Hofner Benjamin, Boccuto Luigi, Göker Markus
Department of Medical Informatics, Biometry and Epidemiology, Friedrich-Alexander-University Erlangen-Nuremberg, Waldstraße 6, Erlangen, 91054, Germany.
Greenwood Genetic Center, 113 Gregor Mendel Circle, Greenwood, 29646, SC, USA.
BMC Bioinformatics. 2015 May 6;16:144. doi: 10.1186/s12859-015-0575-3.
Modern biotechnologies often result in high-dimensional data sets with many more variables than observations (n≪p). These data sets pose new challenges to statistical analysis: Variable selection becomes one of the most important tasks in this setting. Similar challenges arise if in modern data sets from observational studies, e.g., in ecology, where flexible, non-linear models are fitted to high-dimensional data. We assess the recently proposed flexible framework for variable selection called stability selection. By the use of resampling procedures, stability selection adds a finite sample error control to high-dimensional variable selection procedures such as Lasso or boosting. We consider the combination of boosting and stability selection and present results from a detailed simulation study that provide insights into the usefulness of this combination. The interpretation of the used error bounds is elaborated and insights for practical data analysis are given.
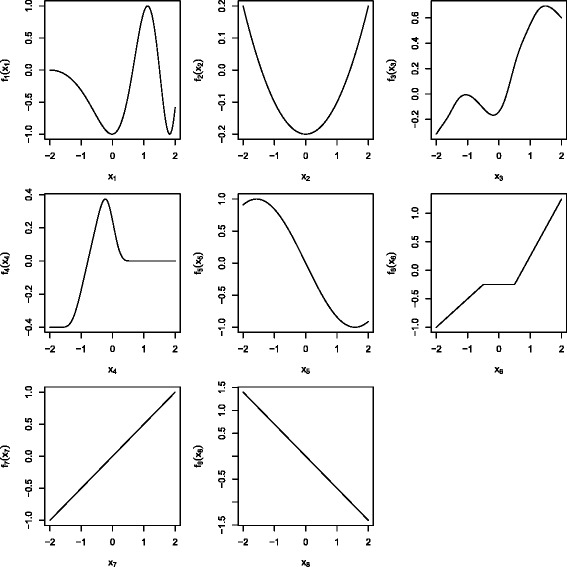
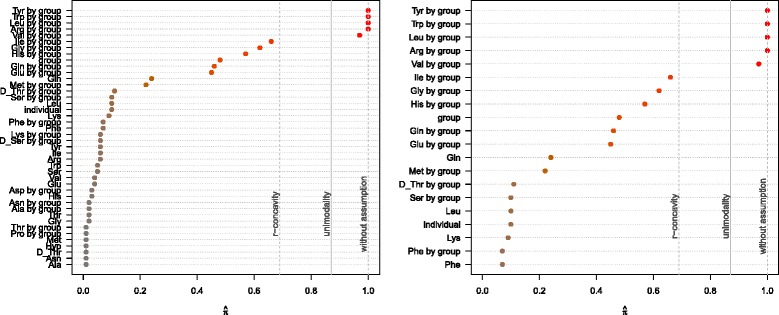
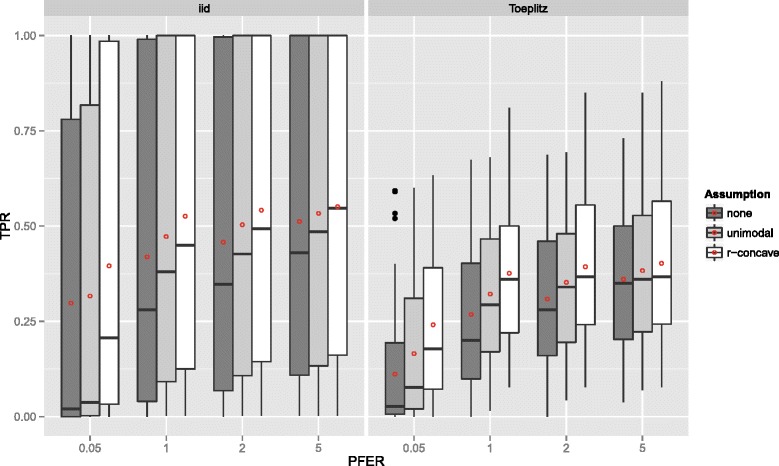
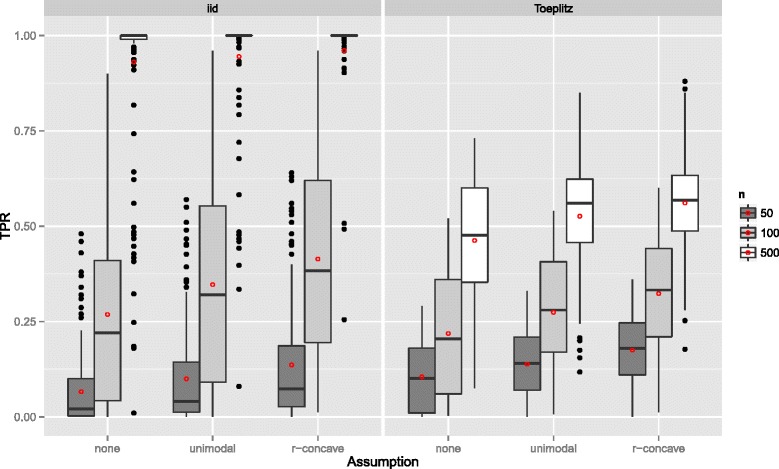
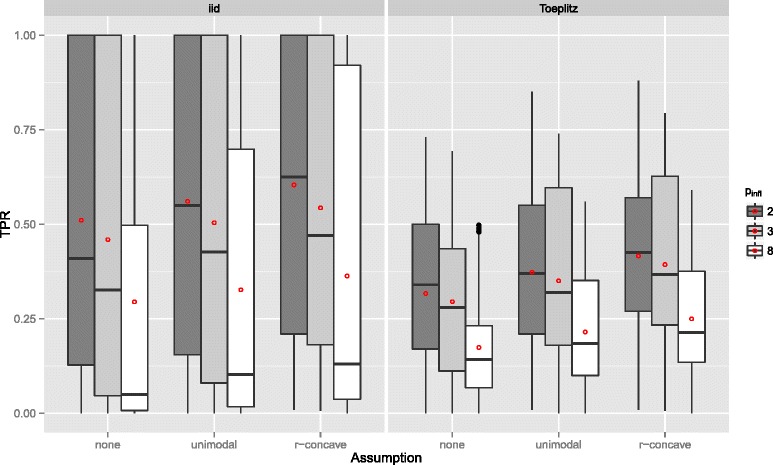
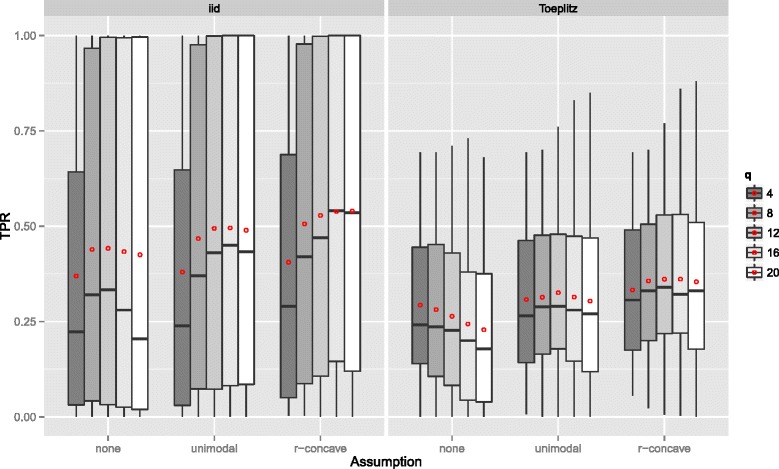
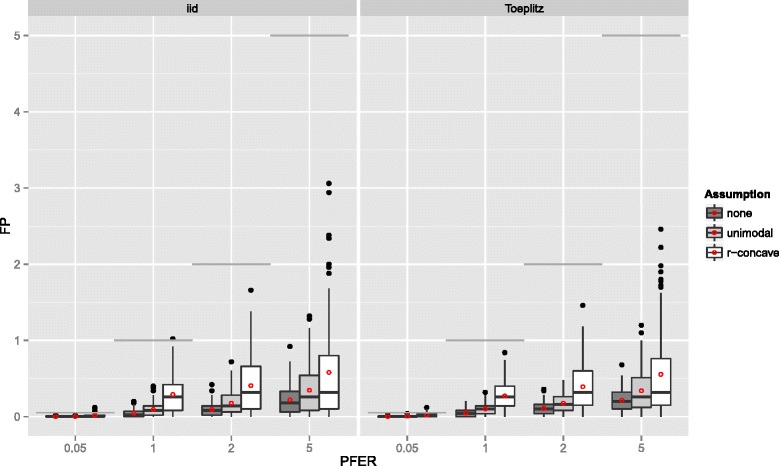
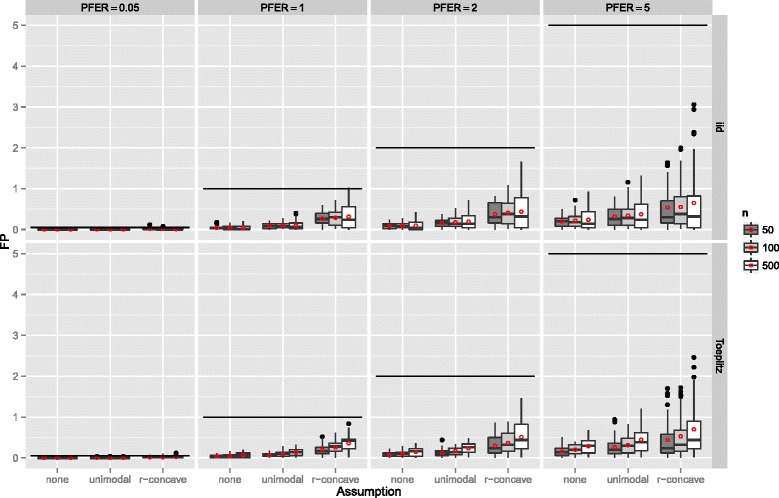
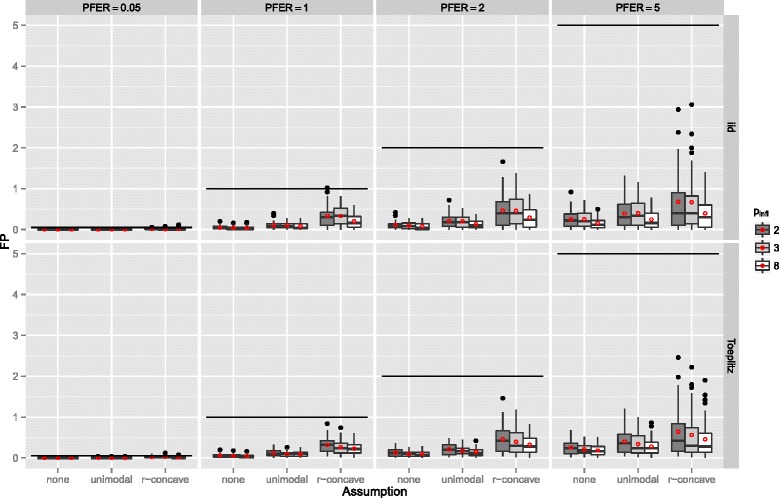
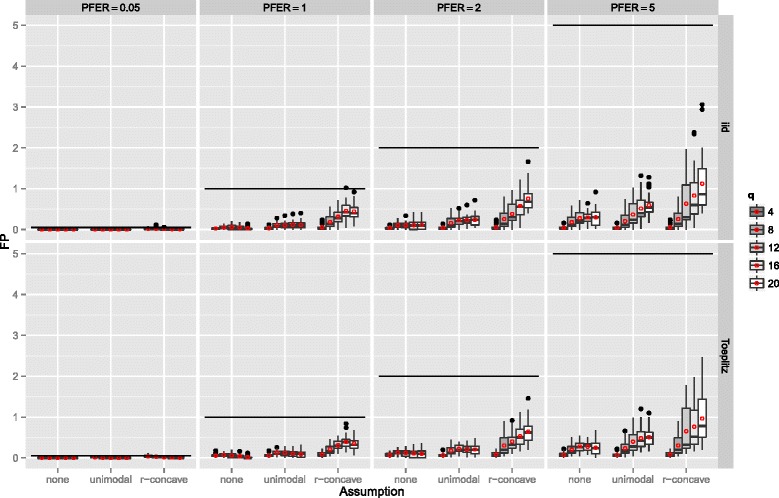
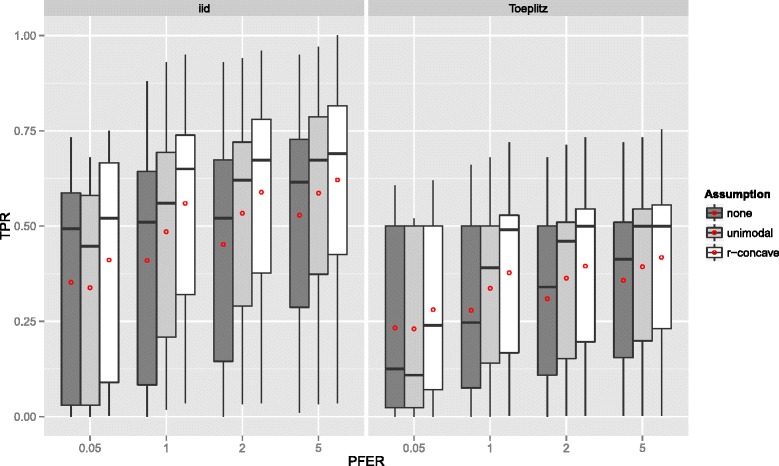
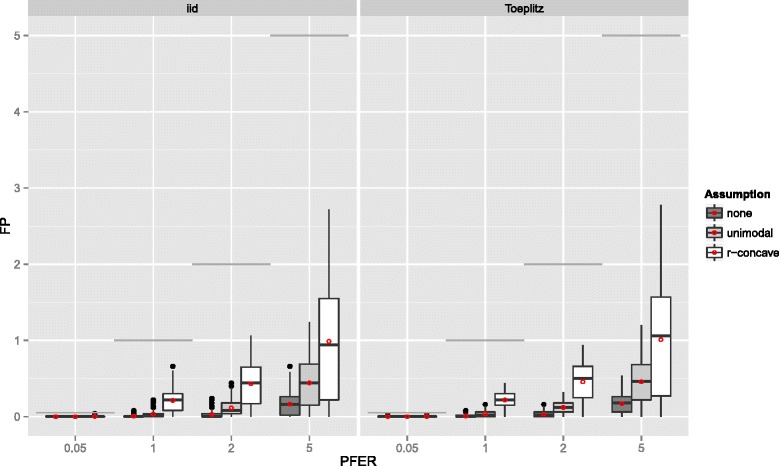
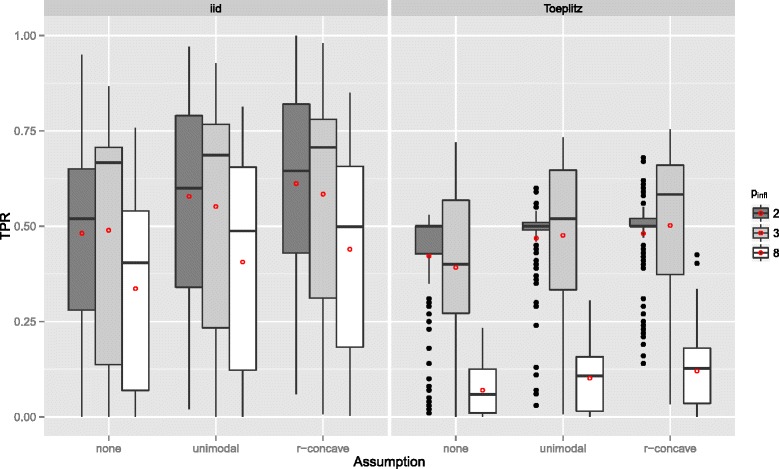
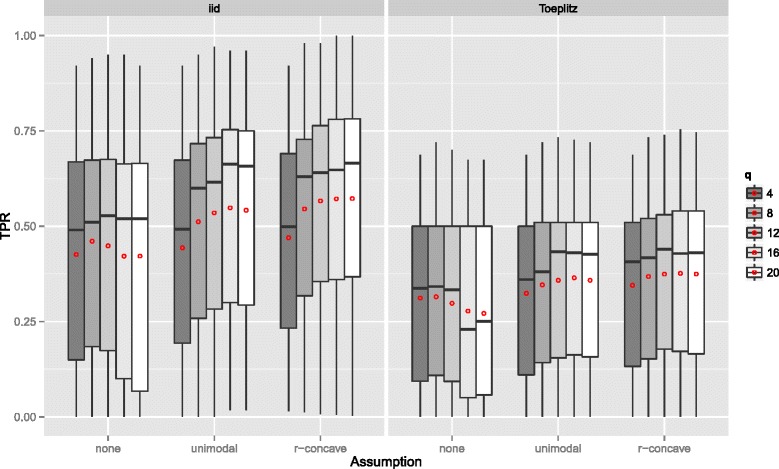
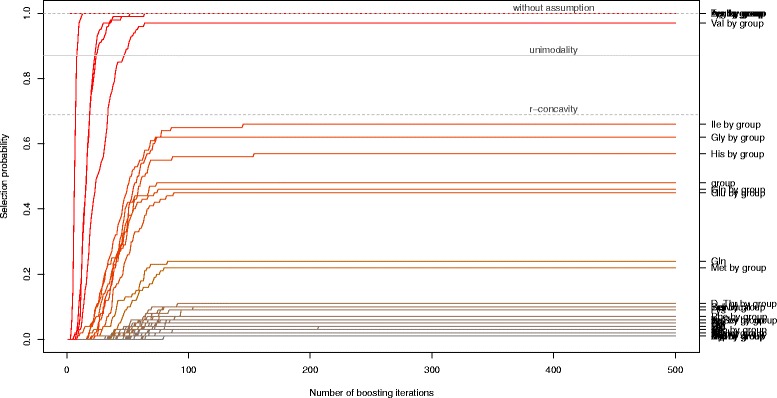
Stability selection with boosting was able to detect influential predictors in high-dimensional settings while controlling the given error bound in various simulation scenarios. The dependence on various parameters such as the sample size, the number of truly influential variables or tuning parameters of the algorithm was investigated. The results were applied to investigate phenotype measurements in patients with autism spectrum disorders using a log-linear interaction model which was fitted by boosting. Stability selection identified five differentially expressed amino acid pathways.
Stability selection is implemented in the freely available R package stabs (http://CRAN.R-project.org/package=stabs). It proved to work well in high-dimensional settings with more predictors than observations for both, linear and additive models. The original version of stability selection, which controls the per-family error rate, is quite conservative, though, this is much less the case for its improvement, complementary pairs stability selection. Nevertheless, care should be taken to appropriately specify the error bound.
现代生物技术常常会产生高维数据集,其中变量的数量远多于观测值(n≪p)。这些数据集给统计分析带来了新的挑战:在这种情况下,变量选择成为最重要的任务之一。在现代观测研究的数据集(例如生态学中的数据集)中,如果要对高维数据拟合灵活的非线性模型,也会出现类似的挑战。我们评估了最近提出的一种名为稳定性选择的灵活变量选择框架。通过使用重采样程序,稳定性选择为诸如套索回归或提升法等高维变量选择程序添加了有限样本误差控制。我们考虑了提升法与稳定性选择的结合,并展示了详细模拟研究的结果,这些结果深入揭示了这种结合的实用性。阐述了所用误差界限的解释,并给出了对实际数据分析的见解。
结合提升法的稳定性选择能够在高维环境中检测出有影响力的预测变量,同时在各种模拟场景中控制给定的误差界限。研究了对各种参数的依赖性,如样本大小、真正有影响力的变量数量或算法的调优参数。研究结果被应用于使用通过提升法拟合的对数线性交互模型来研究自闭症谱系障碍患者的表型测量。稳定性选择识别出了五条差异表达的氨基酸途径。
稳定性选择已在免费的R包stabs(http://CRAN.R-project.org/package=stabs)中实现。它在预测变量多于观测值的高维环境中,无论是线性模型还是加性模型,都被证明效果良好。稳定性选择的原始版本控制的是族错误率,相当保守,不过其改进版本——互补对稳定性选择则并非如此。尽管如此,仍应谨慎适当地指定误差界限。