Primary Care, University of Exeter Medical School, University of Exeter, Exeter, United Kingdom.
JMIR Med Inform. 2015 May 6;3(2):e20. doi: 10.2196/medinform.3783.
Open-ended questions eliciting free-text comments have been widely adopted in surveys of patient experience. Analysis of free text comments can provide deeper or new insight, identify areas for action, and initiate further investigation. Also, they may be a promising way to progress from documentation of patient experience to achieving quality improvement. The usual methods of analyzing free-text comments are known to be time and resource intensive. To efficiently deal with a large amount of free-text, new methods of rapidly summarizing and characterizing the text are being explored.
The aim of this study was to investigate the feasibility of using freely available Web-based text processing tools (text clouds, distinctive word extraction, key words in context) for extracting useful information from large amounts of free-text commentary about patient experience, as an alternative to more resource intensive analytic methods.
We collected free-text responses to a broad, open-ended question on patients' experience of primary care in a cross-sectional postal survey of patients recently consulting doctors in 25 English general practices. We encoded the responses to text files which were then uploaded to three Web-based textual processing tools. The tools we used were two text cloud creators: TagCrowd for unigrams, and Many Eyes for bigrams; and Voyant Tools, a Web-based reading tool that can extract distinctive words and perform Keyword in Context (KWIC) analysis. The association of patients' experience scores with the occurrence of certain words was tested with logistic regression analysis. KWIC analysis was also performed to gain insight into the use of a significant word.
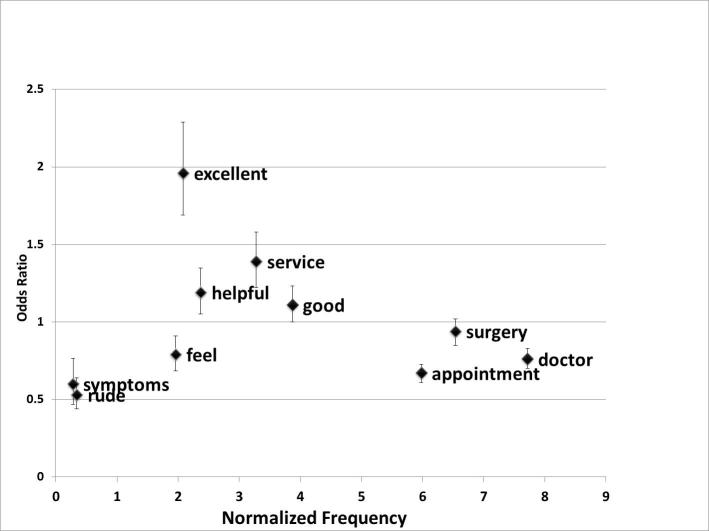
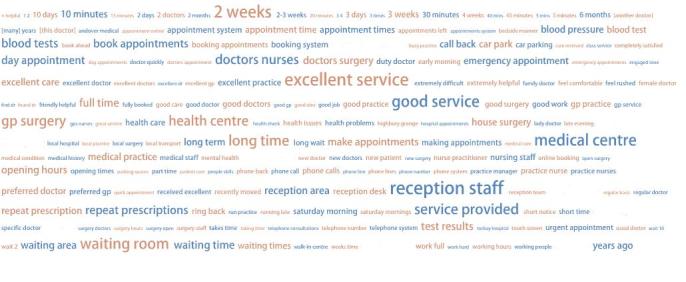
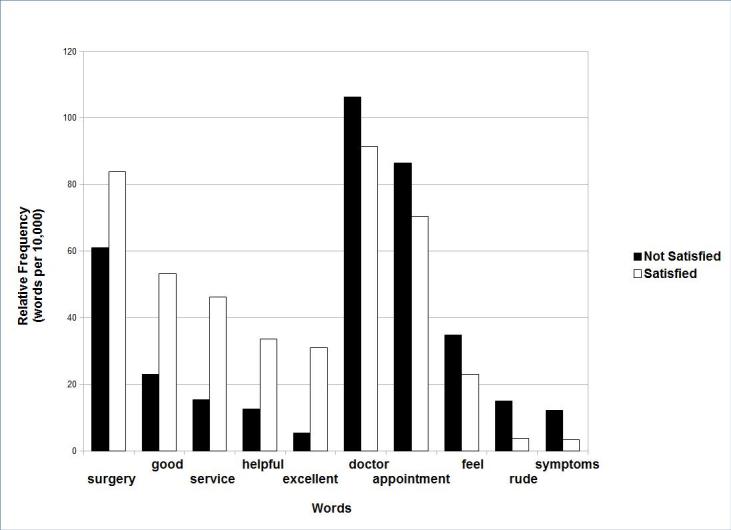
In total, 3426 free-text responses were received from 7721 patients (comment rate: 44.4%). The five most frequent words in the patients' comments were "doctor", "appointment", "surgery", "practice", and "time". The three most frequent two-word combinations were "reception staff", "excellent service", and "two weeks". The regression analysis showed that the occurrence of the word "excellent" in the comments was significantly associated with a better patient experience (OR=1.96, 95%CI=1.63-2.34), while "rude" was significantly associated with a worse experience (OR=0.53, 95%CI=0.46-0.60). The KWIC results revealed that 49 of the 78 (63%) occurrences of the word "rude" in the comments were related to receptionists and 17(22%) were related to doctors.
Web-based text processing tools can extract useful information from free-text comments and the output may serve as a springboard for further investigation. Text clouds, distinctive words extraction and KWIC analysis show promise in quick evaluation of unstructured patient feedback. The results are easily understandable, but may require further probing such as KWIC analysis to establish the context. Future research should explore whether more sophisticated methods of textual analysis (eg, sentiment analysis, natural language processing) could add additional levels of understanding.

开放式问题,引出自由文本评论已被广泛应用于患者体验的调查。分析自由文本评论可以提供更深入或新的见解,确定行动领域,并启动进一步的调查。此外,它们可能是从记录患者体验到实现质量改进的有希望的途径。众所周知,分析自由文本评论的常用方法既耗时又耗资源。为了有效地处理大量的自由文本,正在探索新的快速总结和描述文本的方法。
本研究旨在探讨使用免费的基于网络的文本处理工具(文本云、特色词提取、上下文关键词)从大量关于患者体验的自由文本评论中提取有用信息的可行性,作为更具资源密集性的分析方法的替代方法。
我们收集了在 25 家英国普通诊所最近就诊的患者的横断面邮寄调查中,对初级保健患者体验的广泛开放式问题的自由文本回答。我们将回复编码为文本文件,然后将其上传到三个基于网络的文本处理工具。我们使用的工具是两个文本云创建者:TagCrowd 用于单字,Many Eyes 用于双字;以及 Voyant Tools,这是一个基于网络的阅读工具,可以提取特色词并执行关键词上下文(KWIC)分析。使用逻辑回归分析测试患者体验评分与某些单词出现的关联。还进行了 KWIC 分析,以深入了解一个重要单词的使用情况。
总共从 7721 名患者中收到 3426 份自由文本回复(评论率:44.4%)。患者评论中最常见的五个词是“医生”、“预约”、“手术”、“实践”和“时间”。患者评论中最常见的两个词组合是“接待员”、“卓越服务”和“两周”。回归分析显示,评论中“出色”一词的出现与更好的患者体验显著相关(OR=1.96,95%CI=1.63-2.34),而“粗鲁”与更差的体验显著相关(OR=0.53,95%CI=0.46-0.60)。KWIC 结果显示,评论中 78 个“粗鲁”一词中有 49 个(63%)与接待员有关,17 个(22%)与医生有关。
基于网络的文本处理工具可以从自由文本评论中提取有用信息,输出结果可以作为进一步调查的起点。文本云、特色词提取和 KWIC 分析在快速评估非结构化患者反馈方面显示出潜力。结果易于理解,但可能需要进一步探测,例如 KWIC 分析,以确定上下文。未来的研究应探讨更复杂的文本分析方法(例如情感分析、自然语言处理)是否可以增加额外的理解层次。