Garcia Danilo, MacDonald Shane, Archer Trevor
Blekinge Center of Competence, Blekinge County Council , Karlskrona , Sweden ; Department of Psychology, University of Gothenburg , Gothenburg , Sweden ; Network for Empowerment and Well-Being, University of Gothenburg , Gothenburg , Sweden ; Centre for Ethics, Law and Mental Health (CELAM), University of Gothenburg , Gothenburg , Sweden.
Network for Empowerment and Well-Being, University of Gothenburg , Gothenburg , Sweden ; Center for Health and Medical Psychology (CHAMP), Psychological Institution, Örebro University , Örebro , Sweden ; Psychological Links of Unique Strengths (PLUS), Psychological Institution, Stockholm University , Stockholm , Sweden.
PeerJ. 2015 Oct 29;3:e1380. doi: 10.7717/peerj.1380. eCollection 2015.
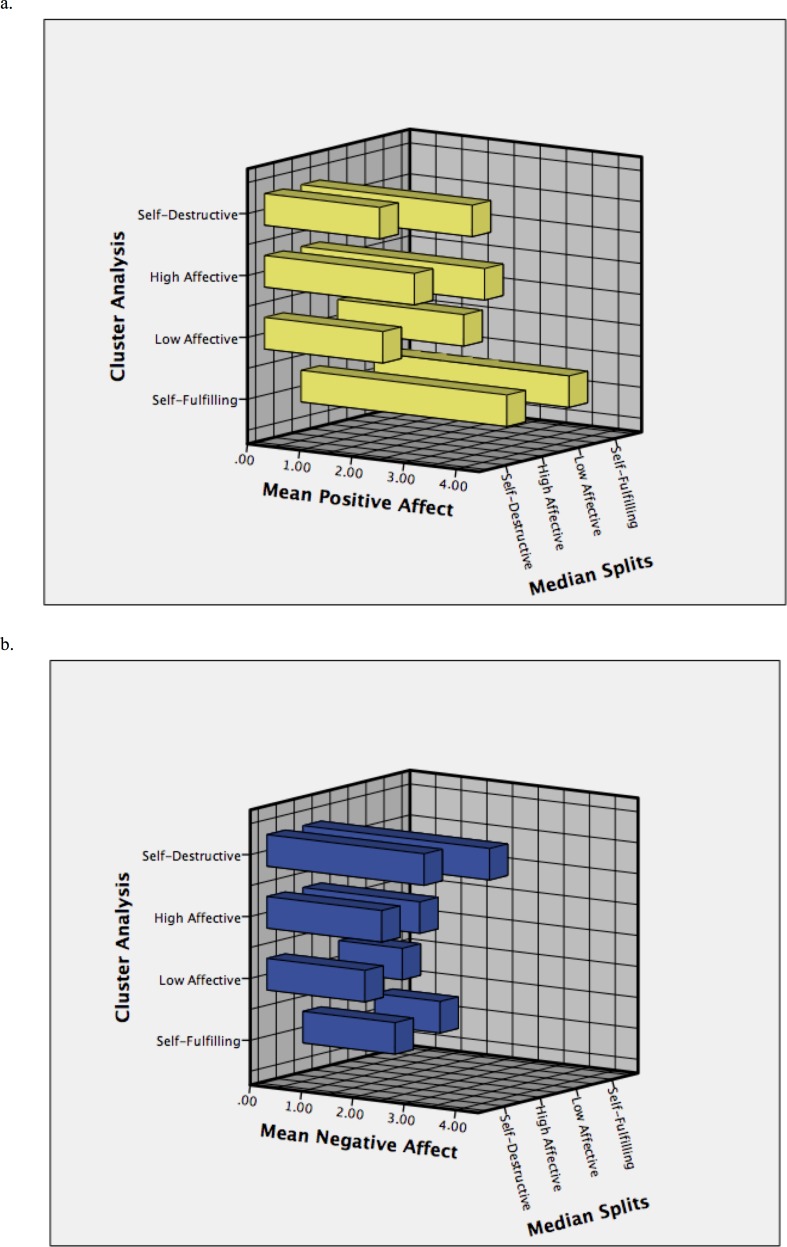
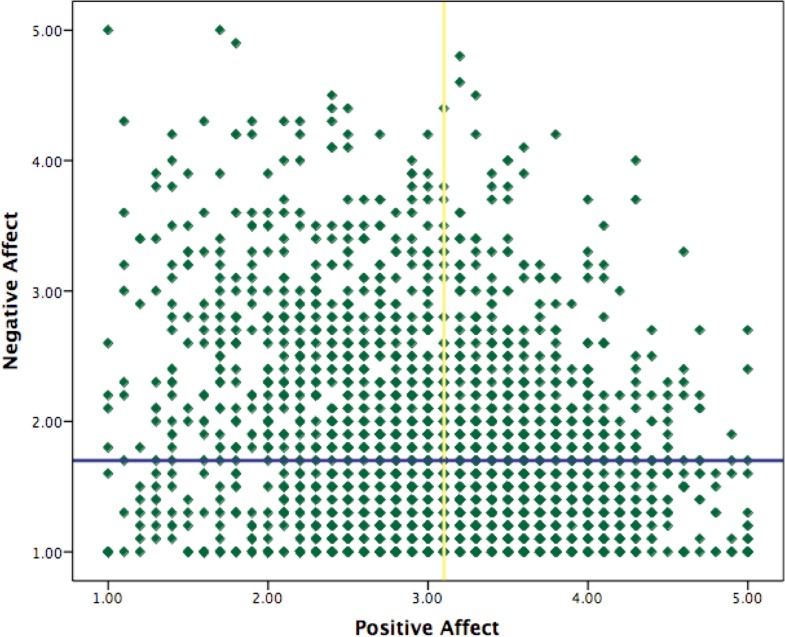
Background. The notion of the affective system as being composed of two dimensions led Archer and colleagues to the development of the affective profiles model. The model consists of four different profiles based on combinations of individuals' experience of high/low positive and negative affect: self-fulfilling, low affective, high affective, and self-destructive. During the past 10 years, an increasing number of studies have used this person-centered model as the backdrop for the investigation of between and within individual differences in ill-being and well-being. The most common approach to this profiling is by dividing individuals' scores of self-reported affect using the median of the population as reference for high/low splits. However, scores just-above and just-below the median might become high and low by arbitrariness, not by reality. Thus, it is plausible to criticize the validity of this variable-oriented approach. Our aim was to compare the median splits approach with a person-oriented approach, namely, cluster analysis. Method. The participants (N = 2, 225) were recruited through Amazons' Mechanical Turk and asked to self-report affect using the Positive Affect Negative Affect Schedule. We compared the profiles' homogeneity and Silhouette coefficients to discern differences in homogeneity and heterogeneity between approaches. We also conducted exact cell-wise analyses matching the profiles from both approaches and matching profiles and gender to investigate profiling agreement with respect to affectivity levels and affectivity and gender. All analyses were conducted using the ROPstat software. Results. The cluster approach (weighted average of cluster homogeneity coefficients = 0.62, Silhouette coefficients = 0.68) generated profiles with greater homogeneity and more distinctive from each other compared to the median splits approach (weighted average of cluster homogeneity coefficients = 0.75, Silhouette coefficients = 0.59). Most of the participants (n = 1,736, 78.0%) were allocated to the same profile (Rand Index = .83), however, 489 (21.98%) were allocated to different profiles depending on the approach. Both approaches allocated females and males similarly in three of the four profiles. Only the cluster analysis approach classified men significantly more often than chance to a self-fulfilling profile (type) and females less often than chance to this very same profile (antitype). Conclusions. Although the question whether one approach is more appropriate than the other is still without answer, the cluster method allocated individuals to profiles that are more in accordance with the conceptual basis of the model and also to expected gender differences. More importantly, regardless of the approach, our findings suggest that the model mirrors a complex and dynamic adaptive system.

背景。情感系统由两个维度组成的概念促使阿彻及其同事开发了情感特征模型。该模型基于个体高/低积极和消极情感体验的组合,由四种不同的特征组成:自我实现型、低情感型、高情感型和自我毁灭型。在过去十年中,越来越多的研究以这种以人为主的模型为背景,调查个体间和个体内幸福感和不幸福感的差异。这种特征分析最常见的方法是将个体自我报告情感的分数,以总体中位数为参考进行高/低划分。然而,略高于和略低于中位数的分数可能只是随意地成为高分和低分,而非基于实际情况。因此,对这种以变量为导向的方法的有效性提出批评是合理的。我们的目的是将中位数划分方法与一种以人为本的方法,即聚类分析进行比较。
方法。通过亚马逊的土耳其机器人招募了参与者(N = 2225),并要求他们使用积极情感消极情感量表自我报告情感。我们比较了这些特征的同质性和轮廓系数,以辨别不同方法在同质性和异质性方面的差异。我们还进行了精确到单元格的分析,将两种方法得到的特征进行匹配,并将特征与性别进行匹配,以研究在情感水平、情感与性别方面的特征分析一致性。所有分析均使用ROPstat软件进行。
结果。与中位数划分方法(聚类同质性系数加权平均值 = 0.75,轮廓系数 = 0.59)相比,聚类方法(聚类同质性系数加权平均值 = 0.62,轮廓系数 = 0.68)生成的特征具有更高的同质性,且彼此之间更具独特性。大多数参与者(n = 1736,78.0%)被分配到相同的特征(兰德指数 = 0.83),然而,489名(21.98%)参与者根据方法的不同被分配到不同的特征。在四个特征中的三个特征上,两种方法对男性和女性的分配方式相似。只有聚类分析方法将男性显著高于随机概率地分类到自我实现型特征(类型),而将女性低于随机概率地分类到同一特征(反类型)。
结论。虽然一种方法是否比另一种方法更合适的问题仍未得到解答,但聚类方法将个体分配到的特征更符合该模型的概念基础,也符合预期中的性别差异。更重要的是——无论采用哪种方法,我们的研究结果表明该模型反映了一个复杂且动态的自适应系统。