Cochrane Guy, Karsch-Mizrachi Ilene, Takagi Toshihisa
European Molecular Biology Laboratory, European Bioinformatics Institute (EMBL-EBI), Wellcome Genome Campus, Hinxton, Cambridge CB10 1SD, UK
National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Bethesda, MD 20894, USA.
Nucleic Acids Res. 2016 Jan 4;44(D1):D48-50. doi: 10.1093/nar/gkv1323. Epub 2015 Dec 10.
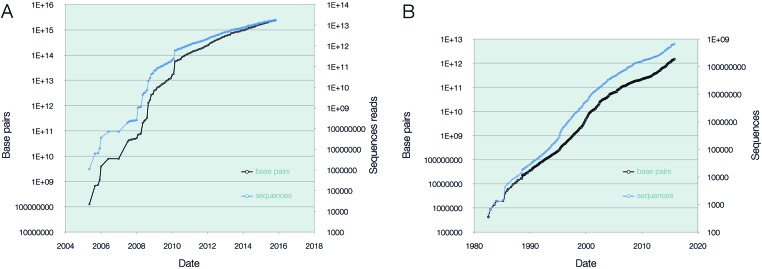
The International Nucleotide Sequence Database Collaboration (INSDC; http://www.insdc.org) comprises three global partners committed to capturing, preserving and providing comprehensive public-domain nucleotide sequence information. The INSDC establishes standards, formats and protocols for data and metadata to make it easier for individuals and organisations to submit their nucleotide data reliably to public archives. This work enables the continuous, global exchange of information about living things. Here we present an update of the INSDC in 2015, including data growth and diversification, new standards and requirements by publishers for authors to submit their data to the public archives. The INSDC serves as a model for data sharing in the life sciences.