Alocci Davide, Mariethoz Julien, Horlacher Oliver, Bolleman Jerven T, Campbell Matthew P, Lisacek Frederique
Proteome Informatics Group, SIB Swiss Institute of Bioinformatics, Geneva, 1211, Switzerland.
Computer Science Department, University of Geneva, Geneva, 1227, Switzerland.
PLoS One. 2015 Dec 14;10(12):e0144578. doi: 10.1371/journal.pone.0144578. eCollection 2015.
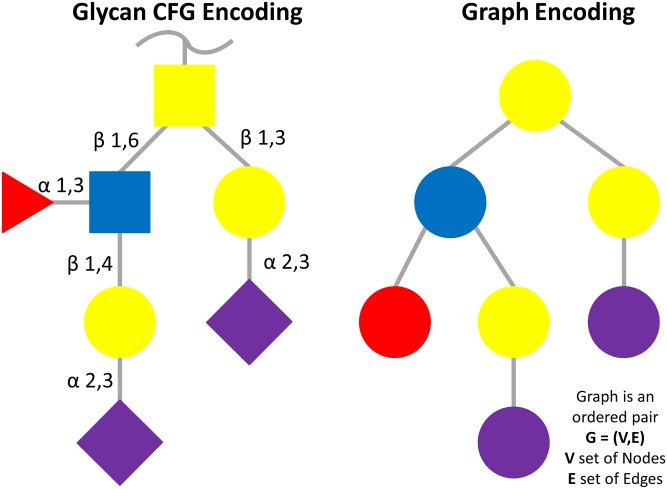
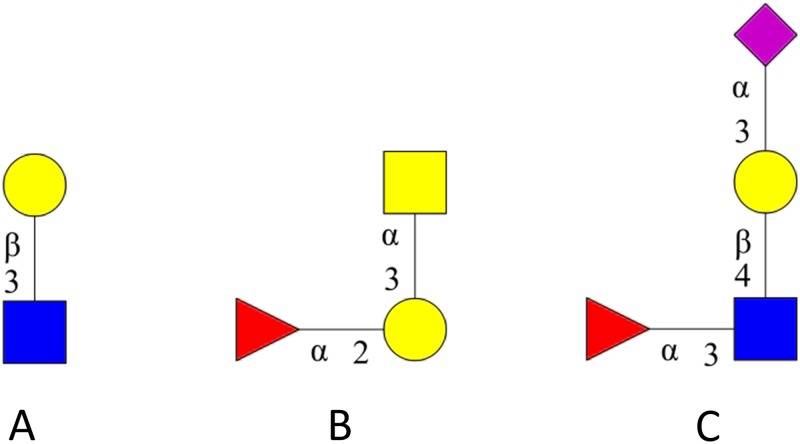
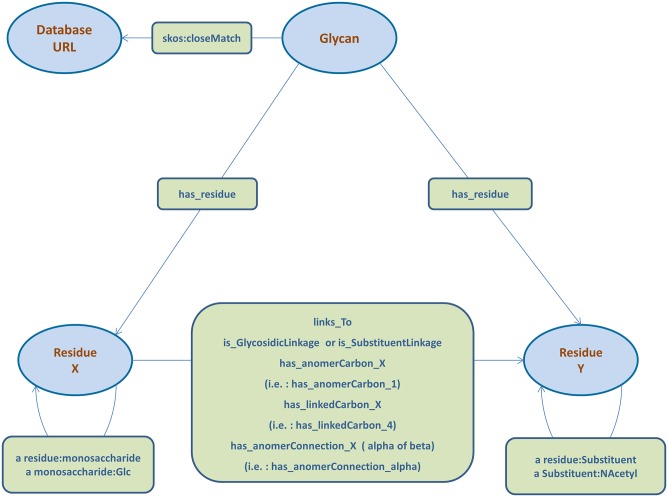
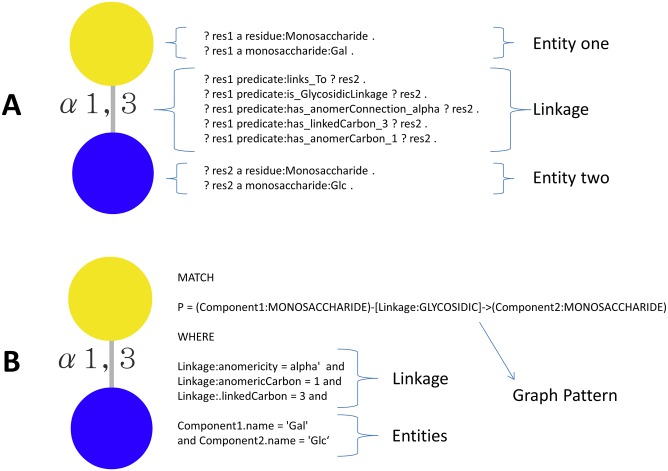
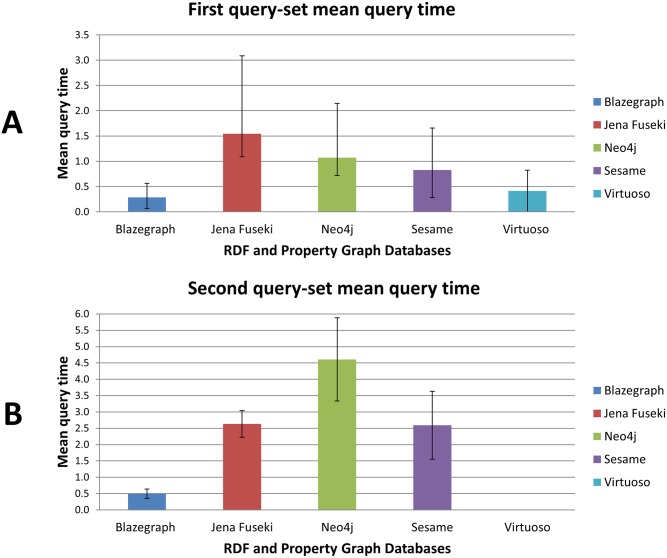
Resource description framework (RDF) and Property Graph databases are emerging technologies that are used for storing graph-structured data. We compare these technologies through a molecular biology use case: glycan substructure search. Glycans are branched tree-like molecules composed of building blocks linked together by chemical bonds. The molecular structure of a glycan can be encoded into a direct acyclic graph where each node represents a building block and each edge serves as a chemical linkage between two building blocks. In this context, Graph databases are possible software solutions for storing glycan structures and Graph query languages, such as SPARQL and Cypher, can be used to perform a substructure search. Glycan substructure searching is an important feature for querying structure and experimental glycan databases and retrieving biologically meaningful data. This applies for example to identifying a region of the glycan recognised by a glycan binding protein (GBP). In this study, 19,404 glycan structures were selected from GlycomeDB (www.glycome-db.org) and modelled for being stored into a RDF triple store and a Property Graph. We then performed two different sets of searches and compared the query response times and the results from both technologies to assess performance and accuracy. The two implementations produced the same results, but interestingly we noted a difference in the query response times. Qualitative measures such as portability were also used to define further criteria for choosing the technology adapted to solving glycan substructure search and other comparable issues.
资源描述框架(RDF)和属性图数据库是用于存储图结构数据的新兴技术。我们通过一个分子生物学用例——聚糖子结构搜索,来比较这些技术。聚糖是由通过化学键连接在一起的构建块组成的分支树状分子。聚糖的分子结构可以编码为一个有向无环图,其中每个节点代表一个构建块,每条边代表两个构建块之间的化学键。在这种情况下,图数据库是存储聚糖结构的可能软件解决方案,并且图查询语言,如SPARQL和Cypher,可用于执行子结构搜索。聚糖子结构搜索是查询结构和实验性聚糖数据库以及检索具有生物学意义的数据的一项重要功能。例如,这适用于识别聚糖结合蛋白(GBP)识别的聚糖区域。在本研究中,从GlycomeDB(www.glycome-db.org)中选择了19404个聚糖结构,并对其进行建模以便存储到RDF三元组存储和属性图中。然后我们执行了两组不同的搜索,并比较了两种技术的查询响应时间和结果,以评估性能和准确性。两种实现产生了相同的结果,但有趣的是,我们注意到查询响应时间存在差异。诸如可移植性等定性指标也被用于定义进一步的标准,以选择适合解决聚糖子结构搜索及其他类似问题的技术。