Fox Naomi K, Brenner Steven E, Chandonia John-Marc
Lawrence Berkeley National Laboratory, Physical Biosciences Division, Berkeley, California, 94720.
Department of Plant and Microbial Biology, University of California, Berkeley, California, 94720.
Proteins. 2015 Nov;83(11):2025-38. doi: 10.1002/prot.24915. Epub 2015 Sep 19.
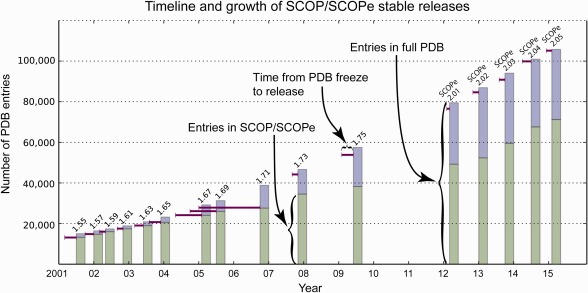
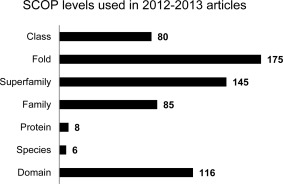
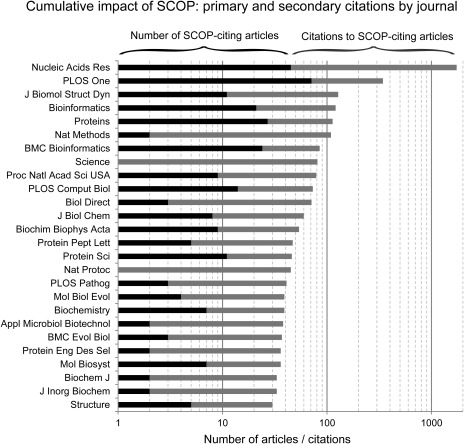
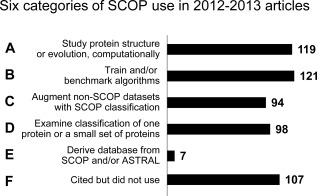
The Structural Classification of Proteins (SCOP) and Class, Architecture, Topology, Homology (CATH) databases have been valuable resources for protein structure classification for over 20 years. Development of SCOP (version 1) concluded in June 2009 with SCOP 1.75. The SCOPe (SCOP-extended) database offers continued development of the classic SCOP hierarchy, adding over 33,000 structures. We have attempted to assess the impact of these two decade old resources and guide future development. To this end, we surveyed recent articles to learn how structure classification data are used. Of 571 articles published in 2012-2013 that cite SCOP, 439 actually use data from the resource. We found that the type of use was fairly evenly distributed among four top categories: A) study protein structure or evolution (27% of articles), B) train and/or benchmark algorithms (28% of articles), C) augment non-SCOP datasets with SCOP classification (21% of articles), and D) examine the classification of one protein/a small set of proteins (22% of articles). Most articles described computational research, although 11% described purely experimental research, and a further 9% included both. We examined how CATH and SCOP were used in 158 articles that cited both databases: while some studies used only one dataset, the majority used data from both resources. Protein structure classification remains highly relevant for a diverse range of problems and settings.
蛋白质结构分类数据库(SCOP)以及类、结构、拓扑、同源性数据库(CATH)在过去20多年里一直是蛋白质结构分类的宝贵资源。SCOP(版本1)的开发于2009年6月随着SCOP 1.75的发布而结束。SCOPe(扩展版SCOP)数据库在经典SCOP层次结构的基础上持续发展,新增了超过33000个结构。我们试图评估这两个已有20年历史的资源所产生的影响,并为未来的发展提供指导。为此,我们调研了近期的文章,以了解结构分类数据的使用方式。在2012年至2013年发表的引用SCOP的571篇文章中,有439篇实际使用了该资源的数据。我们发现,使用类型在四个主要类别中分布较为均匀:A)研究蛋白质结构或进化(占文章的27%),B)训练和/或基准测试算法(占文章的28%),C)用SCOP分类扩充非SCOP数据集(占文章 的21%),D)研究单个蛋白质/一小部分蛋白质的分类(占文章的22%)。大多数文章描述的是计算研究,不过有11%描述的是纯实验研究,另有9%则两者都有涉及。我们研究了在158篇同时引用了这两个数据库的文章中CATH和SCOP是如何被使用的:虽然有些研究只使用了一个数据集,但大多数研究使用了来自这两个资源的数据。蛋白质结构分类对于各种不同的问题和场景仍然高度相关。