Kreiter Clarence D, Wilson Adam B, Humbert Aloysius J, Wade Patricia A
Department of Family Medicine, University of Iowa College of Medicine, Iowa City, IA, USA.
Office of Consultation and Research in Medical Education, University of Iowa College of Medicine, Iowa City, IA, USA;
Med Educ Online. 2016 Feb 23;21:29279. doi: 10.3402/meo.v21.29279. eCollection 2016.
When ratings of student performance within the clerkship consist of a variable number of ratings per clinical teacher (rater), an important measurement question arises regarding how to combine such ratings to accurately summarize performance. As previous G studies have not estimated the independent influence of occasion and rater facets in observational ratings within the clinic, this study was designed to provide estimates of these two sources of error.
During 2 years of an emergency medicine clerkship at a large midwestern university, 592 students were evaluated an average of 15.9 times. Ratings were performed at the end of clinical shifts, and students often received multiple ratings from the same rater. A completely nested G study model (occasion: rater: person) was used to analyze sampled rating data.
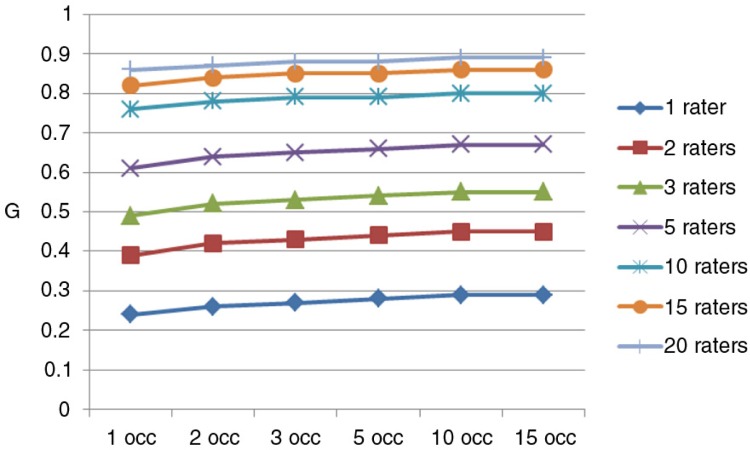
The variance component (VC) related to occasion was small relative to the VC associated with rater. The D study clearly demonstrates that having a preceptor rate a student on multiple occasions does not substantially enhance the reliability of a clerkship performance summary score.
Although further research is needed, it is clear that case-specific factors do not explain the low correlation between ratings and that having one or two raters repeatedly rate a student on different occasions/cases is unlikely to yield a reliable mean score. This research suggests that it may be more efficient to have a preceptor rate a student just once. However, when multiple ratings from a single preceptor are available for a student, it is recommended that a mean of the preceptor's ratings be used to calculate the student's overall mean performance score.
当临床实习期间学生表现的评分由每位临床教师(评分者)给出的不同数量的评分组成时,就会出现一个重要的测量问题,即如何合并这些评分以准确总结表现。由于先前的G研究尚未估计临床观察评分中场合和评分者因素的独立影响,本研究旨在提供这两种误差来源的估计值。
在中西部一所大型大学进行的两年急诊医学临床实习期间,对592名学生平均进行了15.9次评估。评分在临床轮班结束时进行,学生经常从同一位评分者那里获得多个评分。使用完全嵌套的G研究模型(场合:评分者:个体)来分析抽样的评分数据。
与场合相关的方差分量(VC)相对于与评分者相关的VC较小。D研究清楚地表明,让带教老师多次对学生进行评分并不能显著提高临床实习表现总结分数的可靠性。
尽管需要进一步研究,但很明显,具体病例因素并不能解释评分之间的低相关性,并且让一两名评分者在不同场合/病例下反复对学生进行评分不太可能产生可靠的平均分。这项研究表明,让带教老师只对学生进行一次评分可能更有效。然而,当学生有来自同一位带教老师的多个评分时,建议使用带教老师评分的平均值来计算学生的总体平均表现分数。