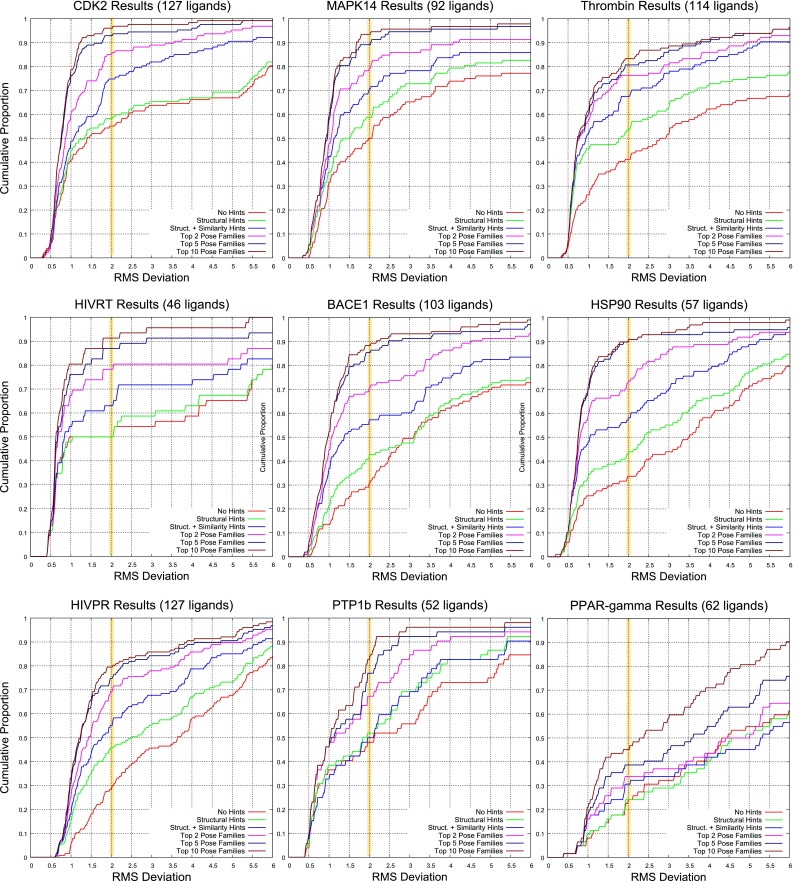
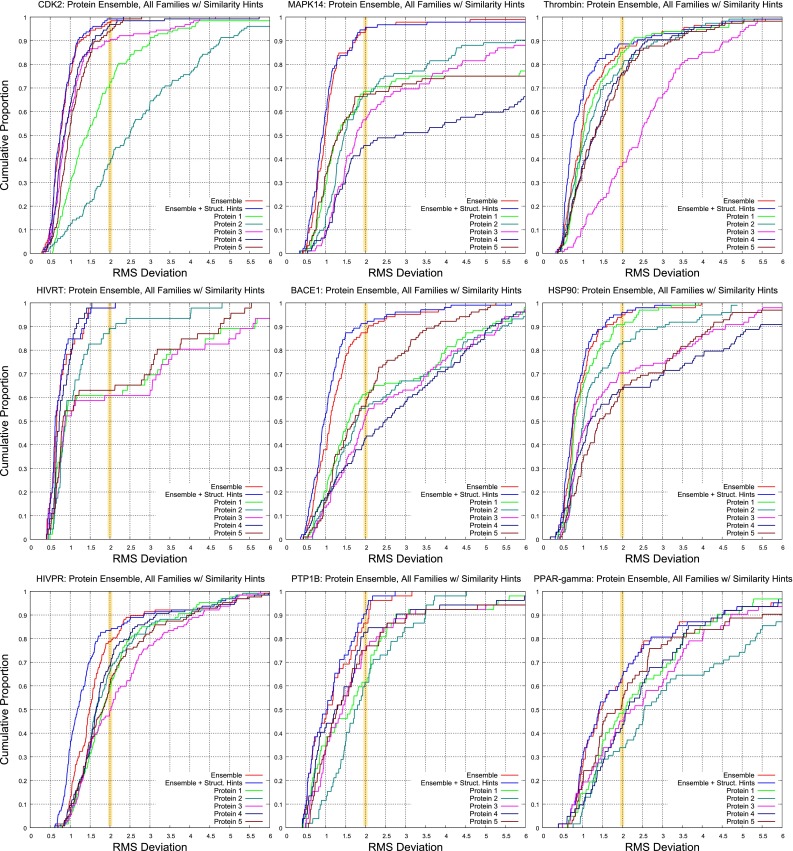
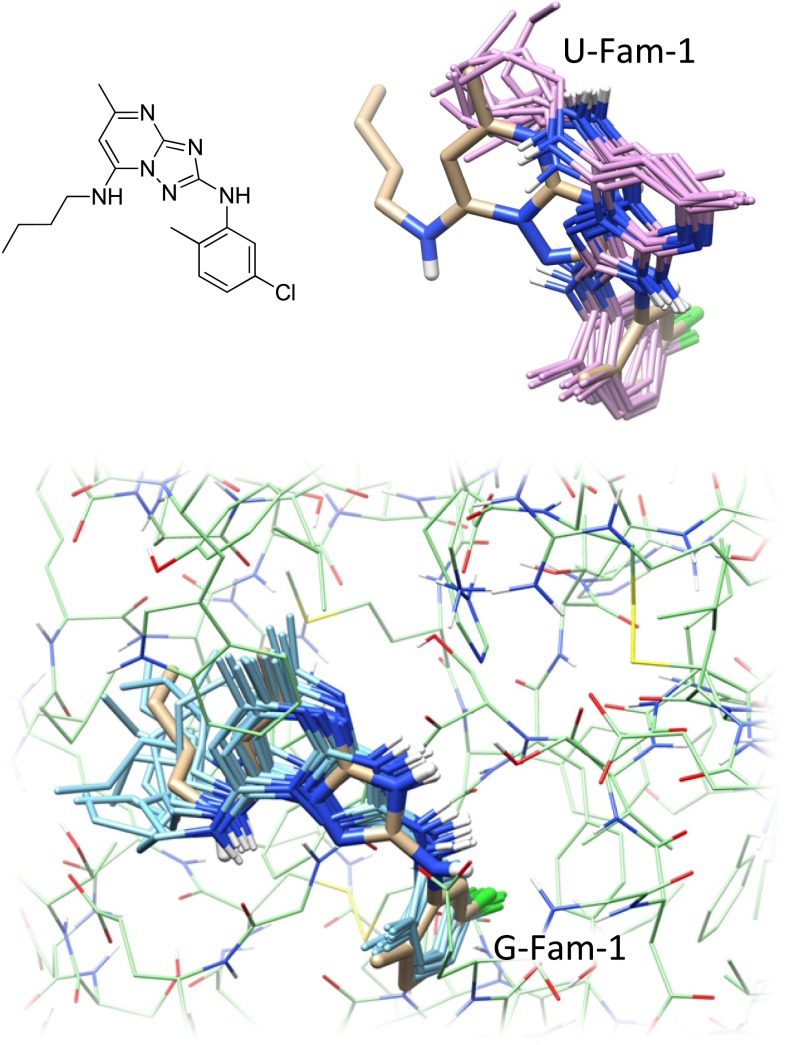
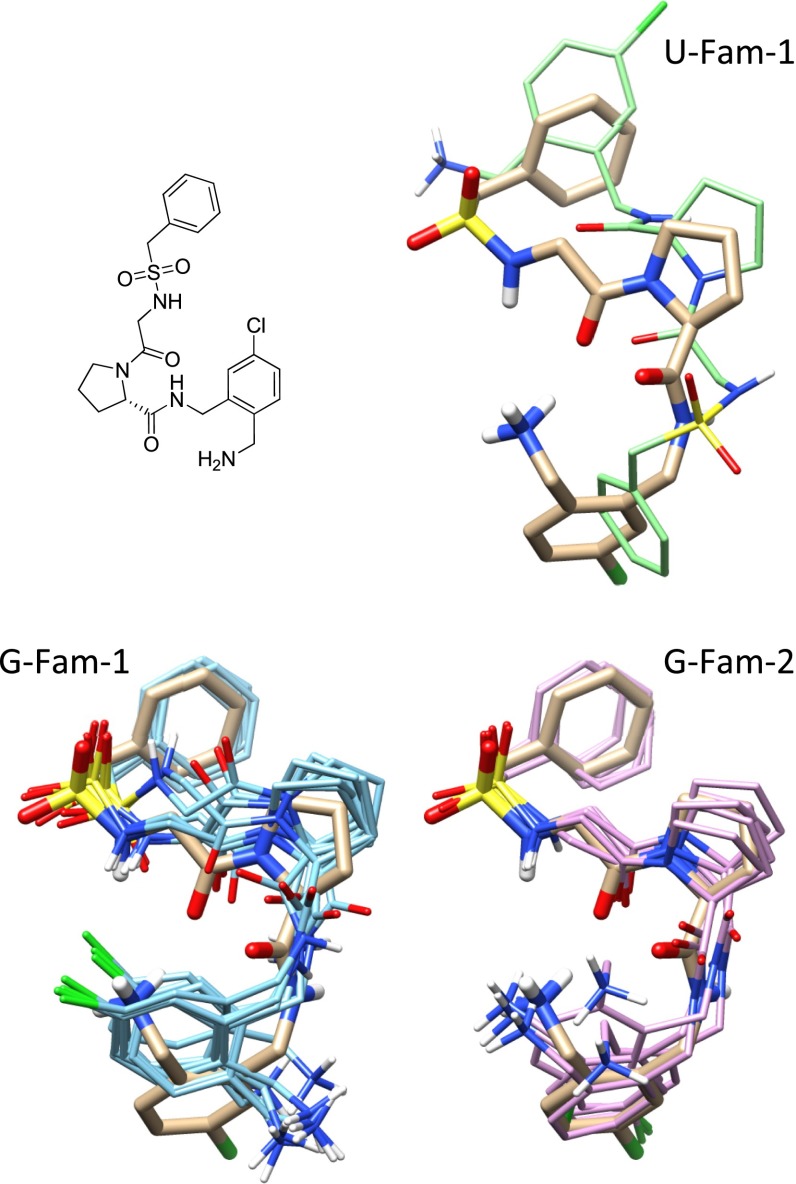
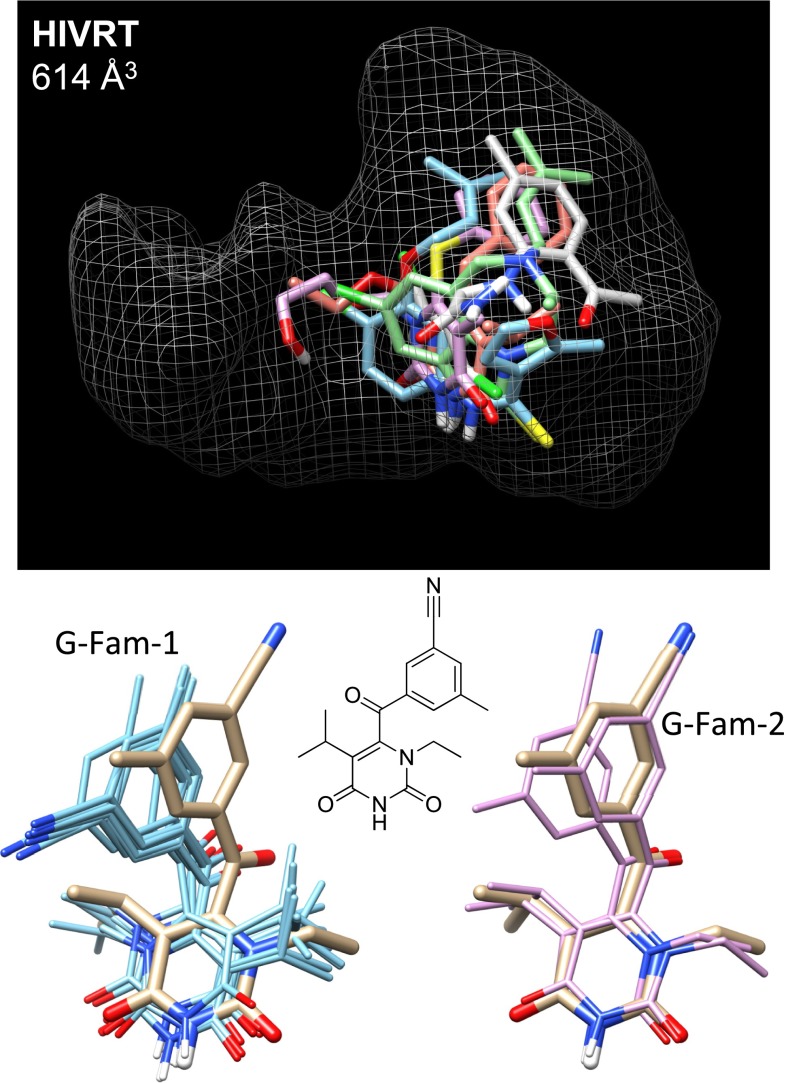
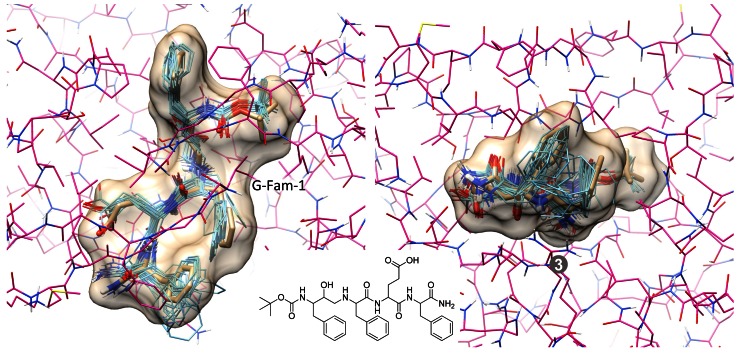
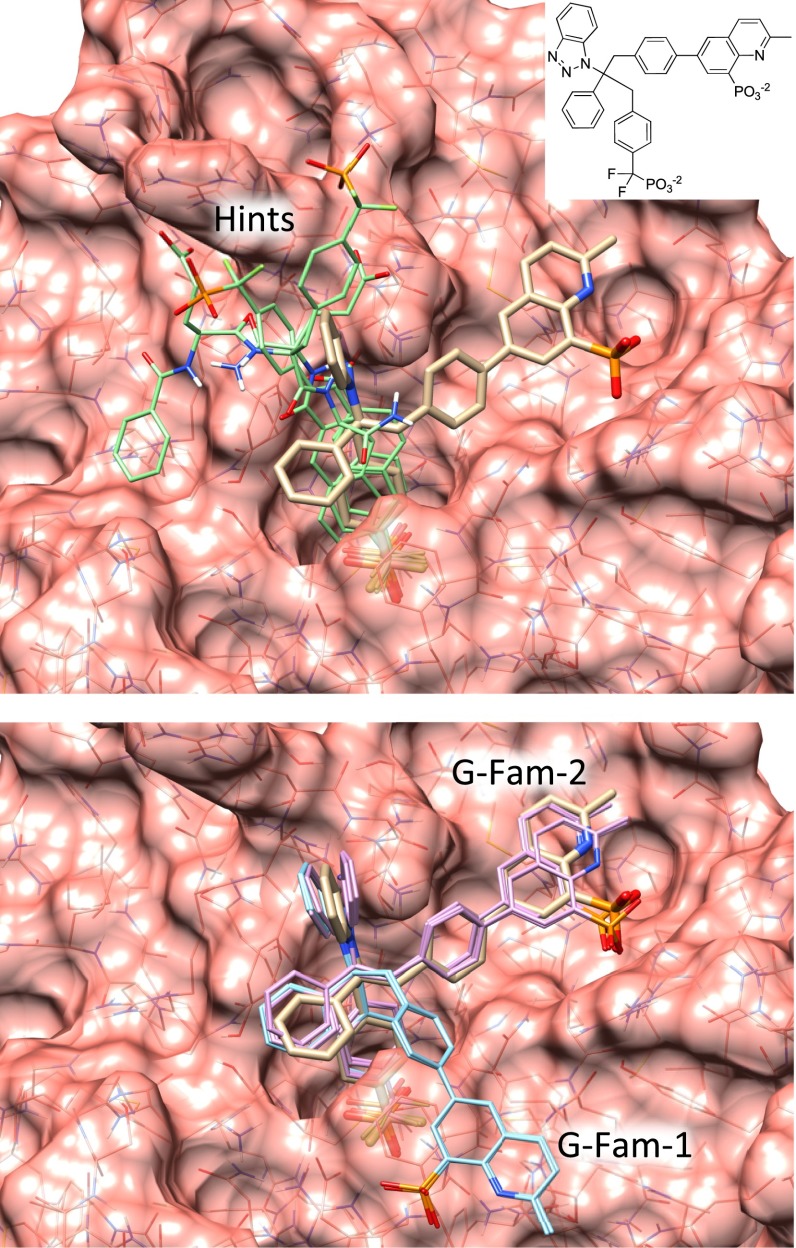
Prediction of the bound configuration of small-molecule ligands that differ substantially from the cognate ligand of a protein co-crystal structure is much more challenging than re-docking the cognate ligand. Success rates for cross-docking in the range of 20-30 % are common. We present an approach that uses structural information known prior to a particular cutoff-date to make predictions on ligands whose bounds structures were determined later. The knowledge-guided docking protocol was tested on a set of ten protein targets using a total of 949 ligands. The benchmark data set, called PINC ("PINC Is Not Cognate"), is publicly available. Protein pocket similarity was used to choose representative structures for ensemble-docking. The docking protocol made use of known ligand poses prior to the cutoff-date, both to help guide the configurational search and to adjust the rank of predicted poses. Overall, the top-scoring pose family was correct over 60 % of the time, with the top-two pose families approaching a 75 % success rate. Correct poses among all those predicted were identified nearly 90 % of the time. The largest improvements came from the use of molecular similarity to improve ligand pose rankings and the strategy for identifying representative protein structures. With the exception of a single outlier target, the knowledge-guided docking protocol produced results matching the quality of cognate-ligand re-docking, but it did so on a very challenging temporally-segregated cross-docking benchmark.
预测与蛋白质共晶体结构的同源配体有很大差异的小分子配体的结合构型,比重新对接同源配体更具挑战性。交叉对接的成功率在20%-30%之间很常见。我们提出了一种方法,该方法利用特定截止日期之前已知的结构信息,对其结合结构后来才确定的配体进行预测。知识引导对接协议在一组十个蛋白质靶点上使用总共949个配体进行了测试。这个被称为PINC(“PINC不是同源的”)的基准数据集是公开可用的。蛋白质口袋相似性被用于选择用于整体对接的代表性结构。对接协议利用截止日期之前已知的配体构象,既有助于指导构象搜索,又能调整预测构象的排名。总体而言,得分最高的构象家族在超过60%的时间里是正确的,前两个构象家族的成功率接近75%。在所有预测的构象中,正确构象的识别率接近90%。最大的改进来自于利用分子相似性来改善配体构象排名以及识别代表性蛋白质结构的策略。除了一个异常的靶点外,知识引导对接协议产生的结果与同源配体重新对接的质量相当,但它是在一个极具挑战性的时间隔离交叉对接基准上做到这一点的。