Mutowo Prudence, Bento A Patrícia, Dedman Nathan, Gaulton Anna, Hersey Anne, Lomax Jane, Overington John P
European Molecular Biology Laboratory, European Bioinformatics Institute (EMBL-EBI), Wellcome Trust Genome Campus, Hinxton, Cambridge, CB10 1SD, UK.
Wellcome Trust Sanger Institute, Wellcome Trust Genome Campus, Hinxton, Cambridge, CB10 1SA, UK.
J Biomed Semantics. 2016 Sep 27;7(1):59. doi: 10.1186/s13326-016-0102-0.
The process of discovering new drugs is a lengthy, time-consuming and expensive process. Modern day drug discovery relies heavily on the rapid identification of novel 'targets', usually proteins that can be modulated by small molecule drugs to cure or minimise the effects of a disease. Of the 20,000 proteins currently reported as comprising the human proteome, just under a quarter of these can potentially be modulated by known small molecules Storing information in curated, actively maintained drug discovery databases can help researchers access current drug discovery information quickly. However with the increase in the amount of data generated from both experimental and in silico efforts, databases can become very large very quickly and information retrieval from them can become a challenge. The development of database tools that facilitate rapid information retrieval is important to keep up with the growth of databases.
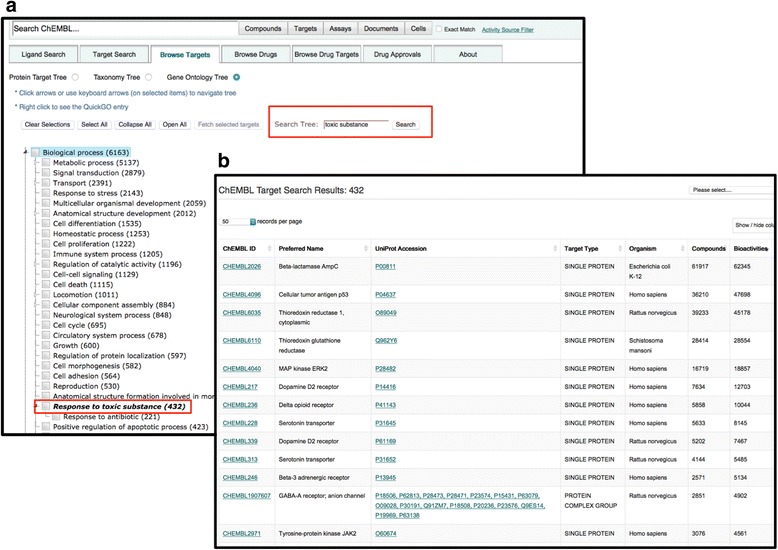
We have developed a Gene Ontology-based navigation tool (Gene Ontology Tree) to help users retrieve biological information to single protein targets in the ChEMBL drug discovery database. 99 % of single protein targets in ChEMBL have at least one GO annotation associated with them. There are 12,500 GO terms associated to 6200 protein targets in the ChEMBL database resulting in a total of 140,000 annotations. The slim we have created, the 'ChEMBL protein target slim' allows broad categorisation of the biology of 90 % of the protein targets using just 300 high level, informative GO terms. We used the GO slim method of assigning fewer higher level GO groupings to numerous very specific lower level terms derived from the GOA to describe a set of GO terms relevant to proteins in ChEMBL. We then used the slim created to provide a web based tool that allows a quick and easy navigation of protein target space. Terms from the GO are used to capture information on protein molecular function, biological process and subcellular localisations. The ChEMBL database also provides compound information for small molecules that have been tested for their effects on these protein targets. The 'ChEMBL protein target slim' provides a means of firstly describing the biology of protein drug targets and secondly allows users to easily establish a connection between biological and chemical information regarding drugs and drug targets in ChEMBL. The 'ChEMBL protein target slim' is available as a browsable 'Gene Ontology Tree' on the ChEMBL site under the browse targets tab ( https://www.ebi.ac.uk/chembl/target/browser ). A ChEMBL protein target slim OBO file containing the GO slim terms pertinent to ChEMBL is available from the GOC website ( http://geneontology.org/page/go-slim-and-subset-guide ).
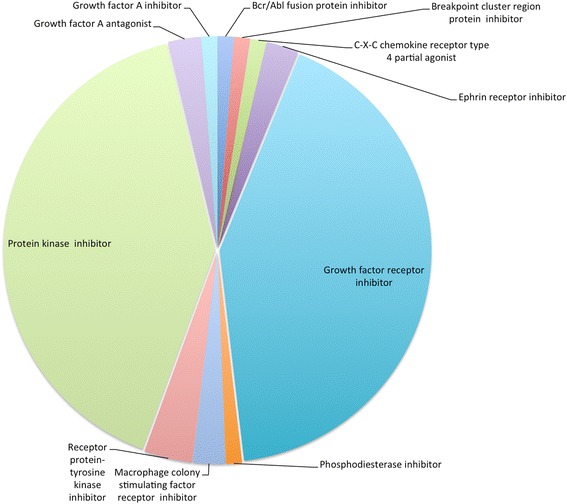
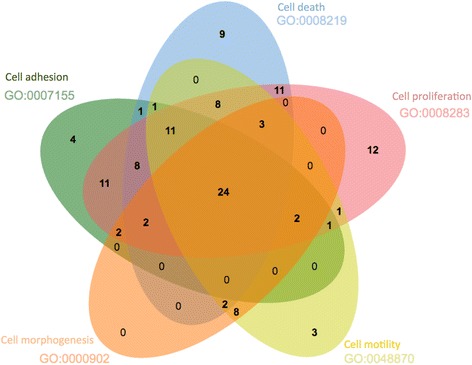
We have created a protein target navigation tool based on the 'ChEMBL protein target slim'. The 'ChEMBL protein target slim' provides a way of browsing protein targets in ChEMBL using high level GO terms that describe the molecular functions, processes and subcellular localisations of protein drug targets in drug discovery. The tool also allows user to establish a link between ontological groupings representing protein target biology to relevant compound information in ChEMBL. We have demonstrated by the use of a simple example how the 'ChEMBL protein target slim' can be used to link biological processes with drug information based on the information in the ChEMBL database. The tool has potential to aid in areas of drug discovery such as drug repurposing studies or drug-disease-protein pathways.
发现新药的过程漫长、耗时且成本高昂。现代药物发现严重依赖于新型“靶点”的快速识别,这些靶点通常是可被小分子药物调节以治愈疾病或减轻疾病影响的蛋白质。在目前报道的构成人类蛋白质组的20000种蛋白质中,只有不到四分之一的蛋白质可能被已知小分子调节。在经过精心策划、积极维护的药物发现数据库中存储信息,有助于研究人员快速获取当前的药物发现信息。然而,随着实验和计算机模拟所产生的数据量不断增加,数据库可能会迅速变得非常庞大,从其中检索信息可能会成为一项挑战。开发便于快速信息检索的数据库工具对于跟上数据库的增长至关重要。
我们开发了一种基于基因本体论的导航工具(基因本体论树),以帮助用户在ChEMBL药物发现数据库中检索针对单个蛋白质靶点的生物学信息。ChEMBL中99%的单个蛋白质靶点至少有一个与之相关的基因本体注释。ChEMBL数据库中有12500个基因本体术语与6200个蛋白质靶点相关,总共产生了140000条注释。我们创建的精简版,即“ChEMBL蛋白质靶点精简版”,仅使用300个高级、信息丰富的基因本体术语,就能对90%的蛋白质靶点的生物学特性进行广泛分类。我们采用基因本体精简方法,为从基因本体注释(GOA)派生的众多非常具体的低级别术语分配较少的高级基因本体分组,以描述一组与ChEMBL中的蛋白质相关的基因本体术语。然后,我们利用创建的精简版提供一个基于网络的工具,该工具允许快速轻松地浏览蛋白质靶点空间。基因本体的术语用于获取有关蛋白质分子功能、生物学过程和亚细胞定位的信息。ChEMBL数据库还提供了已测试其对这些蛋白质靶点作用的小分子的化合物信息。“ChEMBL蛋白质靶点精简版”首先提供了一种描述蛋白质药物靶点生物学特性的方法,其次允许用户轻松建立ChEMBL中关于药物和药物靶点的生物学信息与化学信息之间的联系。“ChEMBL蛋白质靶点精简版”可在ChEMBL网站的浏览靶点标签下(https://www.ebi.ac.uk/chembl/target/browser)作为可浏览的“基因本体论树”获取。一个包含与ChEMBL相关的基因本体精简术语的ChEMBL蛋白质靶点精简版OBO文件可从基因本体联盟网站(http://geneontology.org/page/go-slim-and-subset-guide)获取。
我们基于“ChEMBL蛋白质靶点精简版”创建了一个蛋白质靶点导航工具。“ChEMBL蛋白质靶点精简版”提供了一种使用高级基因本体术语浏览ChEMBL中蛋白质靶点的方法,这些术语描述了药物发现中蛋白质药物靶点的分子功能、过程和亚细胞定位。该工具还允许用户在代表蛋白质靶点生物学的本体分组与ChEMBL中相关的化合物信息之间建立联系。我们通过一个简单的例子展示了如何基于ChEMBL数据库中的信息,使用“ChEMBL蛋白质靶点精简版”将生物学过程与药物信息联系起来。该工具在药物发现领域,如药物再利用研究或药物 - 疾病 - 蛋白质途径方面具有潜在的辅助作用。