Li Shi-jun, Jiang Hua, Yang Hao, Chen Wei, Peng Jin, Sun Ming-wei, Lu Charles Damien, Peng Xi, Zeng Jun
Department of Computational Mathematics and Bio-statistics, Metabolomics and Multidisciplinary Laboratory for Trauma Research, Sichuan Provincial People's Hospital, Sichuan Academy of Medical Sciences, Chengdu, Sichuan, China.
Department of Computational Mathematics and Bio-statistics, Metabolomics and Multidisciplinary Laboratory for Trauma Research, Sichuan Provincial People's Hospital, Sichuan Academy of Medical Sciences, Chengdu, Sichuan, China; Department of Parenteral and Enteral Nutrition, Peking Union Medical College Hospital, Beijing, China; Institute of Burn Research, Southwest Hospital of the Third Military Medical University, Chongqing, China.
PLoS One. 2015 May 29;10(5):e0127538. doi: 10.1371/journal.pone.0127538. eCollection 2015.
After several decades' development, meta-analysis has become the pillar of evidence-based medicine. However, heterogeneity is still the threat to the validity and quality of such studies. Currently, Q and its descendant I(2) (I square) tests are widely used as the tools for heterogeneity evaluation. The core mission of this kind of test is to identify data sets from similar populations and exclude those are from different populations. Although Q and I(2) are used as the default tool for heterogeneity testing, the work we present here demonstrates that the robustness of these two tools is questionable.
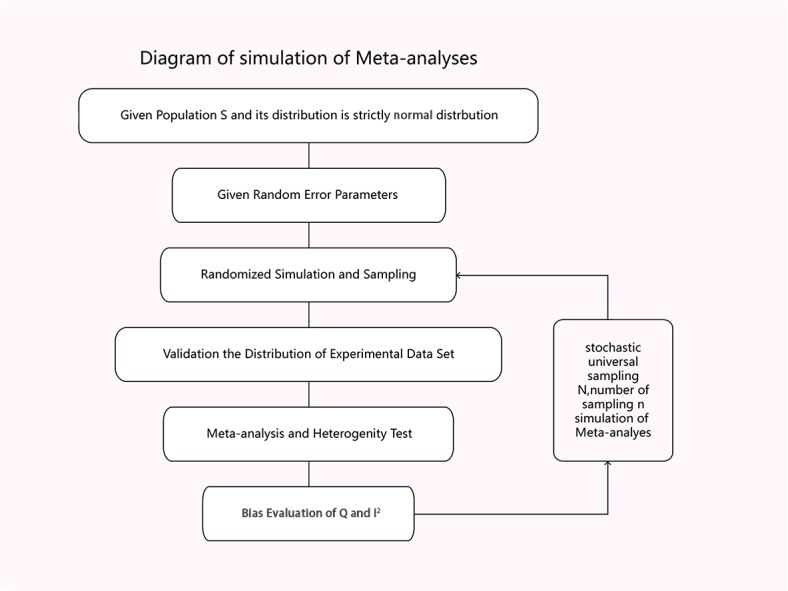
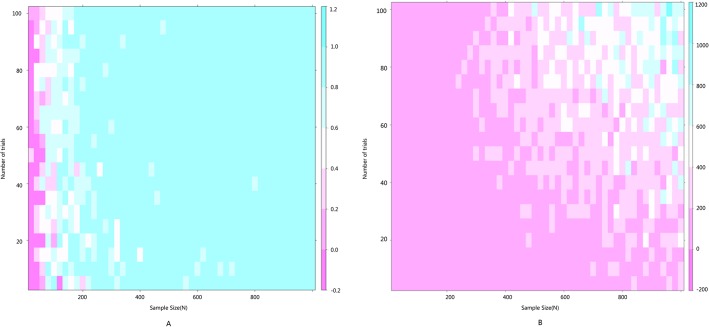
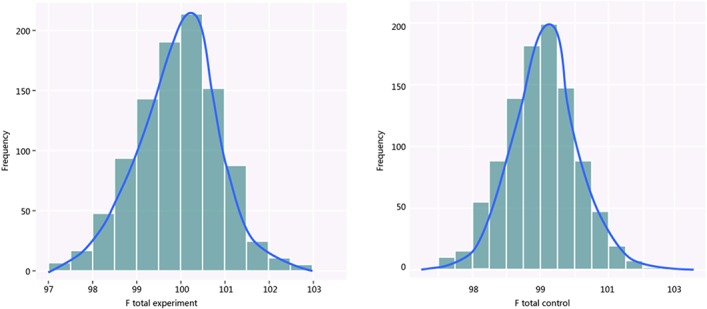
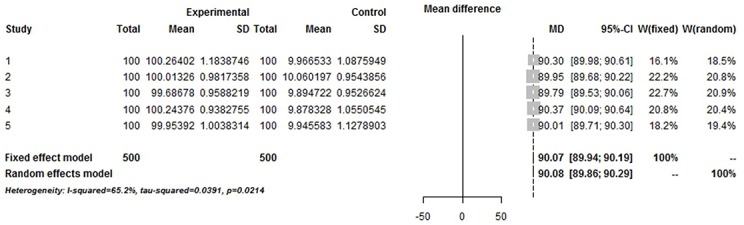
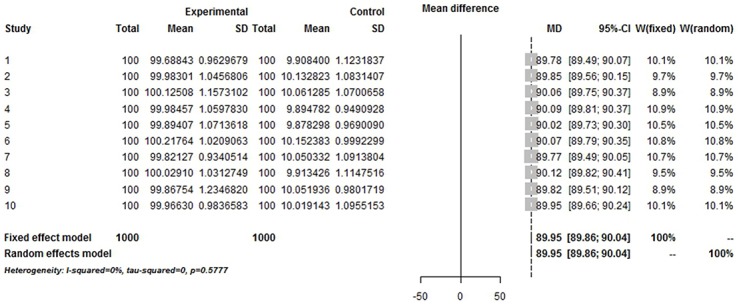
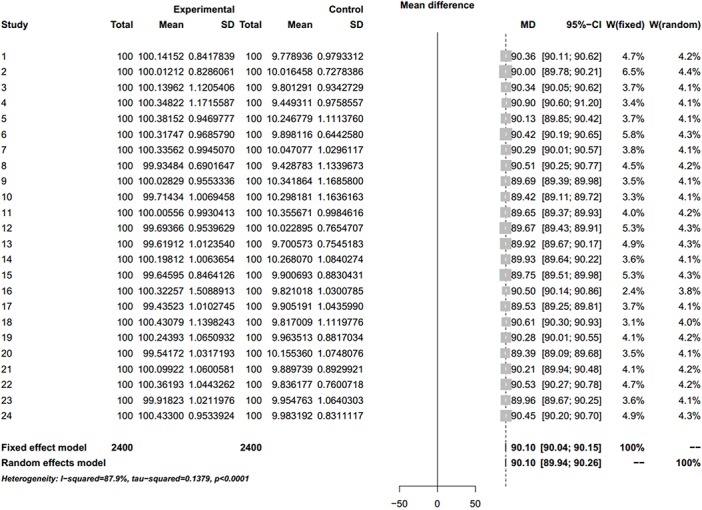
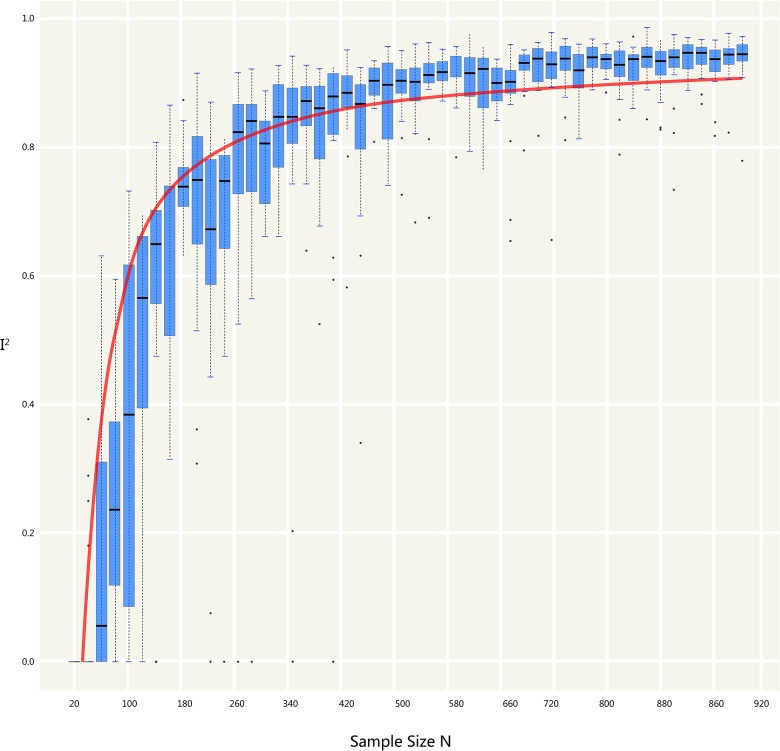
We simulated a strictly normalized population S. The simulation successfully represents randomized control trial data sets, which fits perfectly with the theoretical distribution (experimental group: p = 0.37, control group: p = 0.88). And we randomly generate research samples Si that fits the population with tiny distributions. In short, these data sets are perfect and can be seen as completely homogeneous data from the exactly same population. If Q and I(2) are truly robust tools, the Q and I(2) testing results on our simulated data sets should not be positive. We then synthesized these trials by using fixed model. Pooled results indicated that the mean difference (MD) corresponds highly with the true values, and the 95% confidence interval (CI) is narrow. But, when the number of trials and sample size of trials enrolled in the meta-analysis are substantially increased; the Q and I(2) values also increase steadily. This result indicates that I(2) and Q are only suitable for testing heterogeneity amongst small sample size trials, and are not adoptable when the sample sizes and the number of trials increase substantially.
Every day, meta-analysis studies which contain flawed data analysis are emerging and passed on to clinical practitioners as "updated evidence". Using this kind of evidence that contain heterogeneous data sets leads to wrong conclusion, makes chaos in clinical practice and weakens the foundation of evidence-based medicine. We suggest more strict applications of meta-analysis: it should only be applied to those synthesized trials with small sample sizes. We call upon that the tools of evidence-based medicine should keep up-to-dated with the cutting-edge technologies in data science. Clinical research data should be made available publicly when there is any relevant article published so the research community could conduct in-depth data mining, which is a better alternative for meta-analysis in many instances.
经过几十年的发展,荟萃分析已成为循证医学的支柱。然而,异质性仍然是此类研究有效性和质量的威胁。目前,Q检验及其衍生的I²(I方)检验被广泛用作异质性评估工具。这类检验的核心任务是识别来自相似总体的数据集,并排除那些来自不同总体的数据集。尽管Q检验和I²检验被用作异质性检验的默认工具,但我们在此展示的工作表明这两种工具的稳健性值得怀疑。
我们模拟了一个严格标准化的总体S。该模拟成功地代表了随机对照试验数据集,与理论分布完美契合(实验组:p = 0.37,对照组:p = 0.88)。并且我们随机生成符合该总体微小分布的研究样本Si。简而言之,这些数据集是完美的,可以被视为来自完全相同总体的完全同质的数据。如果Q检验和I²检验是真正稳健的工具,那么对我们模拟数据集进行Q检验和I²检验的结果不应为阳性。然后我们使用固定模型对这些试验进行综合分析。合并结果表明,平均差值(MD)与真实值高度相符,且95%置信区间(CI)较窄。但是,当荟萃分析中纳入的试验数量和试验样本量大幅增加时,Q值和I²值也会稳步上升。这一结果表明,I²检验和Q检验仅适用于检验小样本量试验之间的异质性,当样本量和试验数量大幅增加时则不适用。
每天,都有包含有缺陷数据分析的荟萃分析研究出现,并作为“更新的证据”传递给临床医生。使用这种包含异质数据集的证据会导致错误的结论,在临床实践中造成混乱,并削弱循证医学的基础。我们建议对荟萃分析进行更严格的应用:它应该仅应用于那些小样本量的综合试验。我们呼吁循证医学工具应跟上数据科学的前沿技术。当有任何相关文章发表时,临床研究数据应公开提供,以便研究界能够进行深入的数据挖掘,在许多情况下,这是荟萃分析的更好替代方法。