Mayr Andreas, Hofner Benjamin, Schmid Matthias
Institut für Medizininformatik, Biometrie und Epidemiologie, Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU), Waldstr. 6, Erlangen, 91054, Germany.
Institut für Medizinische Biometrie, Informatik und Epidemiologie, Rheinische Friedrich-Wilhelms-Universität Bonn, Sigmund-Freud-Str. 25, Bonn, 53105, Germany.
BMC Bioinformatics. 2016 Jul 22;17:288. doi: 10.1186/s12859-016-1149-8.
When constructing new biomarker or gene signature scores for time-to-event outcomes, the underlying aims are to develop a discrimination model that helps to predict whether patients have a poor or good prognosis and to identify the most influential variables for this task. In practice, this is often done fitting Cox models. Those are, however, not necessarily optimal with respect to the resulting discriminatory power and are based on restrictive assumptions. We present a combined approach to automatically select and fit sparse discrimination models for potentially high-dimensional survival data based on boosting a smooth version of the concordance index (C-index). Due to this objective function, the resulting prediction models are optimal with respect to their ability to discriminate between patients with longer and shorter survival times. The gradient boosting algorithm is combined with the stability selection approach to enhance and control its variable selection properties.
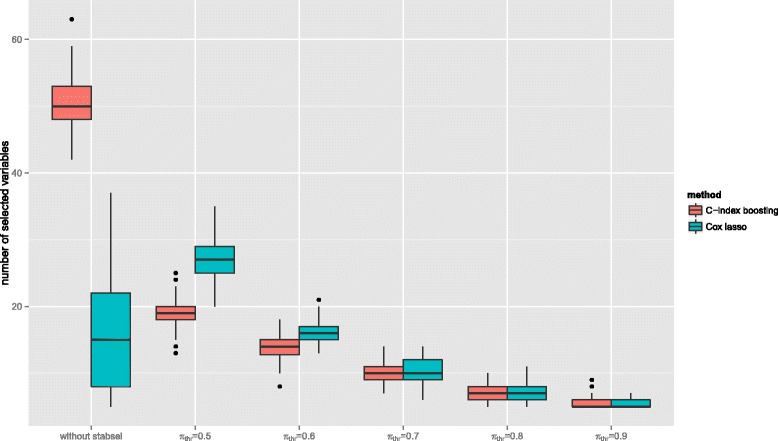
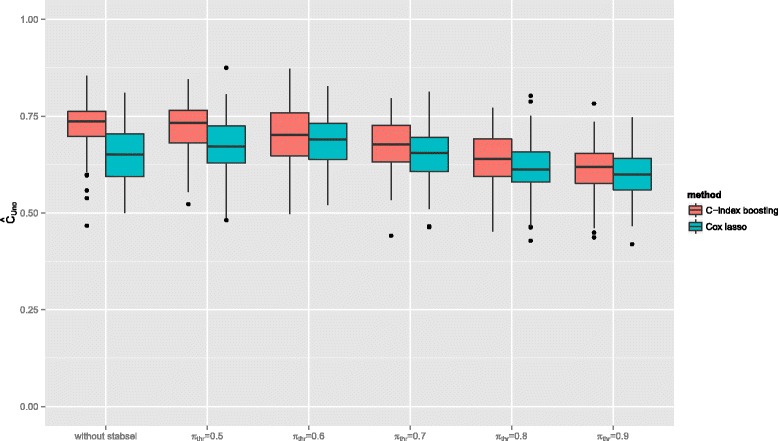
The resulting algorithm fits prediction models based on the rankings of the survival times and automatically selects only the most stable predictors. The performance of the approach, which works best for small numbers of informative predictors, is demonstrated in a large scale simulation study: C-index boosting in combination with stability selection is able to identify a small subset of informative predictors from a much larger set of non-informative ones while controlling the per-family error rate. In an application to discover biomarkers for breast cancer patients based on gene expression data, stability selection yielded sparser models and the resulting discriminatory power was higher than with lasso penalized Cox regression models.
The combination of stability selection and C-index boosting can be used to select small numbers of informative biomarkers and to derive new prediction rules that are optimal with respect to their discriminatory power. Stability selection controls the per-family error rate which makes the new approach also appealing from an inferential point of view, as it provides an alternative to classical hypothesis tests for single predictor effects. Due to the shrinkage and variable selection properties of statistical boosting algorithms, the latter tests are typically unfeasible for prediction models fitted by boosting.
在构建用于事件发生时间结局的新生物标志物或基因特征评分时,其根本目的是开发一种判别模型,以帮助预测患者的预后是差还是好,并识别此任务中最具影响力的变量。在实践中,这通常通过拟合Cox模型来完成。然而,就所得的判别能力而言,这些模型不一定是最优的,并且基于限制性假设。我们提出了一种组合方法,基于对一致性指数(C-index)的平滑版本进行提升,自动选择并拟合用于潜在高维生存数据的稀疏判别模型。由于该目标函数,所得的预测模型在区分生存时间较长和较短的患者的能力方面是最优的。梯度提升算法与稳定性选择方法相结合,以增强和控制其变量选择特性。
所得算法基于生存时间的排名拟合预测模型,并仅自动选择最稳定的预测因子。在大规模模拟研究中证明了该方法的性能,该方法对于少量信息性预测因子效果最佳:C-index提升与稳定性选择相结合,能够从大量非信息性预测因子中识别出一小部分信息性预测因子,同时控制家族误差率。在基于基因表达数据发现乳腺癌患者生物标志物的应用中,稳定性选择产生了更稀疏的模型,并且所得的判别能力高于套索惩罚Cox回归模型。
稳定性选择和C-index提升的组合可用于选择少量信息性生物标志物,并得出在判别能力方面最优的新预测规则。稳定性选择控制家族误差率,这使得新方法从推理角度来看也很有吸引力,因为它为单个预测因子效应的经典假设检验提供了替代方法。由于统计提升算法的收缩和变量选择特性,后一种检验对于通过提升拟合的预测模型通常是不可行的。