Ito Makoto, Doya Kenji
Okinawa Institute of Science and Technology Graduate University, Onna-son Okinawa, Japan.
PLoS Comput Biol. 2015 Nov 3;11(11):e1004540. doi: 10.1371/journal.pcbi.1004540. eCollection 2015 Nov.
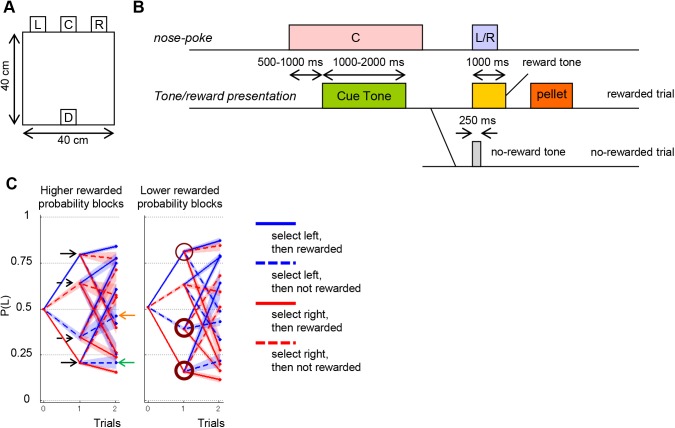
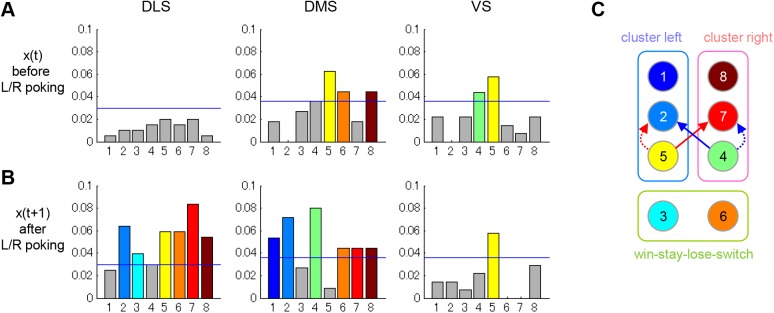
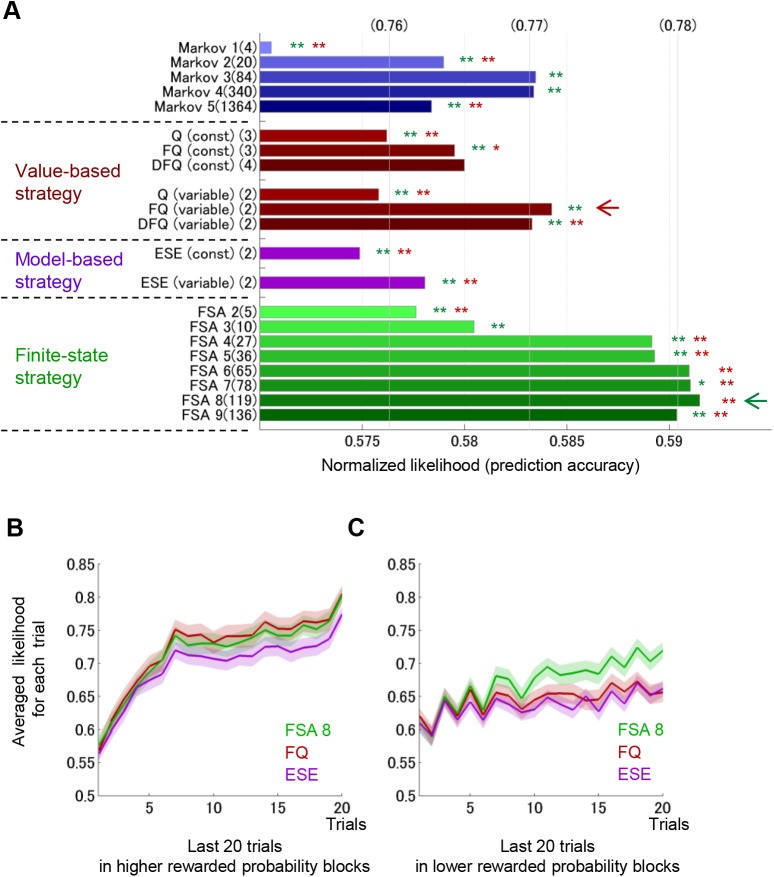
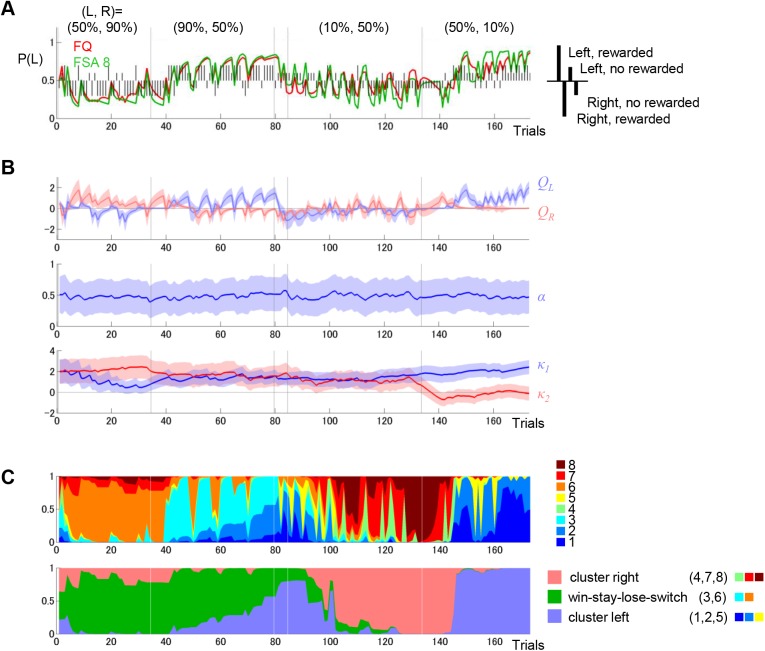
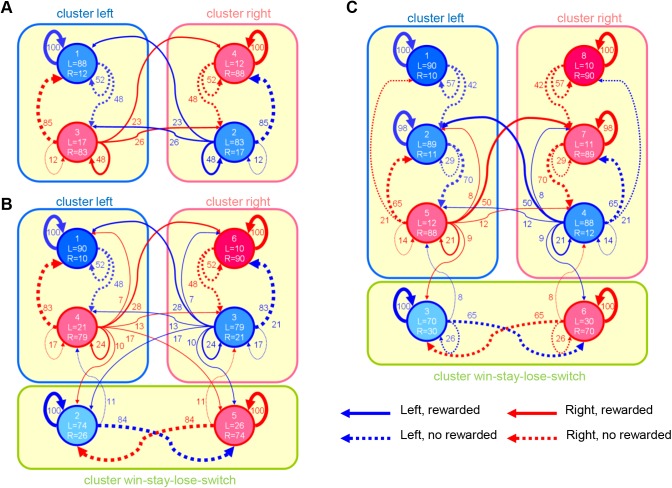
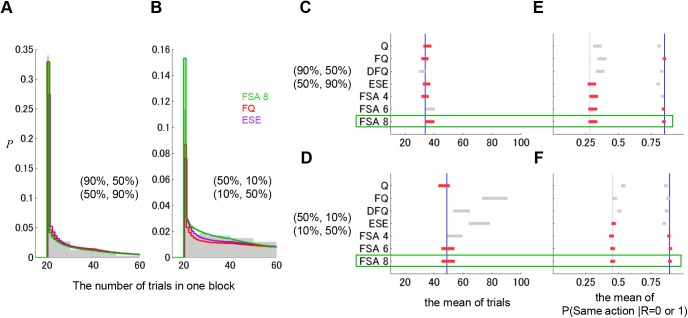
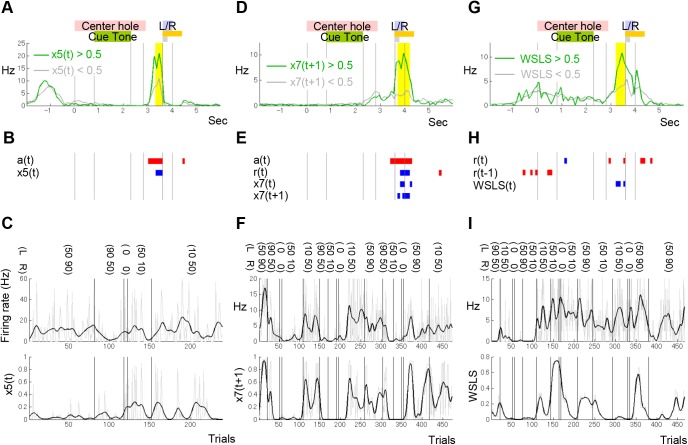
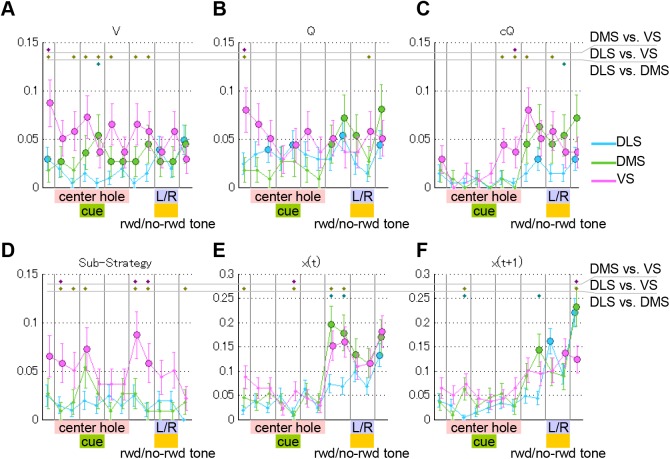
Previous theoretical studies of animal and human behavioral learning have focused on the dichotomy of the value-based strategy using action value functions to predict rewards and the model-based strategy using internal models to predict environmental states. However, animals and humans often take simple procedural behaviors, such as the "win-stay, lose-switch" strategy without explicit prediction of rewards or states. Here we consider another strategy, the finite state-based strategy, in which a subject selects an action depending on its discrete internal state and updates the state depending on the action chosen and the reward outcome. By analyzing choice behavior of rats in a free-choice task, we found that the finite state-based strategy fitted their behavioral choices more accurately than value-based and model-based strategies did. When fitted models were run autonomously with the same task, only the finite state-based strategy could reproduce the key feature of choice sequences. Analyses of neural activity recorded from the dorsolateral striatum (DLS), the dorsomedial striatum (DMS), and the ventral striatum (VS) identified significant fractions of neurons in all three subareas for which activities were correlated with individual states of the finite state-based strategy. The signal of internal states at the time of choice was found in DMS, and for clusters of states was found in VS. In addition, action values and state values of the value-based strategy were encoded in DMS and VS, respectively. These results suggest that both the value-based strategy and the finite state-based strategy are implemented in the striatum.
以往关于动物和人类行为学习的理论研究主要集中在基于价值的策略(使用动作价值函数来预测奖励)和基于模型的策略(使用内部模型来预测环境状态)的二分法上。然而,动物和人类经常采取简单的程序性行为,比如“赢则继续,输则转换”策略,而无需明确预测奖励或状态。在这里,我们考虑另一种策略,即基于有限状态的策略,在这种策略中,主体根据其离散的内部状态选择一个动作,并根据所选择的动作和奖励结果更新状态。通过分析大鼠在自由选择任务中的选择行为,我们发现基于有限状态的策略比基于价值和基于模型的策略更准确地拟合了它们的行为选择。当使用相同任务对拟合模型进行自主运行时,只有基于有限状态的策略能够重现选择序列的关键特征。对从背外侧纹状体(DLS)、背内侧纹状体(DMS)和腹侧纹状体(VS)记录的神经活动分析表明,在所有三个子区域中都有相当一部分神经元的活动与基于有限状态策略的个体状态相关。在DMS中发现了选择时内部状态的信号,在VS中发现了状态簇的信号。此外,基于价值策略的动作值和状态值分别在DMS和VS中进行编码。这些结果表明,基于价值的策略和基于有限状态的策略都在纹状体中得以实施。