Jiao Yishan, Berisha Visar, Tu Ming, Liss Julie
Department of Speech and Hearing Science, Arizona State University.
IEEE/ACM Trans Audio Speech Lang Process. 2015 Sep;23(9):1421-1430. doi: 10.1109/TASLP.2015.2434213.
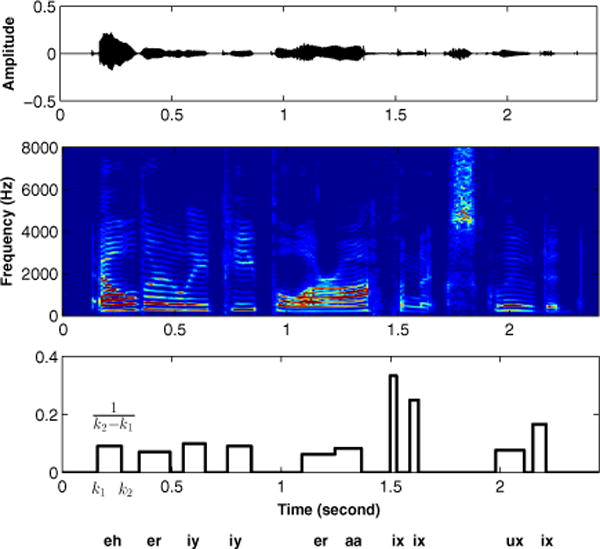
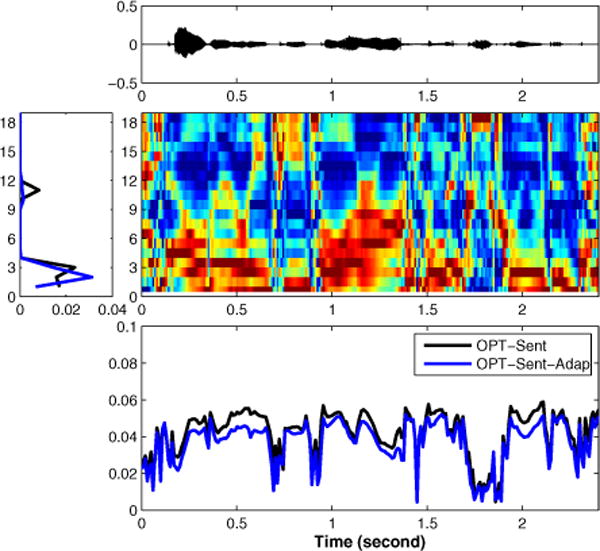
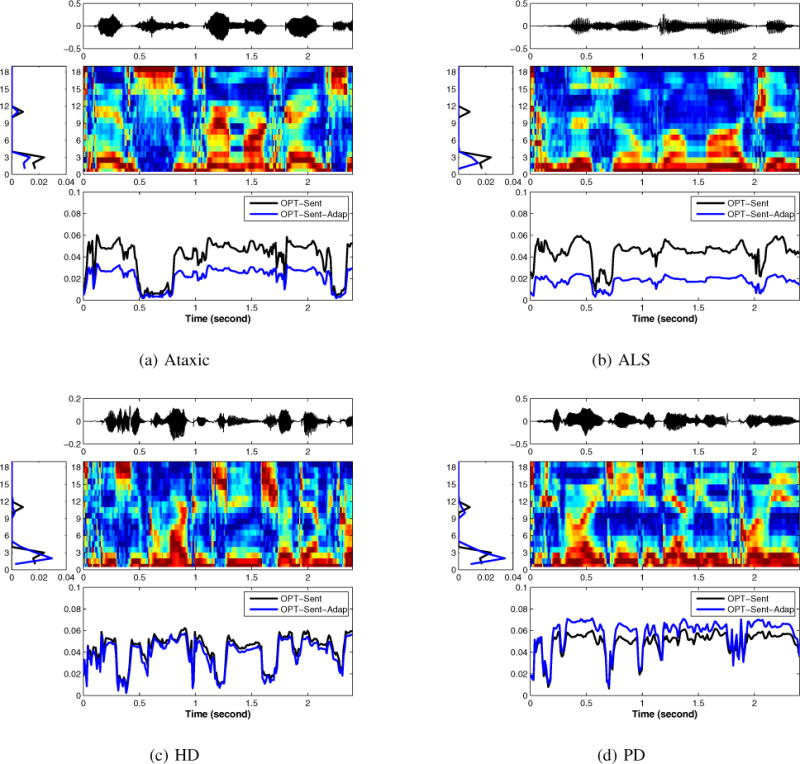
Speaking rate estimation directly from the speech waveform is a long-standing problem in speech signal processing. In this paper, we pose the speaking rate estimation problem as that of estimating a temporal density function whose integral over a given interval yields the speaking rate within that interval. In contrast to many existing methods, we avoid the more difficult task of detecting individual phonemes within the speech signal and we avoid heuristics such as thresholding the temporal envelope to estimate the number of vowels. Rather, the proposed method aims to learn an optimal weighting function that can be directly applied to time-frequency features in a speech signal to yield a temporal density function. We propose two convex cost functions for learning the weighting functions and an adaptation strategy to customize the approach to a particular speaker using minimal training. The algorithms are evaluated on the TIMIT corpus, on a dysarthric speech corpus, and on the ICSI Switchboard spontaneous speech corpus. Results show that the proposed methods outperform three competing methods on both healthy and dysarthric speech. In addition, for spontaneous speech rate estimation, the result show a high correlation between the estimated speaking rate and ground truth values.
直接从语音波形估计语速是语音信号处理中一个长期存在的问题。在本文中,我们将语速估计问题视为估计一个时间密度函数的问题,该函数在给定区间上的积分得出该区间内的语速。与许多现有方法不同,我们避免了在语音信号中检测单个音素这一更为困难的任务,并且我们避免了诸如对时间包络进行阈值处理以估计元音数量等启发式方法。相反,所提出的方法旨在学习一个最优加权函数,该函数可以直接应用于语音信号中的时频特征以产生一个时间密度函数。我们提出了两个用于学习加权函数的凸代价函数以及一种适应策略,以使用最少的训练将该方法定制到特定的说话者。这些算法在TIMIT语料库、构音障碍语音语料库和ICSI交换机自发语音语料库上进行了评估。结果表明,所提出的方法在正常语音和构音障碍语音上均优于三种竞争方法。此外,对于自发语音速率估计,结果表明估计的语速与真实值之间具有高度相关性。