Flynt Abby, Daepp Madeleine I G
Department of Mathematics, Bucknell University, 701 Moore Ave, 17837, Lewisburg, PA, USA.
Integrated Studies in Land and Food Systems, The University of British Columbia Vancouver, 2329 West Mall, V6T 1Z4, Vancouver, BC, Canada.
Int J Health Geogr. 2015 Sep 4;14:25. doi: 10.1186/s12942-015-0017-5.
Obesity and diabetes are global public health concerns. Studies indicate a relationship between socioeconomic, demographic and environmental variables and the spatial patterns of diet-related chronic disease. In this paper, we propose a methodology using model-based clustering and variable selection to predict rates of obesity and diabetes. We test this method through an application in the northeastern United States.
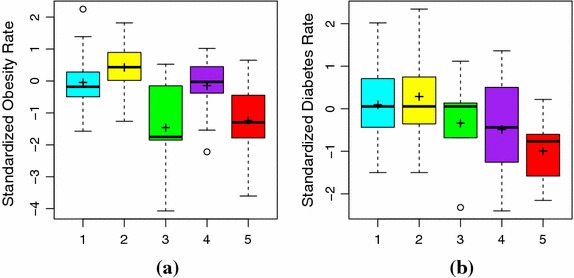
We use model-based clustering, an unsupervised learning approach, to find latent clusters of similar US counties based on a set of socioeconomic, demographic, and environmental variables chosen through the process of variable selection. We then use Analysis of Variance and Post-hoc Tukey comparisons to examine differences in rates of obesity and diabetes for the clusters from the resulting clustering solution.
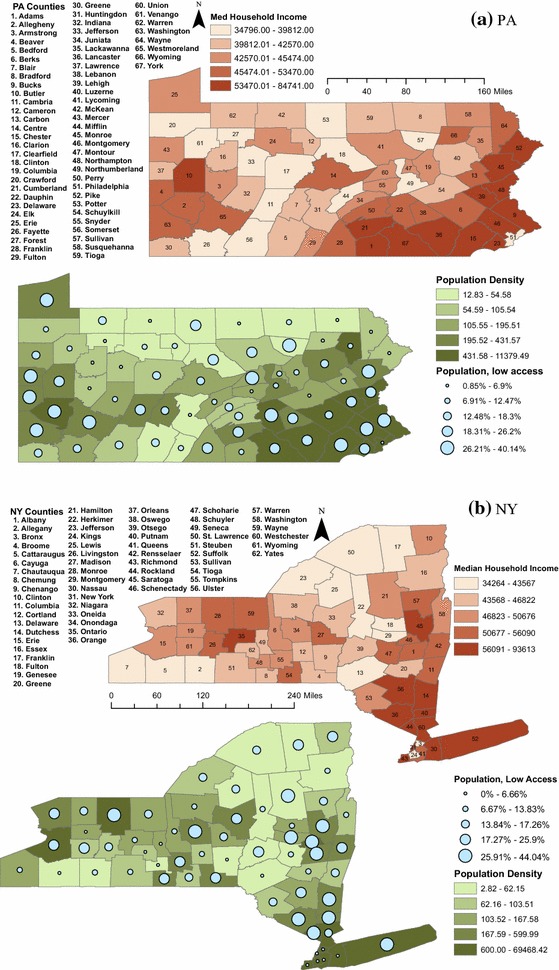
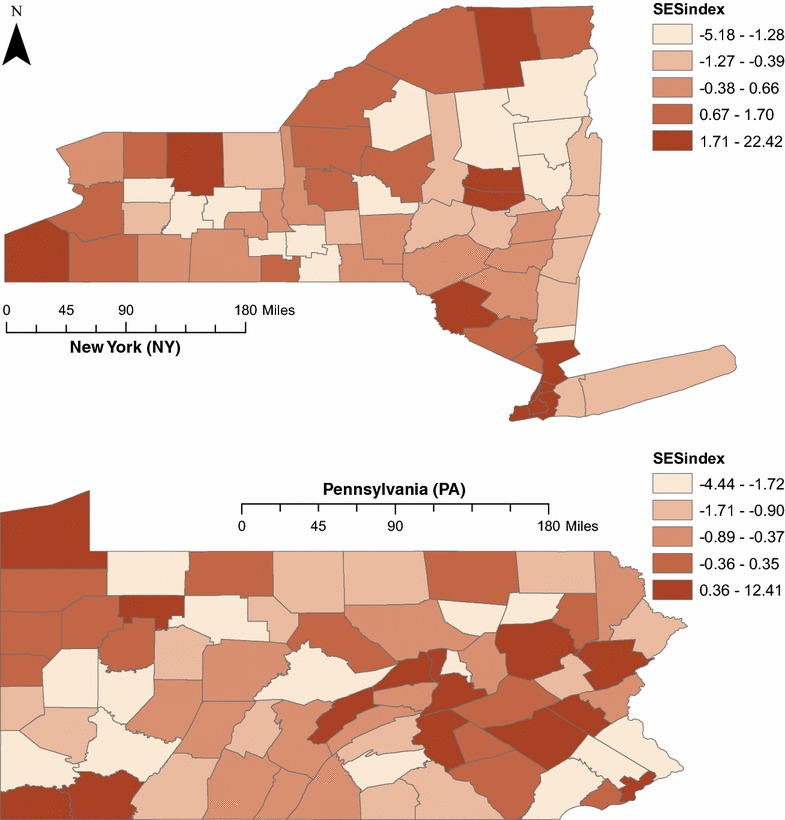
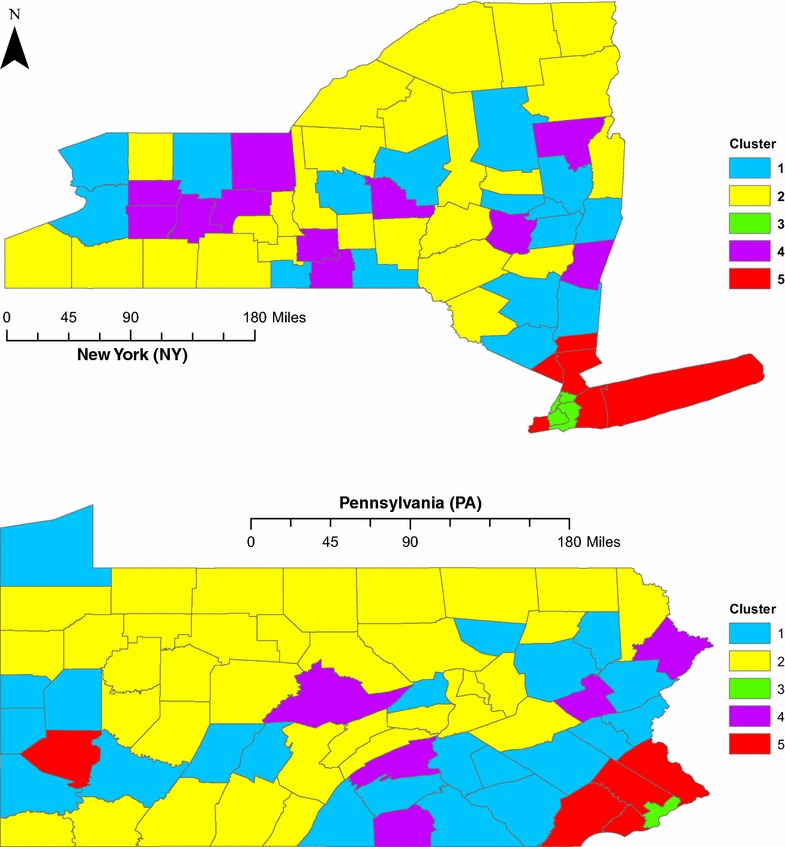
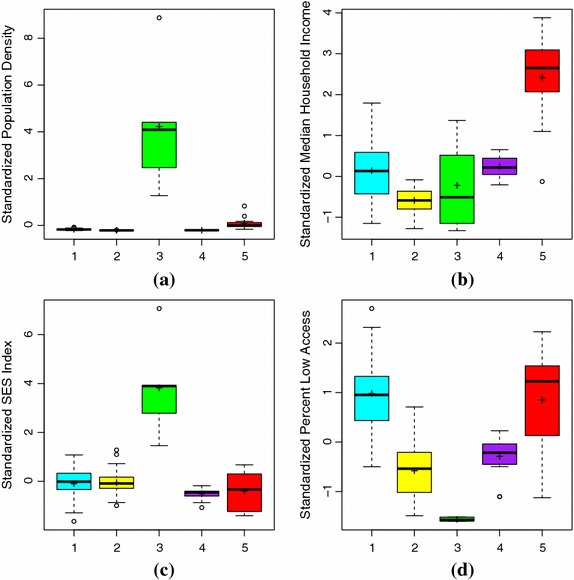
We find access to supermarkets, median household income, population density and socioeconomic status to be important in clustering the counties of two northeastern states. The results of the cluster analysis can be used to identify two sets of counties with significantly lower rates of diet-related chronic disease than those observed in the other identified clusters. These relatively healthy clusters are distinguished by the large central and large fringe metropolitan areas contained in their component counties. However, the relationship of socio-demographic factors and diet-related chronic disease is more complicated than previous research would suggest. Additionally, we find evidence of low food access in two clusters of counties adjacent to large central and fringe metropolitan areas. While food access has previously been seen as a problem of inner-city or remote rural areas, this study offers preliminary evidence of declining food access in suburban areas.
Model-based clustering with variable selection offers a new approach to the analysis of socioeconomic, demographic, and environmental data for diet-related chronic disease prediction. In a test application to two northeastern states, this method allows us to identify two sets of metropolitan counties with significantly lower diet-related chronic disease rates than those observed in most rural and suburban areas. Our method could be applied to larger geographic areas or other countries with comparable data sets, offering a promising method for researchers interested in the global increase in diet-related chronic disease.
肥胖和糖尿病是全球公共卫生问题。研究表明社会经济、人口统计学和环境变量与饮食相关慢性病的空间模式之间存在关联。在本文中,我们提出一种使用基于模型的聚类和变量选择来预测肥胖和糖尿病发生率的方法。我们通过在美国东北部的应用来测试此方法。
我们使用基于模型的聚类(一种无监督学习方法),根据通过变量选择过程选定的一组社会经济、人口统计学和环境变量,找出美国各县中相似的潜在聚类。然后,我们使用方差分析和事后 Tukey 比较来检验聚类分析结果中各聚类的肥胖和糖尿病发生率差异。
我们发现,超市可达性、家庭收入中位数、人口密度和社会经济地位对于东北部两个州各县的聚类很重要。聚类分析结果可用于识别两组县,其饮食相关慢性病发生率明显低于其他已识别聚类中的县。这些相对健康的聚类的特点是其组成县包含大型中心和大型边缘都市地区。然而,社会人口因素与饮食相关慢性病之间的关系比先前研究表明的更为复杂。此外,我们发现与大型中心和边缘都市地区相邻的两组县存在食品可达性低的证据。虽然食品可达性以前被视为市中心或偏远农村地区的问题,但本研究提供了郊区食品可达性下降的初步证据。
基于模型的聚类与变量选择为分析社会经济、人口统计学和环境数据以预测饮食相关慢性病提供了一种新方法。在对东北部两个州的测试应用中,此方法使我们能够识别两组都市县,其饮食相关慢性病发生率明显低于大多数农村和郊区地区。我们的方法可应用于更大的地理区域或具有可比数据集的其他国家,为关注全球饮食相关慢性病增加的研究人员提供了一种有前景的方法。