Kensert Alexander, Alvarsson Jonathan, Norinder Ulf, Spjuth Ola
Department of Pharmaceutical Biosciences, Uppsala University, Uppsala, Sweden.
Unit of Toxicology Sciences, Karolinska Institutet, Swetox, Forskargatan 20, SE-15136, Södertälje, Sweden.
J Cheminform. 2018 Oct 11;10(1):49. doi: 10.1186/s13321-018-0304-9.
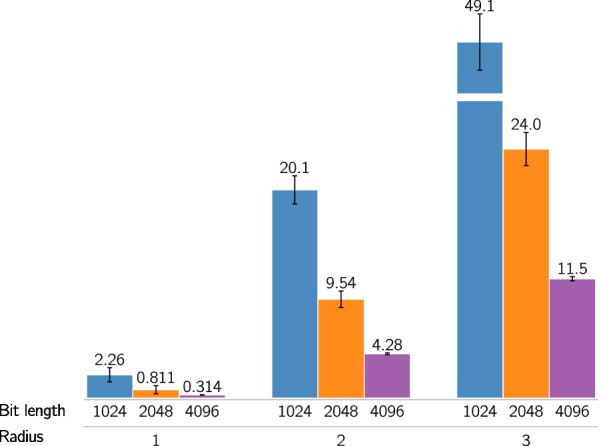
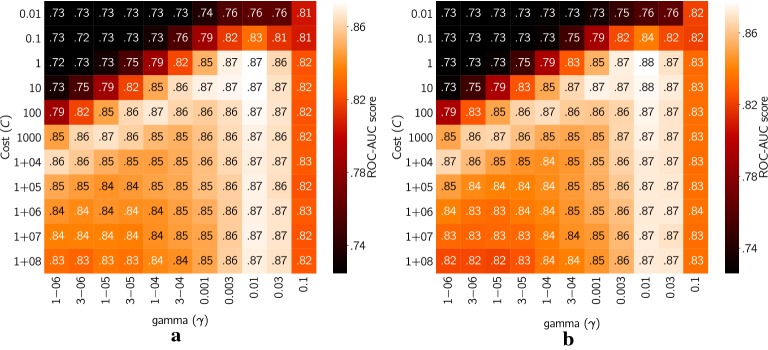
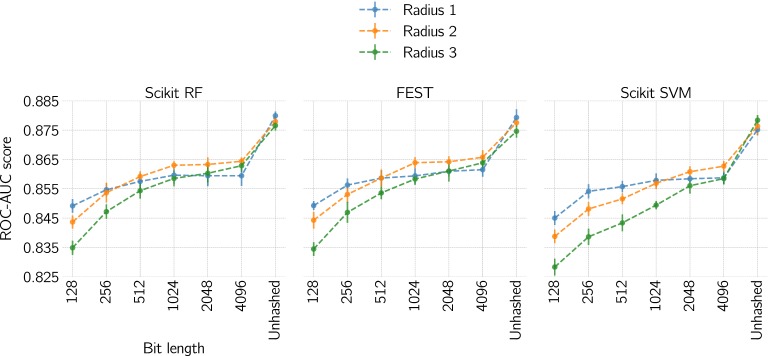
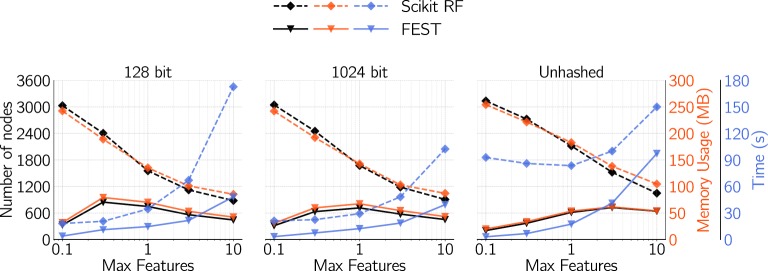
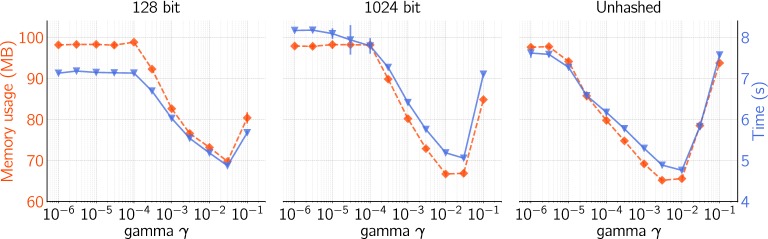
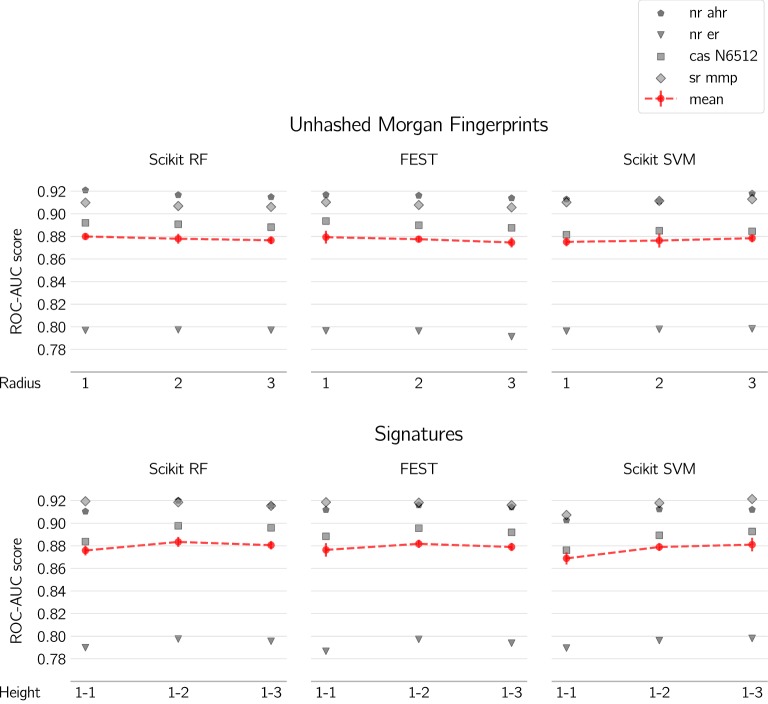
Ligand-based predictive modeling is widely used to generate predictive models aiding decision making in e.g. drug discovery projects. With growing data sets and requirements on low modeling time comes the necessity to analyze data sets efficiently to support rapid and robust modeling. In this study we analyzed four data sets and studied the efficiency of machine learning methods on sparse data structures, utilizing Morgan fingerprints of different radii and hash sizes, and compared with molecular signatures descriptor of different height. We specifically evaluated the effect these parameters had on modeling time, predictive performance, and memory requirements using two implementations of random forest; Scikit-learn as well as FEST. We also compared with a support vector machine implementation. Our results showed that unhashed fingerprints yield significantly better accuracy than hashed fingerprints ([Formula: see text]), with no pronounced deterioration in modeling time and memory usage. Furthermore, the fast execution and low memory usage of the FEST algorithm suggest that it is a good alternative for large, high dimensional sparse data. Both support vector machines and random forest performed equally well but results indicate that the support vector machine was better at using the extra information from larger values of the Morgan fingerprint's radius.
基于配体的预测建模被广泛用于生成预测模型,以辅助例如药物发现项目中的决策。随着数据集的不断增长以及对低建模时间的要求,有必要对数据集进行有效分析,以支持快速且稳健的建模。在本研究中,我们分析了四个数据集,并利用不同半径和哈希大小的摩根指纹研究了机器学习方法在稀疏数据结构上的效率,并与不同高度的分子特征描述符进行了比较。我们使用随机森林的两种实现方式(Scikit-learn以及FEST),特别评估了这些参数对建模时间、预测性能和内存需求的影响。我们还与支持向量机的实现方式进行了比较。我们的结果表明,未哈希的指纹产生的准确率明显高于哈希指纹([公式:见正文]),建模时间和内存使用没有明显恶化。此外,FEST算法的快速执行和低内存使用表明,它是处理大型高维稀疏数据的不错选择。支持向量机和随机森林的表现同样出色,但结果表明,支持向量机在利用摩根指纹较大半径值的额外信息方面表现更好。