Piovesan Nicola, Turi Leo, Toigo Enrico, Martinez Borja, Rossi Michele
Centre Tecnològic de Telecomunicacions de Catalunya (CTTC), Parc Mediterrani de la Tecnologia, Av. Carl Friedrich Gauss, 7, Castelldefels, 08860 Barcelona, Spain.
Department of Information Engineering (DEI), University of Padova, Via Gradenigo 6/B, 35131 Padova, Italy.
Sensors (Basel). 2016 Sep 23;16(10):1575. doi: 10.3390/s16101575.
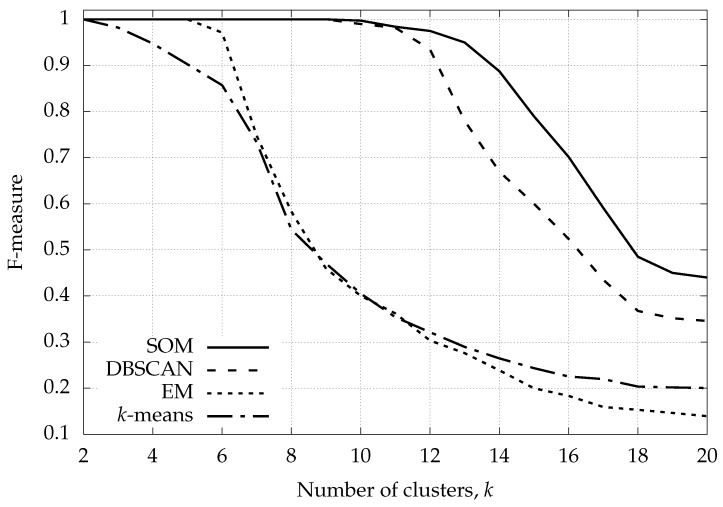
We consider real-life smart parking systems where parking lot occupancy data are collected from field sensor devices and sent to backend servers for further processing and usage for applications. Our objective is to make these data useful to end users, such as parking managers, and, ultimately, to citizens. To this end, we concoct and validate an automated classification algorithm having two objectives: (1) outlier detection: to detect sensors with anomalous behavioral patterns, i.e., outliers; and (2) clustering: to group the parking sensors exhibiting similar patterns into distinct clusters. We first analyze the statistics of real parking data, obtaining suitable simulation models for parking traces. We then consider a simple classification algorithm based on the empirical complementary distribution function of occupancy times and show its limitations. Hence, we design a more sophisticated algorithm exploiting unsupervised learning techniques (self-organizing maps). These are tuned following a supervised approach using our trace generator and are compared against other clustering schemes, namely expectation maximization, k-means clustering and DBSCAN, considering six months of data from a real sensor deployment. Our approach is found to be superior in terms of classification accuracy, while also being capable of identifying all of the outliers in the dataset.
我们考虑的是现实生活中的智能停车系统,其中停车场占用数据从现场传感器设备收集,并发送到后端服务器进行进一步处理和供应用程序使用。我们的目标是使这些数据对终端用户(如停车管理人员)有用,并最终对市民有用。为此,我们构思并验证了一种具有两个目标的自动分类算法:(1)异常值检测:检测具有异常行为模式的传感器,即异常值;(2)聚类:将表现出相似模式的停车传感器分组到不同的集群中。我们首先分析实际停车数据的统计信息,获得适合停车轨迹的模拟模型。然后,我们考虑一种基于占用时间经验互补分布函数的简单分类算法,并展示其局限性。因此,我们设计了一种更复杂的算法,利用无监督学习技术(自组织映射)。这些算法使用我们的轨迹生成器按照监督方法进行调整,并与其他聚类方案(即期望最大化、k均值聚类和DBSCAN)进行比较,考虑了来自实际传感器部署的六个月数据。我们的方法在分类准确性方面被发现更优越,同时还能够识别数据集中的所有异常值。