Ramnarine Shelina, Zhang Juan, Chen Li-Shiun, Culverhouse Robert, Duan Weimin, Hancock Dana B, Hartz Sarah M, Johnson Eric O, Olfson Emily, Schwantes-An Tae-Hwi, Saccone Nancy L
Department of Genetics, Washington University, St. Louis, Missouri, United States of America.
Chinese Academy of Sciences, Key Laboratory of Brain Function and Disease, School of Life Sciences, University of Science and Technology of China, Hefei, Anhui, China.
PLoS One. 2015 Oct 12;10(10):e0137601. doi: 10.1371/journal.pone.0137601. eCollection 2015.
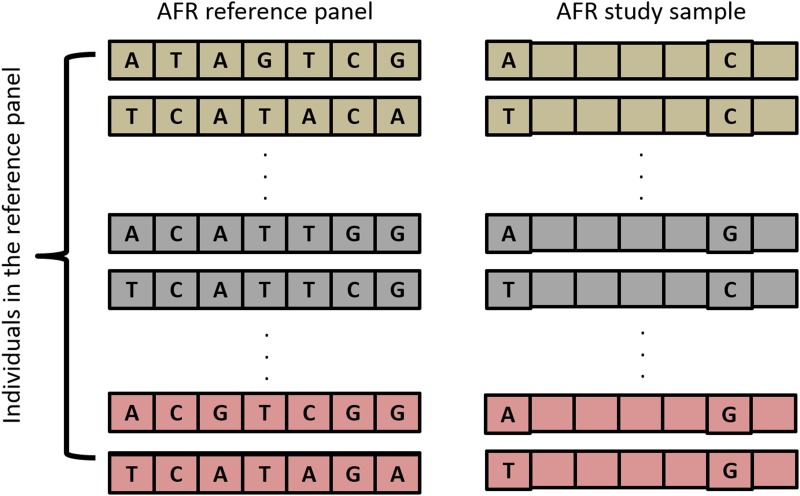
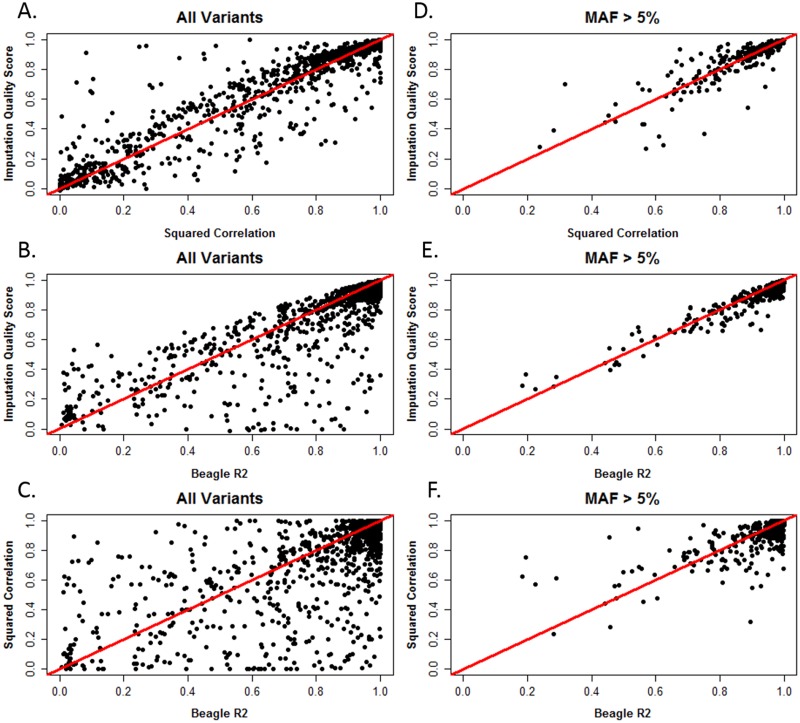
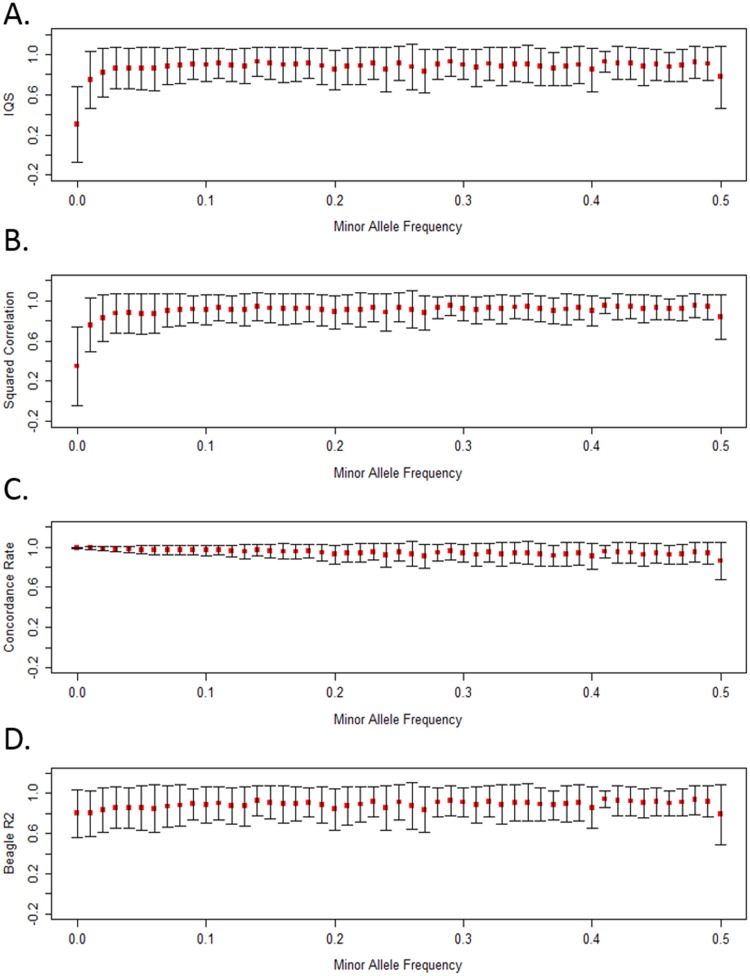
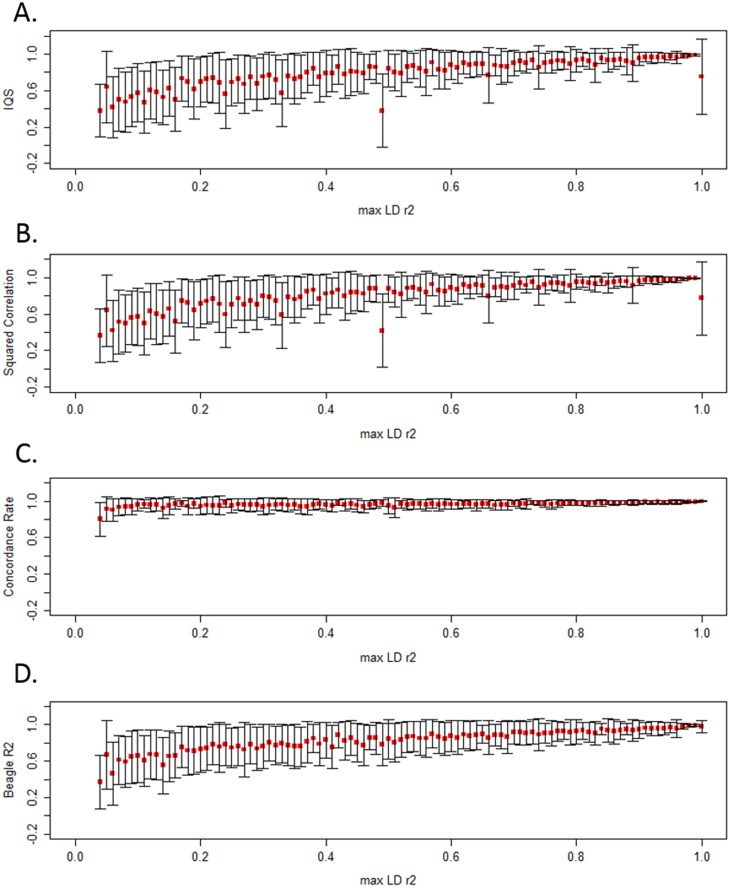
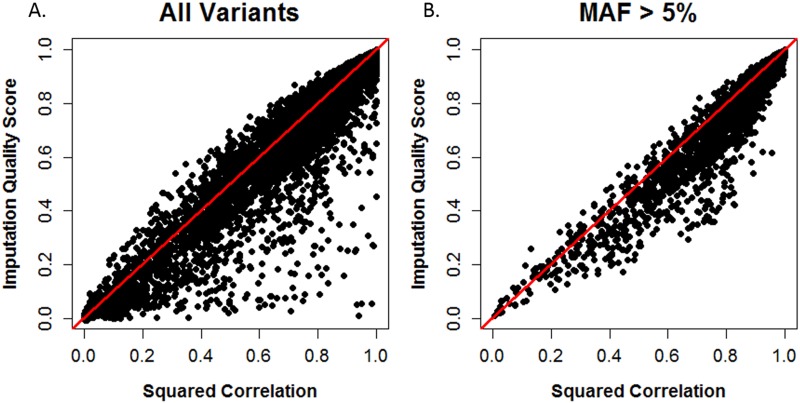
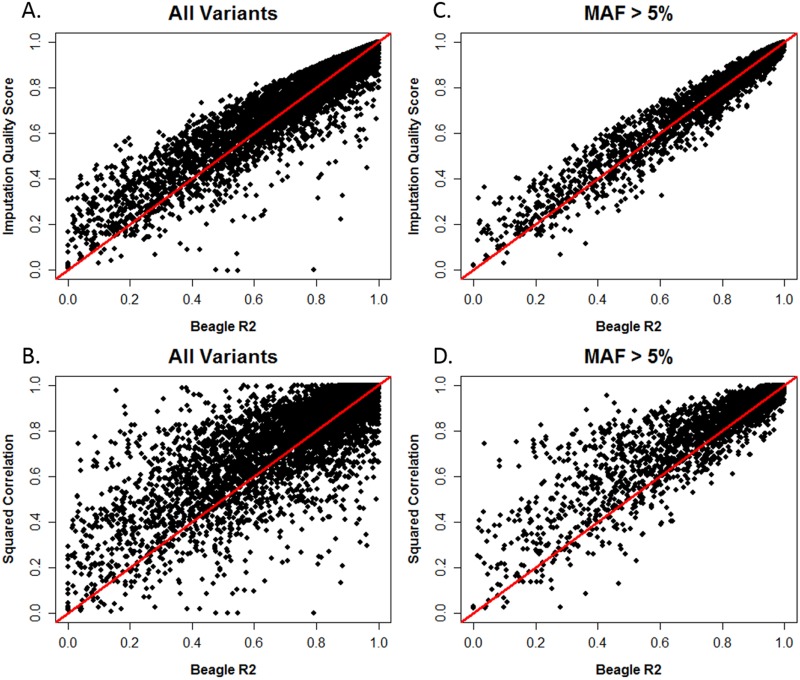
Imputation, the process of inferring genotypes for untyped variants, is used to identify and refine genetic association findings. Inaccuracies in imputed data can distort the observed association between variants and a disease. Many statistics are used to assess accuracy; some compare imputed to genotyped data and others are calculated without reference to true genotypes. Prior work has shown that the Imputation Quality Score (IQS), which is based on Cohen's kappa statistic and compares imputed genotype probabilities to true genotypes, appropriately adjusts for chance agreement; however, it is not commonly used. To identify differences in accuracy assessment, we compared IQS with concordance rate, squared correlation, and accuracy measures built into imputation programs. Genotypes from the 1000 Genomes reference populations (AFR N = 246 and EUR N = 379) were masked to match the typed single nucleotide polymorphism (SNP) coverage of several SNP arrays and were imputed with BEAGLE 3.3.2 and IMPUTE2 in regions associated with smoking behaviors. Additional masking and imputation was conducted for sequenced subjects from the Collaborative Genetic Study of Nicotine Dependence and the Genetic Study of Nicotine Dependence in African Americans (N = 1,481 African Americans and N = 1,480 European Americans). Our results offer further evidence that concordance rate inflates accuracy estimates, particularly for rare and low frequency variants. For common variants, squared correlation, BEAGLE R2, IMPUTE2 INFO, and IQS produce similar assessments of imputation accuracy. However, for rare and low frequency variants, compared to IQS, the other statistics tend to be more liberal in their assessment of accuracy. IQS is important to consider when evaluating imputation accuracy, particularly for rare and low frequency variants.
填补是指推断未分型变异基因型的过程,用于识别和完善基因关联研究结果。填补数据中的不准确信息可能会扭曲观察到的变异与疾病之间的关联。许多统计方法用于评估准确性;有些方法将填补数据与基因分型数据进行比较,而其他方法则在不参考真实基因型的情况下进行计算。先前的研究表明,基于科恩kappa统计量并将填补基因型概率与真实基因型进行比较的填补质量评分(IQS)能够适当调整随机一致性;然而,它并不常用。为了识别准确性评估中的差异,我们将IQS与一致性率、平方相关系数以及填补程序中内置的准确性度量进行了比较。对1000基因组参考人群(非洲裔N = 246,欧洲裔N = 379)的基因型进行掩码处理,以匹配几种单核苷酸多态性(SNP)芯片的分型SNP覆盖范围,并在与吸烟行为相关的区域使用BEAGLE 3.3.2和IMPUTE2进行填补。对来自尼古丁依赖协作基因研究和非裔美国人尼古丁依赖基因研究的测序受试者(1481名非裔美国人和1480名欧洲裔美国人)进行了额外的掩码处理和填补。我们的结果进一步证明,一致性率会夸大准确性估计,尤其是对于罕见和低频变异。对于常见变异,平方相关系数、BEAGLE R2、IMPUTE2 INFO和IQS对填补准确性的评估结果相似。然而,对于罕见和低频变异,与IQS相比,其他统计量在准确性评估上往往更为宽松。在评估填补准确性时,尤其是对于罕见和低频变异,IQS是一个重要的考虑因素。