Department of Molecular Carcinogenesis, The Netherlands Cancer Institute, Plesmanlaan 121, 1066CX Amsterdam, The Netherlands.
Department of EEMCS, Delft University of Technology, Mekelweg 4, 2628CD Delft, The Netherlands.
Nat Commun. 2016 Jul 11;7:12159. doi: 10.1038/ncomms12159.
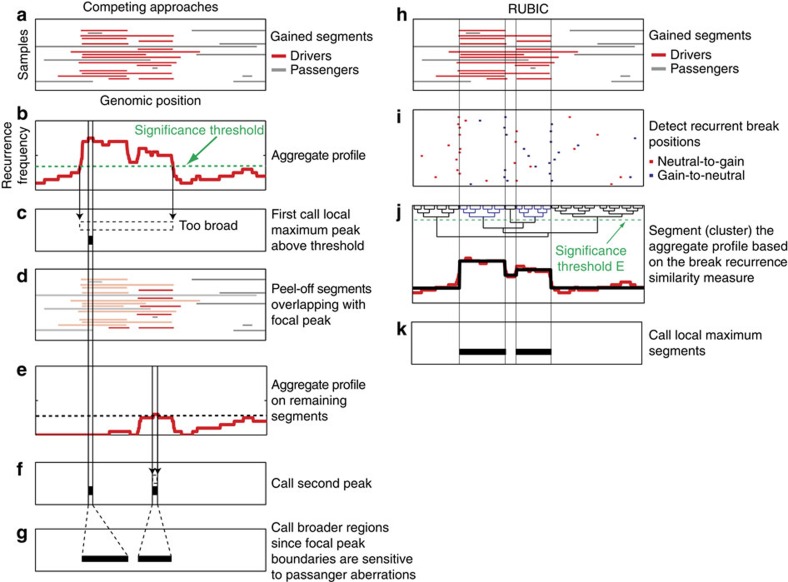
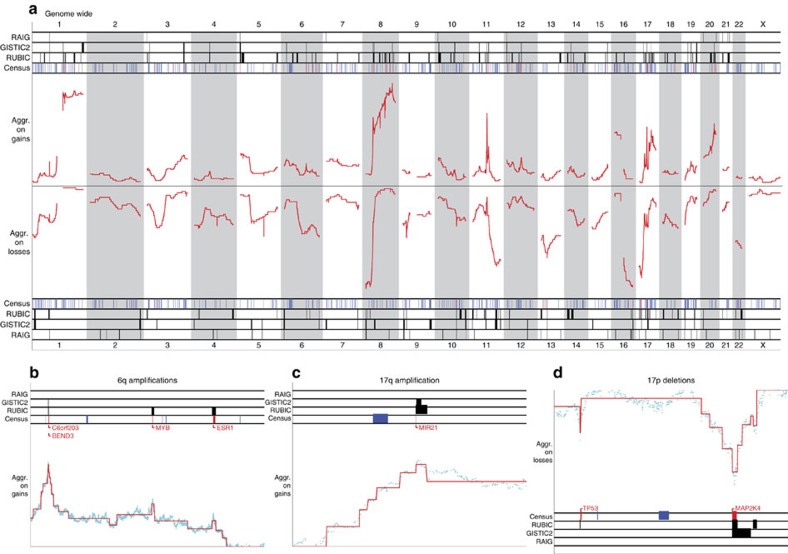
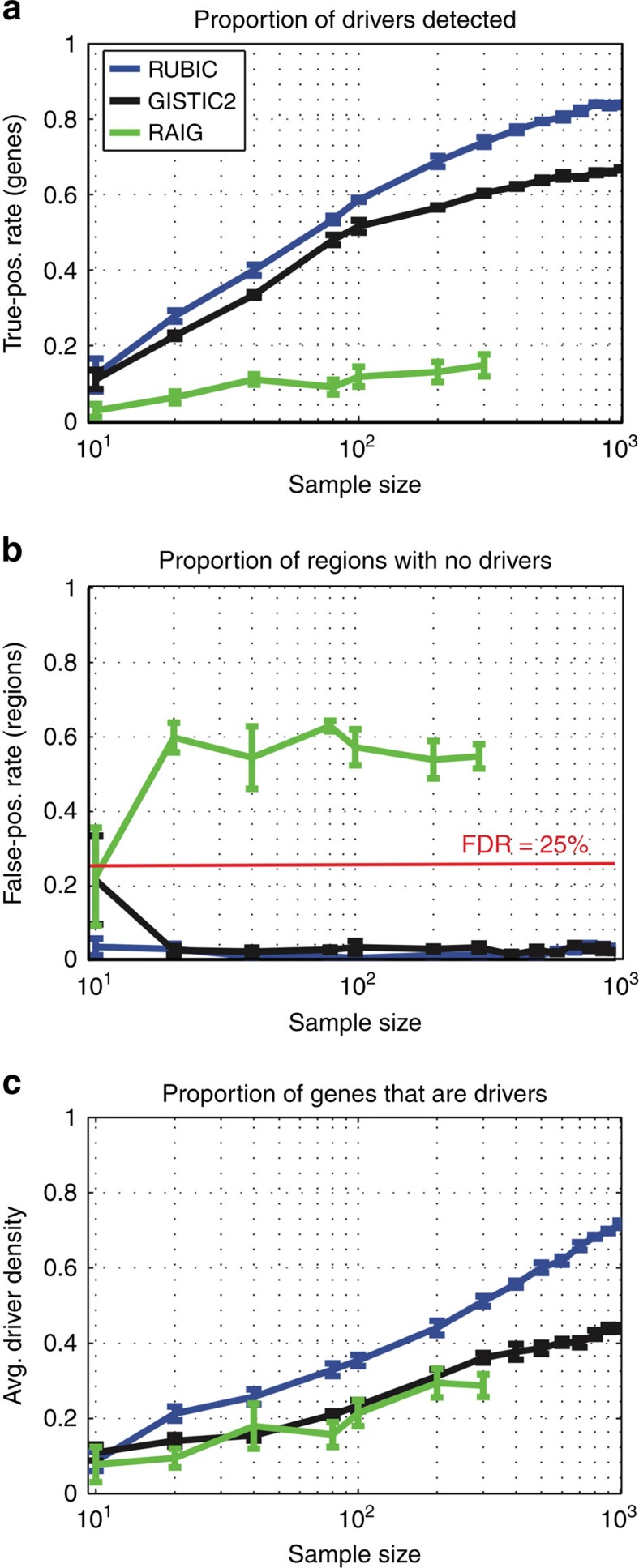
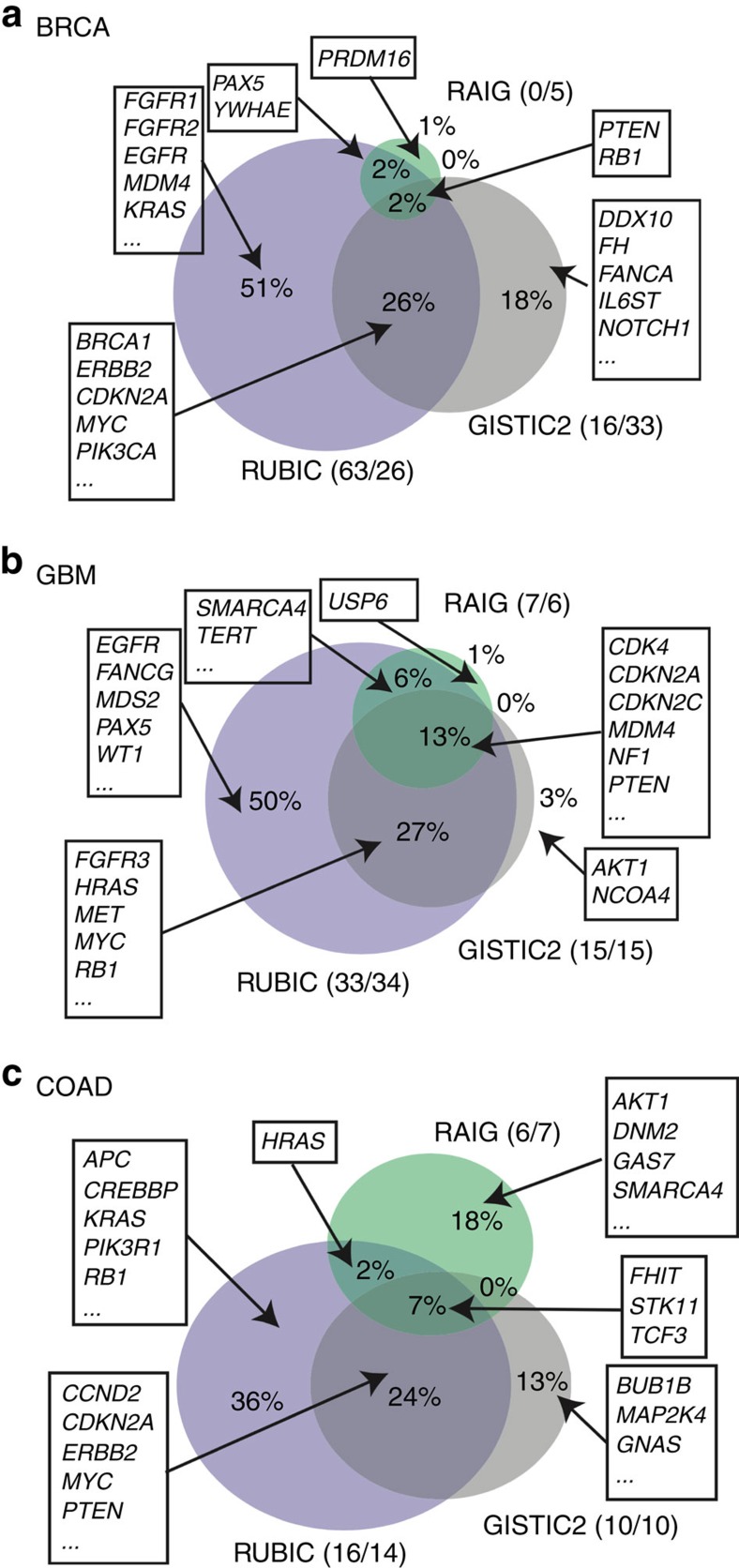
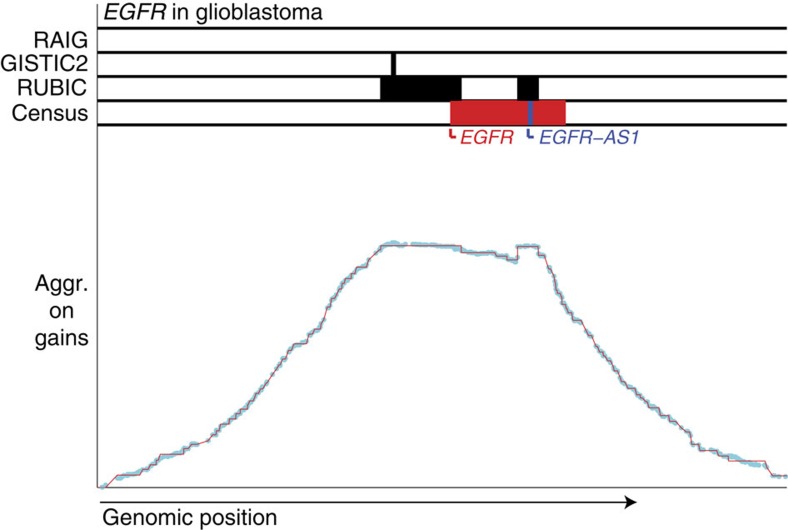
The frequent recurrence of copy number aberrations across tumour samples is a reliable hallmark of certain cancer driver genes. However, state-of-the-art algorithms for detecting recurrent aberrations fail to detect several known drivers. In this study, we propose RUBIC, an approach that detects recurrent copy number breaks, rather than recurrently amplified or deleted regions. This change of perspective allows for a simplified approach as recursive peak splitting procedures and repeated re-estimation of the background model are avoided. Furthermore, we control the false discovery rate on the level of called regions, rather than at the probe level, as in competing algorithms. We benchmark RUBIC against GISTIC2 (a state-of-the-art approach) and RAIG (a recently proposed approach) on simulated copy number data and on three SNP6 and NGS copy number data sets from TCGA. We show that RUBIC calls more focal recurrent regions and identifies a much larger fraction of known cancer genes.
肿瘤样本中经常出现的拷贝数异常是某些癌症驱动基因的可靠特征。然而,用于检测重现异常的最先进算法未能检测到几个已知的驱动基因。在这项研究中,我们提出了 RUBIC 方法,该方法检测重现的拷贝数断裂,而不是重现的扩增或缺失区域。这种视角的改变允许采用简化的方法,因为避免了递归峰分裂过程和背景模型的重复重新估计。此外,我们在调用区域的水平上控制假发现率,而不是像竞争算法那样在探针水平上控制。我们在模拟拷贝数数据以及来自 TCGA 的三个 SNP6 和 NGS 拷贝数数据集上,将 RUBIC 与 GISTIC2(一种最先进的方法)和 RAIG(一种最近提出的方法)进行了基准测试。我们表明,RUBIC 调用了更多焦点重现区域,并鉴定出了更大比例的已知癌症基因。