Henriksson Aron, Zhao Jing, Dalianis Hercules, Boström Henrik
Department of Computer and Systems Sciences, Stockholm University, Borgarfjordsgatan 12, Kista, SE-16407, Sweden.
BMC Med Inform Decis Mak. 2016 Jul 21;16 Suppl 2(Suppl 2):69. doi: 10.1186/s12911-016-0309-0.
Learning deep representations of clinical events based on their distributions in electronic health records has been shown to allow for subsequent training of higher-performing predictive models compared to the use of shallow, count-based representations. The predictive performance may be further improved by utilizing multiple representations of the same events, which can be obtained by, for instance, manipulating the representation learning procedure. The question, however, remains how to make best use of a set of diverse representations of clinical events - modeled in an ensemble of semantic spaces - for the purpose of predictive modeling.
Three different ways of exploiting a set of (ten) distributed representations of four types of clinical events - diagnosis codes, drug codes, measurements, and words in clinical notes - are investigated in a series of experiments using ensembles of randomized trees. Here, the semantic space ensembles are obtained by varying the context window size in the representation learning procedure. The proposed method trains a forest wherein each tree is built from a bootstrap replicate of the training set whose entire original feature set is represented in a randomly selected set of semantic spaces - corresponding to the considered data types - of a given context window size.
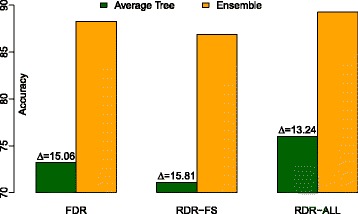
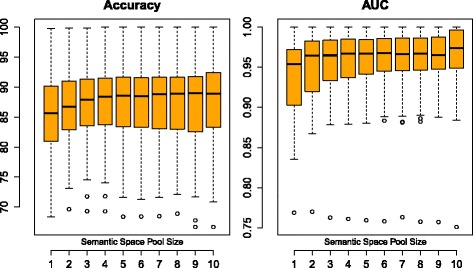
The proposed method significantly outperforms concatenating the multiple representations of the bagged dataset; it also significantly outperforms representing, for each decision tree, only a subset of the features in a randomly selected set of semantic spaces. A follow-up analysis indicates that the proposed method exhibits less diversity while significantly improving average tree performance. It is also shown that the size of the semantic space ensemble has a significant impact on predictive performance and that performance tends to improve as the size increases.
The strategy for utilizing a set of diverse distributed representations of clinical events when constructing ensembles of randomized trees has a significant impact on predictive performance. The most successful strategy - significantly outperforming the considered alternatives - involves randomly sampling distributed representations of the clinical events when building each decision tree in the forest.
与使用基于计数的浅层表示相比,基于临床事件在电子健康记录中的分布来学习其深度表示已被证明能够对更高性能的预测模型进行后续训练。通过利用同一事件的多种表示(例如,通过操纵表示学习过程来获得),预测性能可能会进一步提高。然而,问题仍然在于如何为预测建模的目的,充分利用在语义空间集合中建模的一组不同的临床事件表示。
在一系列使用随机森林的实验中,研究了三种利用四种临床事件(诊断代码、药物代码、测量值和临床笔记中的词汇)的一组(十种)分布式表示的不同方法。在这里,语义空间集合是通过在表示学习过程中改变上下文窗口大小来获得的。所提出的方法训练一个森林,其中每棵树是从训练集的自采样副本构建的,其整个原始特征集在给定上下文窗口大小的一组随机选择的语义空间(对应于所考虑的数据类型)中表示。
所提出的方法显著优于将袋装数据集的多种表示进行拼接;它也显著优于为每个决策树仅在一组随机选择的语义空间中表示特征子集。后续分析表明,所提出的方法在显著提高平均树性能的同时,多样性较低。还表明语义空间集合的大小对预测性能有显著影响,并且性能倾向于随着大小的增加而提高。
在构建随机森林时利用一组不同的临床事件分布式表示的策略对预测性能有显著影响。最成功的策略(显著优于所考虑的替代方法)涉及在构建森林中的每个决策树时随机采样临床事件的分布式表示。