Papanikolaou Yannis, Tsoumakas Grigorios, Laliotis Manos, Markantonatos Nikos, Vlahavas Ioannis
Department of Computer Science, Aristotle University, Thessaloniki, 54124, Greece.
Atypon, 5201 Great America Parkway Suite 510, Santa Clara, 95054, CA, USA.
J Biomed Semantics. 2017 Sep 22;8(1):43. doi: 10.1186/s13326-017-0150-0.
In this paper we present the approach that we employed to deal with large scale multi-label semantic indexing of biomedical papers. This work was mainly implemented within the context of the BioASQ challenge (2013-2017), a challenge concerned with biomedical semantic indexing and question answering.
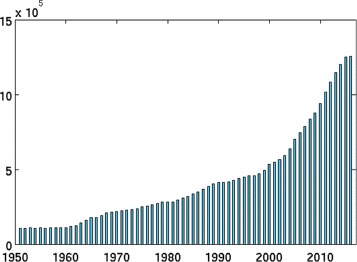
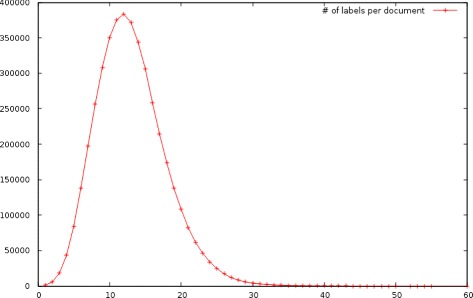
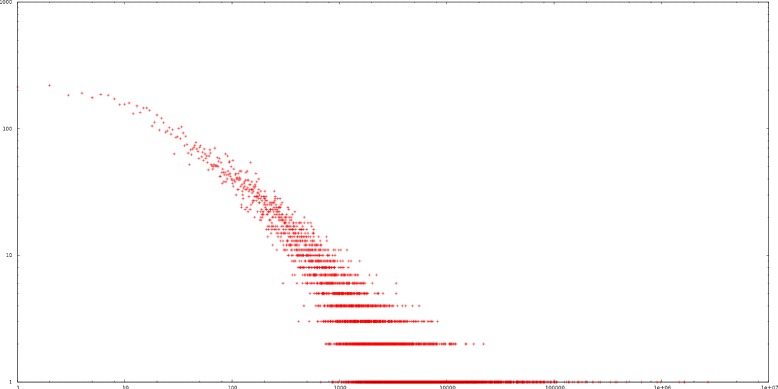
Our main contribution is a MUlti-Label Ensemble method (MULE) that incorporates a McNemar statistical significance test in order to validate the combination of the constituent machine learning algorithms. Some secondary contributions include a study on the temporal aspects of the BioASQ corpus (observations apply also to the BioASQ's super-set, the PubMed articles collection) and the proper parametrization of the algorithms used to deal with this challenging classification task.
The ensemble method that we developed is compared to other approaches in experimental scenarios with subsets of the BioASQ corpus giving positive results. In our participation in the BioASQ challenge we obtained the first place in 2013 and the second place in the four following years, steadily outperforming MTI, the indexing system of the National Library of Medicine (NLM).
The results of our experimental comparisons, suggest that employing a statistical significance test to validate the ensemble method's choices, is the optimal approach for ensembling multi-label classifiers, especially in contexts with many rare labels.
在本文中,我们介绍了用于处理生物医学论文大规模多标签语义索引的方法。这项工作主要是在BioASQ挑战赛(2013 - 2017年)的背景下实施的,该挑战赛涉及生物医学语义索引和问答。
我们的主要贡献是一种多标签集成方法(MULE),它纳入了麦克尼马尔统计显著性检验,以验证组成机器学习算法的组合。一些次要贡献包括对BioASQ语料库时间方面的研究(观察结果也适用于BioASQ的超集,即PubMed文章集合)以及用于处理这一具有挑战性分类任务的算法的适当参数化。
我们开发的集成方法在使用BioASQ语料库子集的实验场景中与其他方法进行了比较,取得了积极成果。在我们参与BioASQ挑战赛的过程中,我们在2013年获得了第一名,并在随后的四年中获得了第二名,持续优于美国国立医学图书馆(NLM)的索引系统MTI。
我们实验比较的结果表明,采用统计显著性检验来验证集成方法的选择,是集成多标签分类器的最佳方法,特别是在有许多稀有标签的情况下。